

Introduction
Azure Synapse Analytics is a Powerful analytics tools which combines data warehousing and big data analytics together. Azure Synapse provides two types of SQL Pool - Serverless and Dedicated. The dedicated SQL pool is designed for high performance analytics work, it can process large amount of data and complex queries. You can create and configure dedicated SQL pool based on your business needs. While creating a Synapse Workspace a Serverless SQL pool is automatically created. The Serverless SQL is always available and running in the workspace. In this article we will focus on Serverless pool. I will explain about reading data from an external storage and store the result set in a table.
Read Data from External Storage
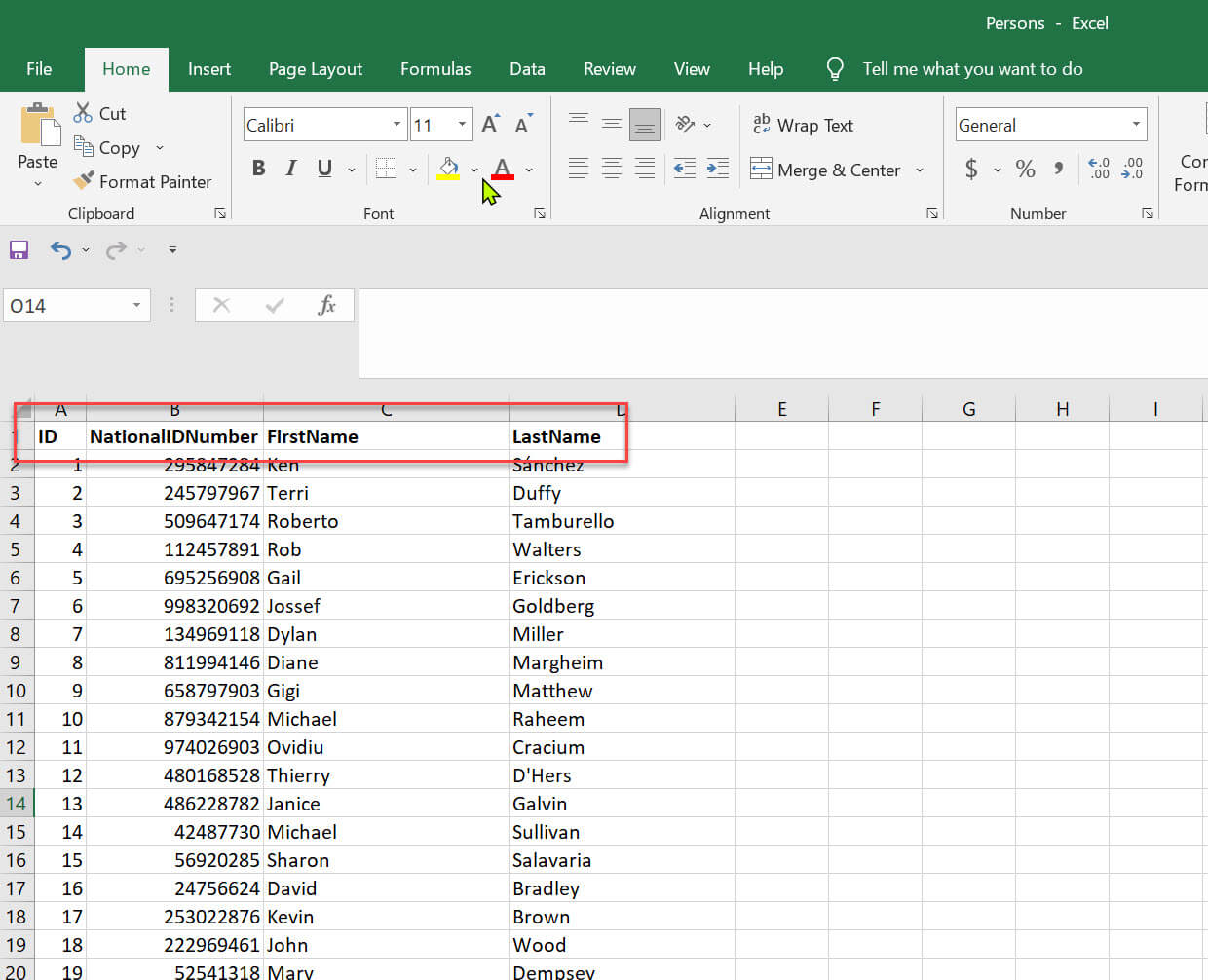
I will use a sample csv file. It has four columns ID , NationalIDNumber , FirstName and LastName:
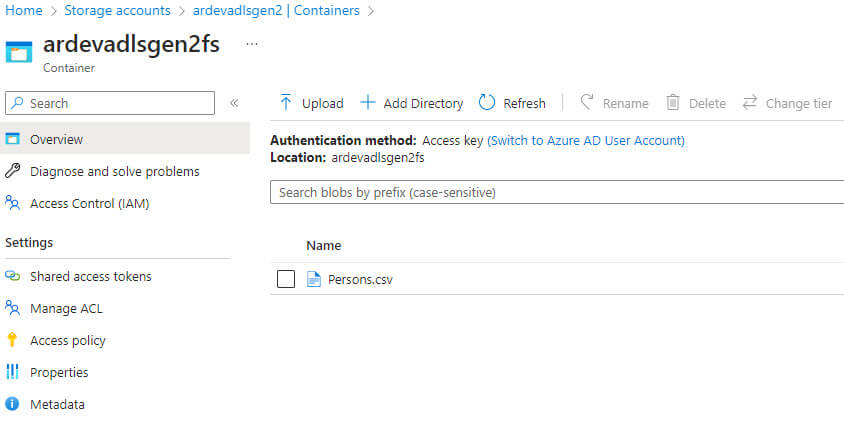
I copied the file in the Azure Data Lake Storage folder:
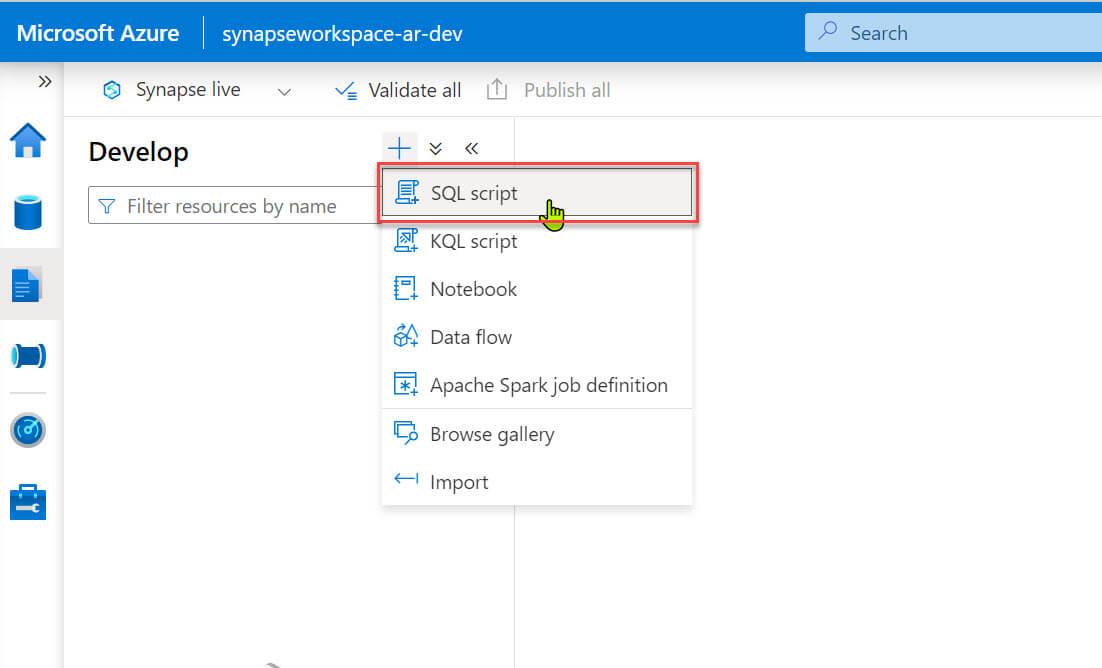
In the Synapse workspace create a new SQL script from the develop section:
I am used below query to read the data from the csv file. We can read files in ADLS using the OPENROWSET function. The OPENROWSET function reads content of a file and returns the data as a set of rows. It requires below inputs:
- bulk : Openrowset accepts data source that contains file or can be used with a URL for file location with BULK option.
