

This is the fifth article in a series on the basics of using Git. The other articles in the series are:
- Basic Git for DBAs: Getting Started with Git
- Basic Git for DBAs: Sharing Files Through GitHub
- Basic Git for DBAs: the Basics of Branches
- Basic Git for DBAs: Making Changes in GitHub
- Basic Git for DBAs: Merging Code Between Branches
- Basic Git for DBAs: What's a Pull Request?
- Basic Git for DBAs: Managing PowerShell Scripts
- Basic Git for DBAs: Ignoring Files and Customizing Your Environment
In the previous articles, we set up a repository and shared files through GitHub and created copies, called branches. In this article, we will look at how to merge code, or move changes from one branch to another.
The Branch Base
At the end of the third article, one of the challenges was to create a new branch based on master. We didn't do that, but we'll do that now so that we can explain a concept and also give us a few ways to merge code.
When I create a branch, I am creating a copy at that point in time. The copy is based on my current branch, not on master/main, or any other branch. In other words, the current view of code in my file system is the basis for the copy in the branch. When I branched the code in the third article, I named my branch feature-spBlitz. The current state of this branch is shown in SourceTree. Note the feature-spBlitz branch is highlighted on the left, meaning it is selected.
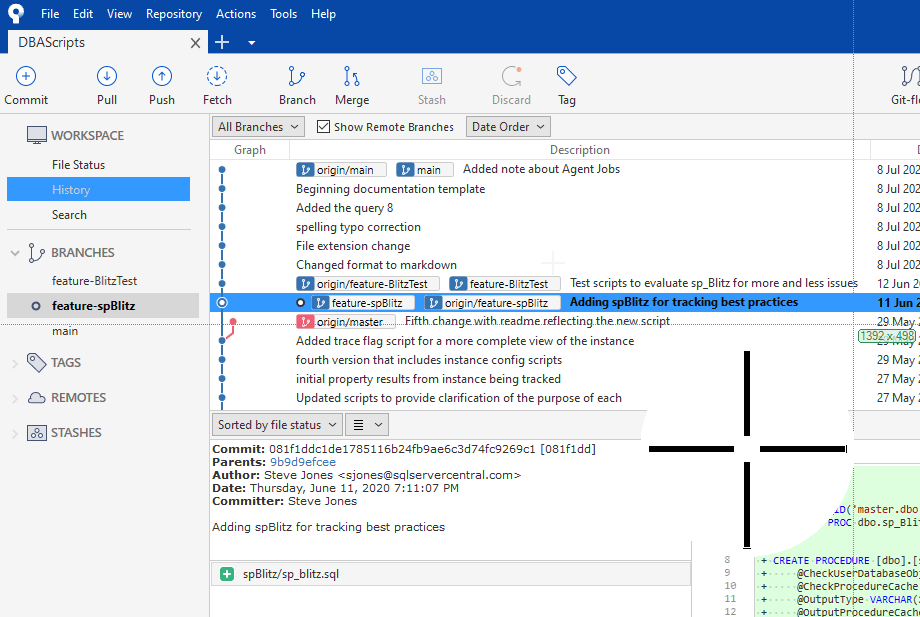
The graph shows that this branch is behind the main branch. The current tags for main and origin/main are at the top of the graph. feature-spBlitz is below that. There are 7 commits in main
I can see this by selecting the main branch on the left. When I do that, I see three files in a Windows Explorer window. These represent the current state of this branch.
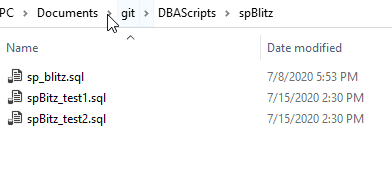
If I change back to the feature-spBlitz branch (either double click or with git checkout in the command line), I see only 1 file.
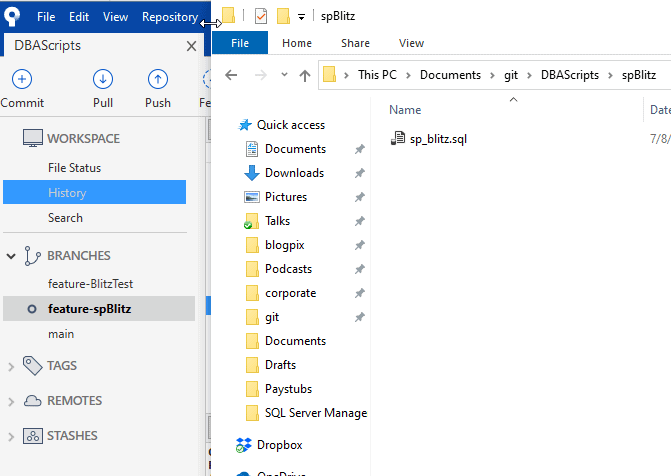
In this case, the main branch has advanced past the feature branch that I am working on. How do I get these changes into my branch? After all, before I send my code to others, I should be sure it works with their code.
