

Database Change Management Best
Practices:
Achieving an Automated Approach and Version
Control
Part 2
In part 1 of this series, Darren Fuller discussed the need for database change management and problems with current approaches e.g. the manual creation of upgrade scripts, which is inefficient and error prone. In this second article of a 4 part series, he examines an automated approach to database change management and outlines the essential elements of an automated methodology.
What is an Automated Methodology?
If you participate in a project that involves database development, a crucial element of a project’s success, is the accurate propagation and deployment of the database code and schema changes. Often, an unnecessarily large proportion of highly-skilled resource is required for this aspect of the project. Once the analysis and design has been completed, the deployment of the changes, while critical, is quite laborious and repetitive. Therefore, it is highly recommended to systematise or automate these tasks.
An automated methodology is a complete end-to-end solution for database change management and version control, which will minimise human intervention for tasks that are repetitive, time-consuming and error-prone. This process is enabled by an application called the “change control tool”.
Elements of an Automated Approach
The following outlines the basic elements required to achieve an automated approach.
Local Development Database
There are two choices here:
- to have a single development database that all developers use, or;
- each developer has their own copy of the development database
The latter is recommended as it provides each developer with an isolated workspace that cannot be changed by another developer. Typically, each developer would have a cut-down extract of the production system on their desktop. How do the developers keep their local databases up to date? An automated methodology provides the ability for each developer to incorporate all other developer's changes on their local database and then unit test their changes.
Integration with Version Control System (VCS)
Most IT departments utilise the critical functionality of a VCS to maintain and track changes to source code. It is quite a common practice for developers to store new and amended code and components for languages such as VB, C++, C#, ASP, HTML, Java and XML. But what about the SQL source code and objects which are resident in the database system? It is recommended to store all SQL objects within a VCS, thus enabling automated versioning of the database.
Building the Source Structure
To implement an automated methodology, all SQL code and schema definitions must first be reverse-engineered and lodged into a VCS (a one-off task per system) usually with a separate folder for each object. An automated approach facilitates the extraction of DDL and SQL code and the creation of the appropriate source structure.
Figure 1: Example Directory Structure for SQL Objects in VCS
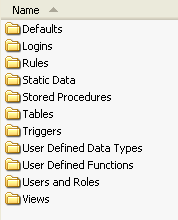
Static Data
The commands to insert static data (reference tables) are also lodged into a VCS. These commands can be generated by a stored procedure or the “change control tool” to create an insert statement for each row within your static data tables. Automation simplifies the generation of static data insert commands.
Build Environment
A “build” environment is configured containing a database which is a replica of the production database. An hourly (or daily) compile and build of all SQL objects is run as a scheduled task. This facilitates a proactive approach to verification.
Custom Scripts
As with any complex database system and the applications it supports, not all situations can be covered and will need intervention. On rare occasions, a scenario arises which is ambiguous and the change control process has to guess as to what is required. For example, if a new table schema requires a rename of a column, the decision might be made to drop the column and all existing data – something you may not want to happen.
There are other situations in which the process would simply not know what is required e.g. data is required for a newly created column. In these cases, the automated approach would provide the ability to execute ad hoc custom scripts. For example, for new column data, you would create a script to insert
the new data.
Then have the automated process call this script after changes have been made to your database.
Change Control Tool
At the centre of an automated methodology is the “change control tool.” This is the software that automates database propagation and deployment by performing such tasks as generation of the SQL commands necessary to move a database to the desired version. Key features of such a tool would include:
- ability to run in user mode (wizard-based) or auto mode (command-line execution) for automated scheduling
- integration with a version control system e.g. Visual Source Safe
- schema and data comparison and synchronisation
- build a new database from a set of object creation scripts hence verifying code
- compare a database to a set of object creation scripts and perform an upgrade of the database
- object dependency resolution – algorithms to ensure objects are built in the correct order and relationships are maintained e.g. defaults bound to columns, DRI and circular relationships
- identify and report all differences and errors
- automatic generation of SQL change scripts for schema and data
- capability to reverse-engineer existing databases
- session-save facility
- ad hoc custom script execution
- ability to compare all database objects and properties
Next Article
In part 3 of this series, I will outline the requirements to implement an automated approach to database change management and highlight some of the benefits.
About the Author
Darren Fuller began his IT career in 1990. Much of his experience has been gained by providing database consultancy on mission-critical systems and development projects within large organisations, often within heterogeneous environments using multiple technologies. Darren has specialised in database technologies with a particular interest in troubleshooting, optimisation and tuning, especially with Microsoft SQL Server (since 1994). He has a passion for ensuring a database system is finely tuned and the processes within a development project help to achieve this aim in an efficient and cost-effective manner.
Darren holds a Bachelor of Business in Computing and a Microsoft MCSE certification. He welcomes any feedback and can be contacted at darren.fuller@innovartis.co.uk
© Copyright Innovartis Ltd 2004. All rights reserved.