- format : three types of input files supported currently - 'csv' , 'parquet' and 'delta'.
- parser_version : default value is '2.0'.
- header_row : specify true or false.
The result showing the data from the csv file:

Store query results in an external table
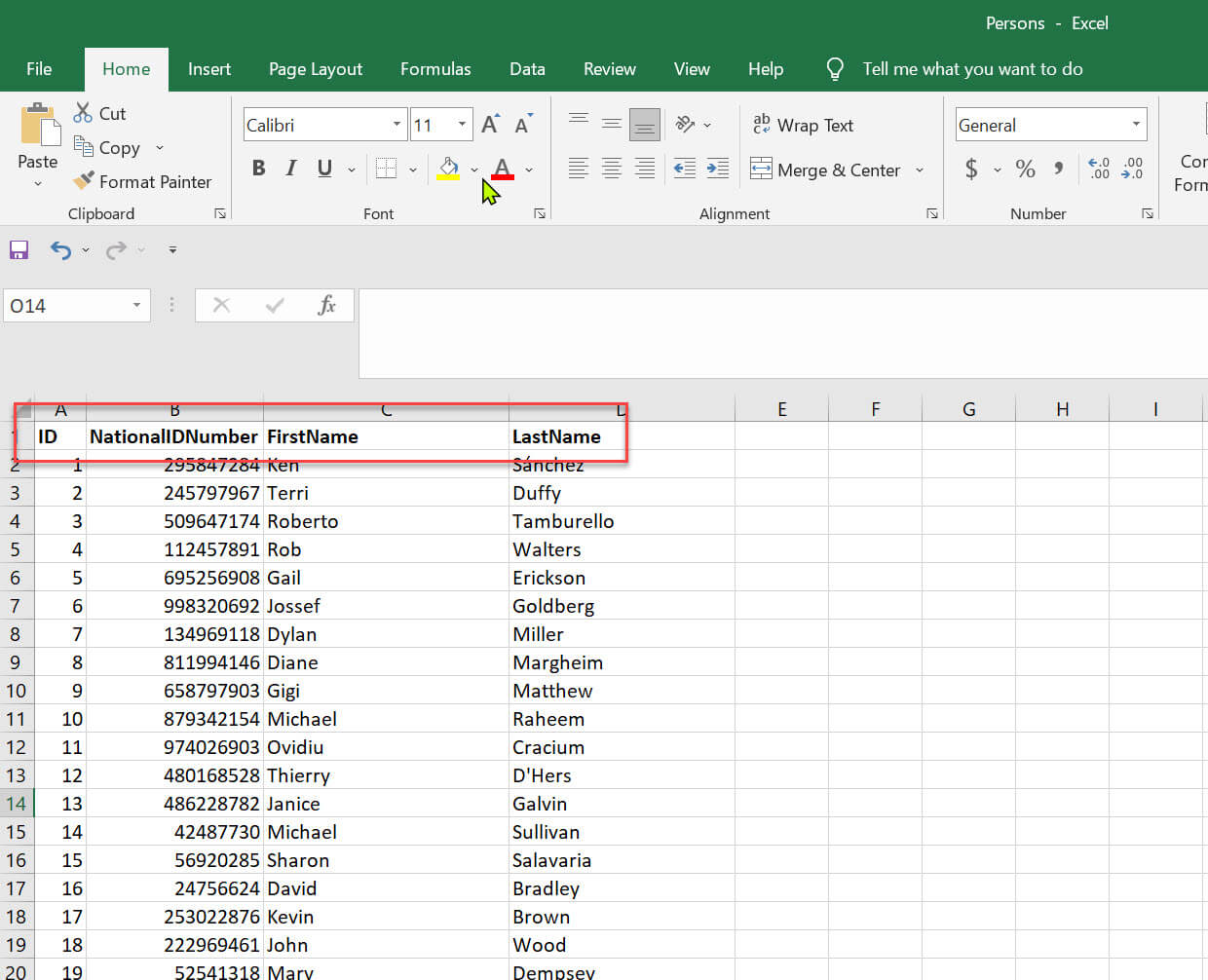
We can store query result set in an external table. Let's see an example below. I will use Persons.csv file for this demo.