Merging Code
The opposite of branching is merging. Branching is making a copy of code. Merging is bringing differences from a copy into this set of code. In this case, I would like to merge the future changes from the main branch into the feature-spBlitz branch.
If I look in SourceTree, I see a Merge button at the top. If I click this, I get a new dialog, which looks busy, but it actually a not too complex. This shows me another view of the commit graph, comment, and other metadata. I also see a few options at the bottom.
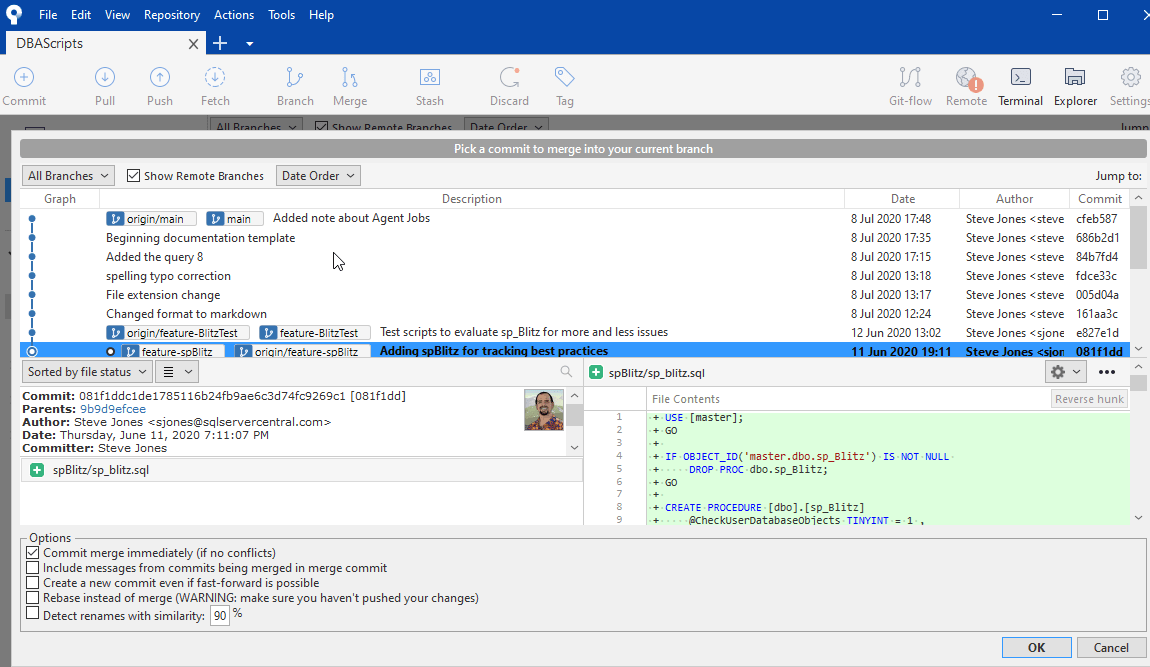
The key here is at the top of the dialog in a light gray color. This dialog asks me to pick a commit to merge. The default selection is the current place in the graph for this branch. There's nothing to merge here. However, if I click up one line, I am at the current commit for the feature-BlitzText branch. I then see this dialog, with two files added in this commit:
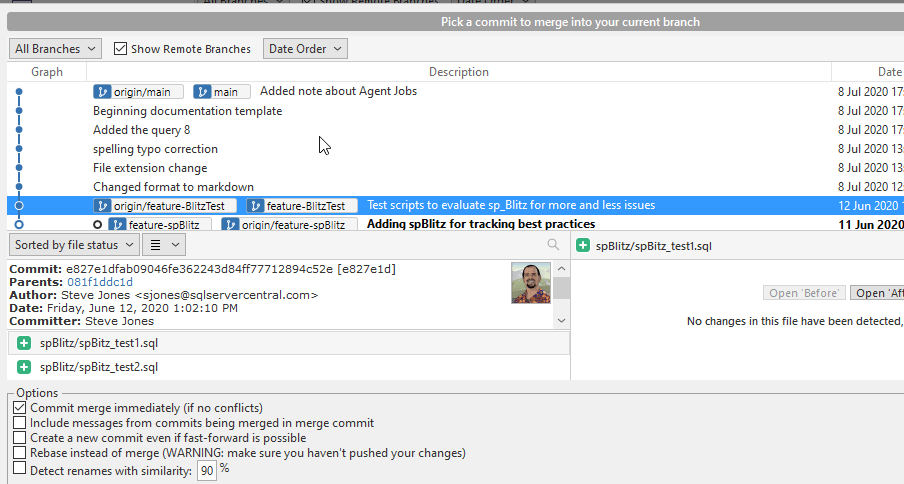
In this case there are no conflicting changes, so just two new files would be added to my branch, copies of spBlitz_test1.sql and spBlitz_test2.sql. In the options, I can just have this take place if there are no conflicts. We'll discuss conflicts in a moment, but essentially, if this does not break any code, I can do this. I can also change how the commit comments are handled.
The simplest thing to do here is just click the OK button at the bottom. This will merge (bring) these two changes into my copy of the code. Alternatively, I could pick any other commit above this and see the changes in that commit, but I have to remember that all changes between my current copy and that one are included in the merge.
I'll click OK here, and the merge completes without error because there are no conflicts. I now see this view, where the feature-spBlitz branch is at the same level as the feature-BlitzTest. Note, the origin/feature-spBlitz is still behind because I have not pushed my changes to that remote.
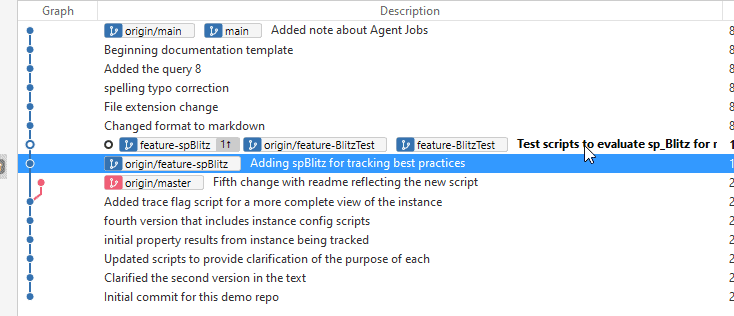
I also see three files in Windows Explorer now, as the changes that included these files are merged into this copy of the code.
If I click Merge again and move to the top of the graph, where the main branch is, I can merge this code in. When I do that, the branch status has changed to the top. I also see 7 changes stacked up that haven't been pushed on the "Push" button.
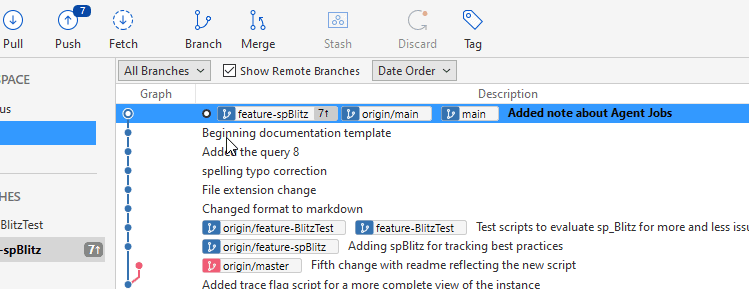
Here I've pulled in all the code changes that were made in master into my copy. If I switch branches now to main, the view in Explorer will remain the same. All my changes, from the rename of the extension for the readme file to the text changes inside to the new "docs" folder have been made in the files.
This was a basic, simple merge from main to my branch. I typically do this when I want to ensure that I have all the changes others have made so I can test them. This helps me to ensure any changes I've made won't cause problems with other people's code.
However, this doesn't cover more complex scenarios, such as when there are conflicts in code or there are divergent changes. Let's set up a different scenario.
Diverging Changes
I'm going to make a few different changes. First, I'll add a new folder for tables in the main branch add a couple files.
I'll now add a Views folder locally, which will have a file in it. When I get done, my local Explorer looks like this:
My graph now looks different, with my local copy ahead of the main branch, but also these two have diverged. No longer does one have additional things. There are now differences. This is reflected in the graphs having two separate paths, as shown below.