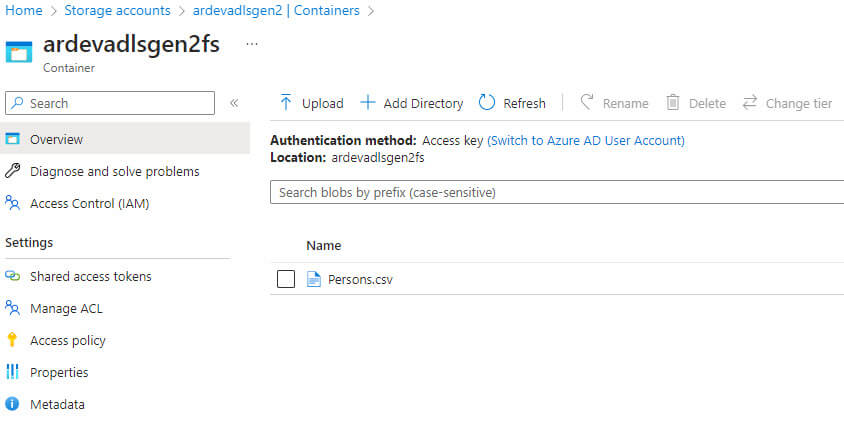
It has four columns ID , NationalIDNumber , FirstName and LastName:
Let's create a new SQL script in the Azure Synapse workspace:
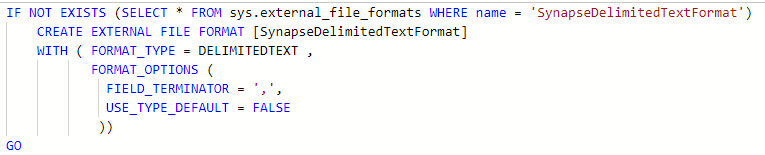
An external file format defines a layout of the data referenced by the external table. At first we need to create an external file format which defines external data stored in Azure Data Lake Store. In the below query I created a delimited type text file format:
I will create a data source for the Azure Data Lake Storage :

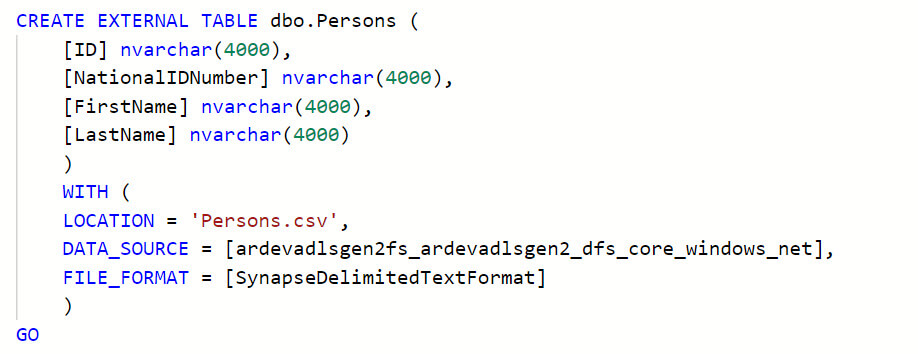
We are ready to create the external table . The syntax is similar to create a normal table and also we need to specify Location, Data Source and File format:
- LOCATION : source file location.
- DATA_SOURCE : Previously created data source for the source file.
- FILE_FORMAT : Previously created file format for the input file.
Let's Select the external table:
Conclusion
In this article we learn about using Serverless SQL to read data from an external storage and store the result set. The Serverless SQL is very cost effective solutions to run ad-hoc query for the data stored in the data lake. The cost is calculated based on the resource consumed by the queries.