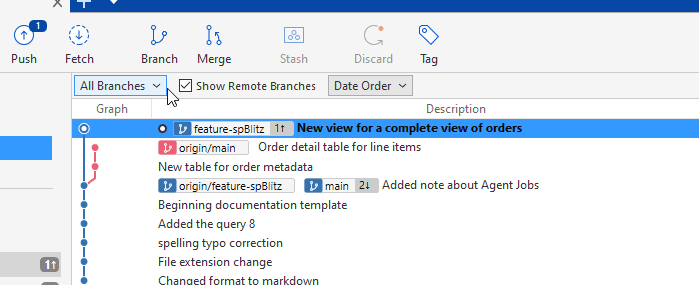
The differences are:
- feature-spBlitz - Has a views folder and a file in there.
- main - Has a Tables folder and two files in there.
These are both separate changes, which need to be merged. This is different from the previous view where everything was the same, with changes or additions in one branch. If I add a "Stored Procedures" folder to the feature-BlitzText branch and pull, we see more divergence in the graph, with 3 paths. One is blue, one red, and one is green.
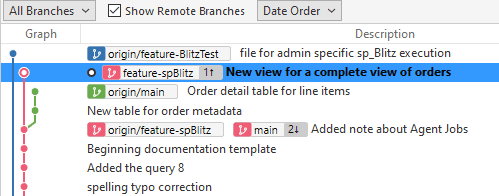
I'm sure you can imagine that trying to keep track of multiple branches and sort out differences can be complex. Here it is simple, because each branch has made changes that do not impact the others. Each change is in a separate folder.
I'll merge these changes, which is a good exercise for you, and get my feature branch complete with all code changes. When I do this, I see my branch has convergence from the others, even though those branches are still at separate places..
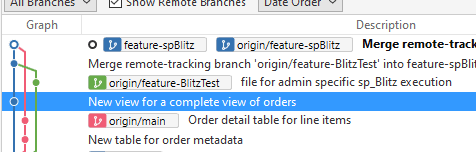
This typically isn't the end flow, as we usually try to get all changes into the main branch, or whatever branch is the basis for all developers to work from.
These merges were simple as none of them conflict. What happens with conflicts? Let's see that next.
Conflicting Changes
What is a conflict? This is when there are changes to a file that cannot easily be reconciled by the version control system. We usually call these merge conflicts, and they can be difficult to resolve. Let's look at one.
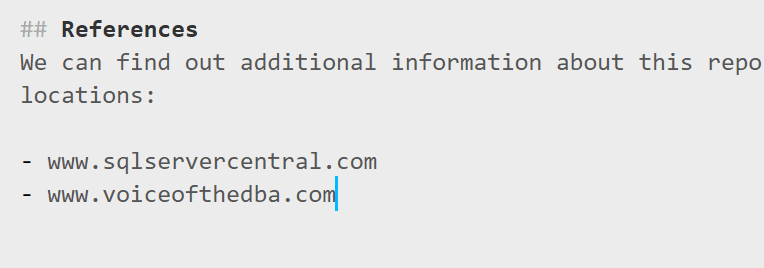
In my branch, I'm going to change the readme.md in the root to include a References section with this information.
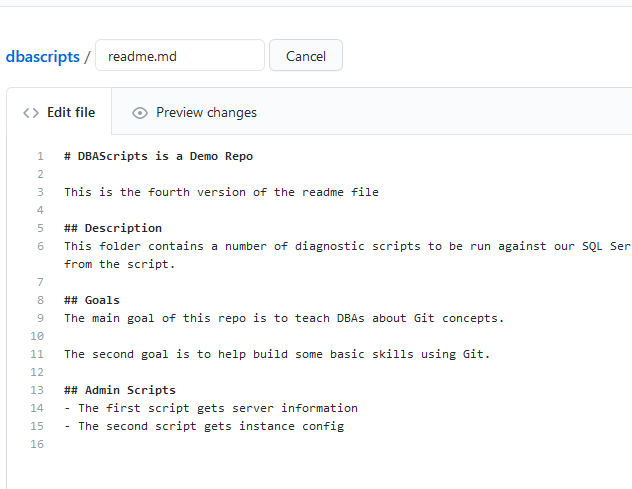
I'll also go to GitHub and add a Goals section to readme.md in the main branch. This is the file in the main branch.
Let's now pull the main branch locally and then view the graph. We see the divergent branches, but we don't know there are conflicts.
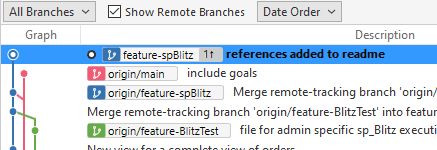
Let's attempt to merge. I click merge and attempt to merge the origin/main branch into my feature-spBlitz branch. The merge dialog doesn't show any conflicts, so I'll click OK.
When I do this, things seem to complete. I see a new commit with the "Merge branch main into feature-spBlitz" message, and things look OK. No errors. If I look in the readme.md file, I see this for the contents. All four sections are present.
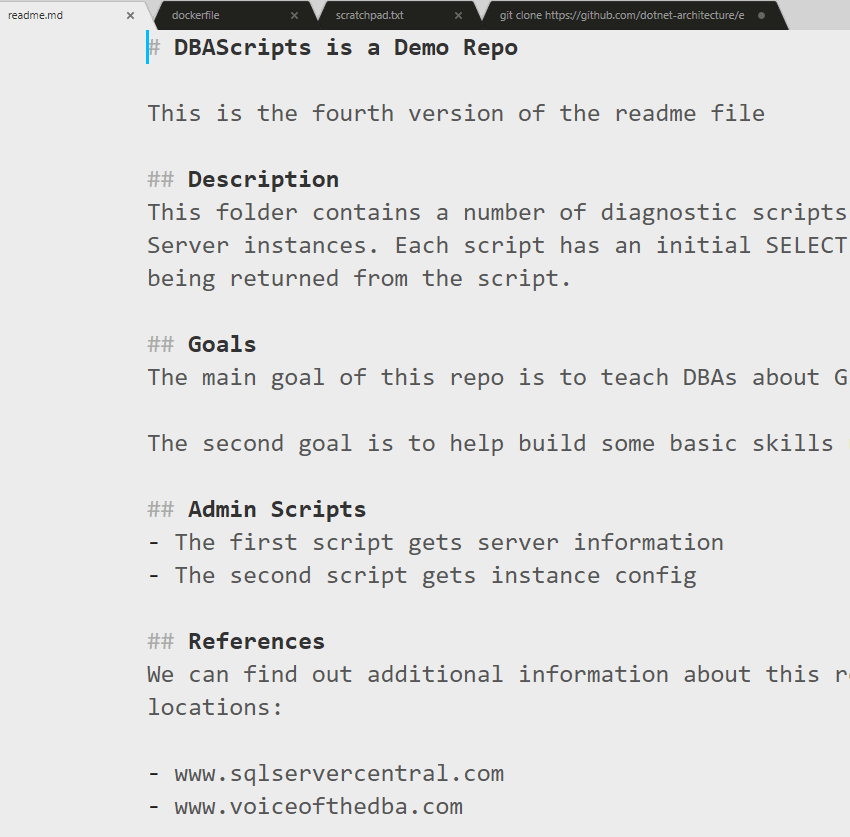
If we treat the changes made to my local branch and the online main branch as those made by two people, why wasn't there a conflict? Well, a VCS works line by line, and in this case, there weren't changes made to conflicting lines. Each "developer" added code in different places, so Git merged these together. Easy, right?
This may or may not work well. This works with text more easily than code, so let's make two more changes. Now that there is a Tables folder in both branches, let's make some conflicting changes. First, I'll add a column to the main branch to track tax amounts.

In my local branch, I'll add a different column. I'll choose a shipping date for my table. Note this is the type of change that can easily happen when two developers are working on separate items and do not communicate. This could certainly happen in SSMS on a shared database, where each user could add a column to a table and not realize the other user had added a column.
Here I see my commit in SourceTree
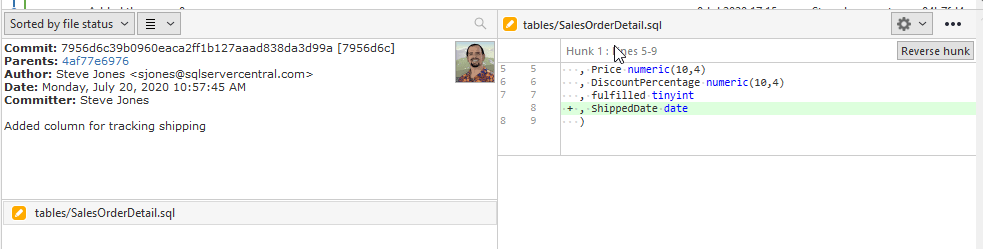
If I fetch (pull) the master branch, I can also see this branch is ahead in the graph and has a different column at the end of the table.
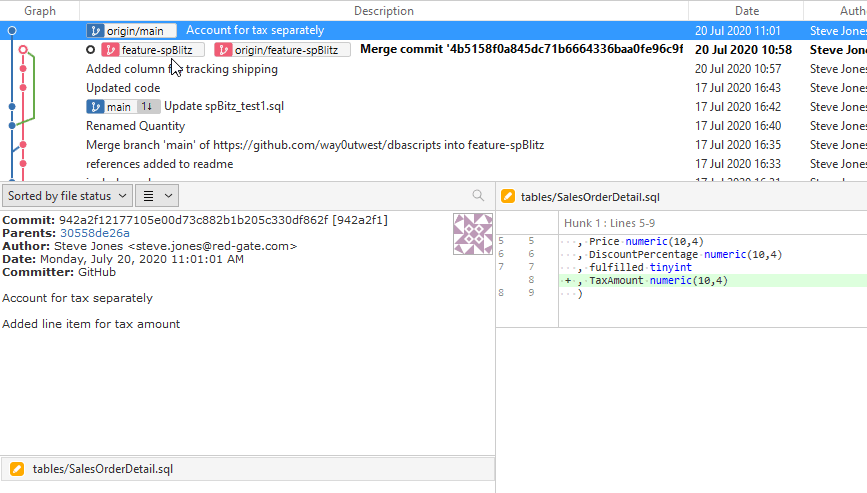
Let's not try to merge the code from main into feature-spBlitz. When I click merge, I see the normal merge, with the change from the main branch.
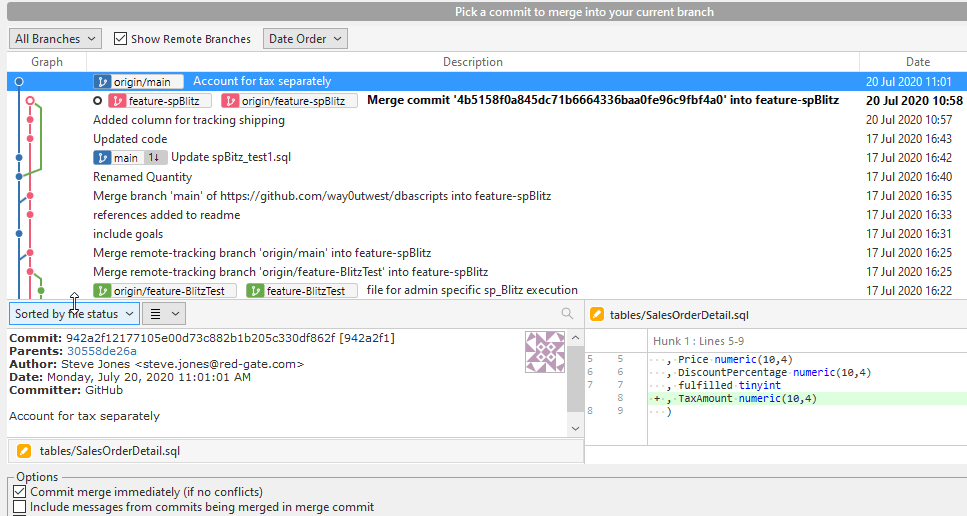
If I click OK, I get this message. This tells me I have conflicting changes in the files. I get this because the changes are on the same line in both files.
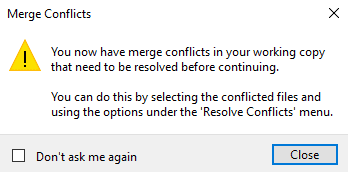
My SourceTree now looks like this, with uncommitted changes. I'm in the process of merging things, and I need to abort or complete this.
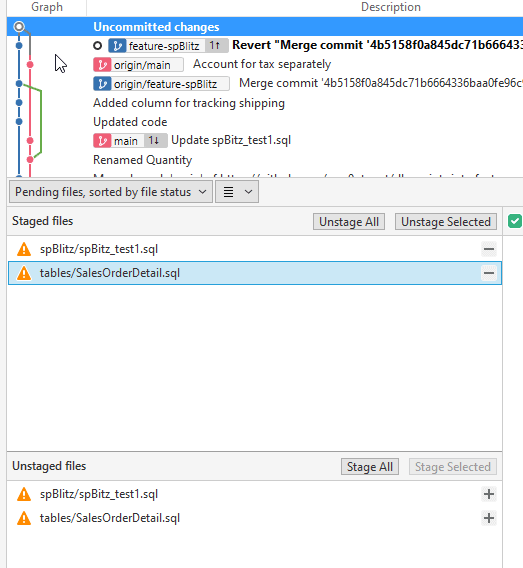
The message noted I could use the Actions menu and Resolve Conflicts. Here are the choices in that menu.
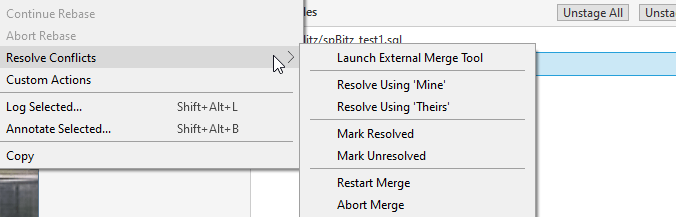
I can abort or restart things. I can also resolve using mine or theirs. These mean I would take the changes in my branch (mine) or the changes in the other branch (theirs) and overwrite the code to look like that version. This is essentially the "last writer wins" scenario, but I am choosing who the last writer is. I can also launch an external merge tool.
I haven't configured one, so for now, I'll open the file up in SSMS. I see this view, with some annotation from git on the merge issues.
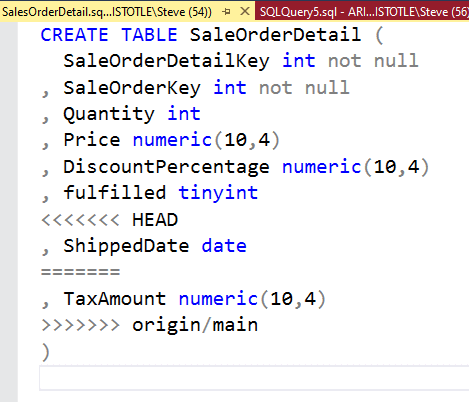
The text that has "<<<<<< HEAD" is above my code. This would be the "mine" choice. The lower bound to my code is the "=======" line. Below that, and above the ">>>>>> origin/main" is the code from the other branch, the "theirs" code.
What I need to do is edit this to decide how to commit the code. In my case, I can put my column before or after the TaxAmount column from the main branch. I could also just remove my code if I wanted. While I could remove the other code, this is in main, and I should consider this as a higher priority to my code, as likely someone has reviewed it.
I'll edit my code so that it looks like this. Note that I have removed the git annotations.
CREATE TABLE SaleOrderDetail ( SaleOrderDetailKey int not null , SaleOrderKey int not null , Quantity int , Price numeric(10,4) , DiscountPercentage numeric(10,4) , fulfilled tinyint , TaxAmount numeric(10,4) , ShippedDate date )
I essentially assumed the TaxAmount column was added first, and then added mine after it. I save this and I can now mark the Merge as resolved.
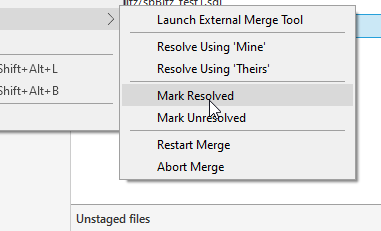
I can then go to the commit dialog and complete this commit, of which a merge is a new commit.
Note: you might see that I had a second file in here. I was experimenting with some other code that created a conflict, which I resolved in a similar manner.
This is a basic example of how to resolve conflicts in your merged code.
Conclusion
This post covered a lot of ground on merging changes. I tried to give you a basic look at how to merge code that is unrelated to work you've done, or before you've done work. We also looked a couple cases of merging code in the same file. Some of these just merge, some do not. We did look at a basic resolution for a conflicting change, but this is very basic. There is more to cover here.
One thing we didn't discuss is changes in different sections of a file that might affect the way the code works. For example, a change at the beginning of a stored procedure might affect the logic later in the procedure, and git will not detect this. All changes need to be re-tested after a merge, which is something that Continuous Integration helps to do.
In the next article, I'll look at pull requests, which are one way to ensure that another person can review your changes and give you feedback.