

Most DBAs know the penalities incurred by using GUIDS.
- Fragmentation
- Increased storage and IO
- Increased memory pressures
I was debating these points with a senior solutions architect and he said (and meant it) "if you can come up with something that fulfills my architectural requirements, alleviates the concerns of the DBAs and is feasible for the development team then you can have it"!
Sounded like an interesting challenge.
Architectural requirements
The architetural requirements were clearly stated. We are operating with a 2nd site facility for business continuity reasons. Data has to flow from either of the two sites down to head office for reporting purposes.
- The customer must be unaware or have minimal awareness of any fail-over between the two sites
- When data is collated at the head office we do not want to spend our lives resolving conflicts in keys
- The application needs to be as scalable as possible
- Every record persisted as a result of customer interaction must have a unique key
Why not IDENTITY columns
From a pure DBA perspective an IDENTITY provides a straight forward sequential integer and in single site environments this simply isn't a problem. In multi-site environments it becomes a problem when you try and reconcile more than one set of records. The scenario is as follows
- Site A is functioning well and persists orders 1 to 10
- Site B is passive but kept up-to-date so effectively it has copies of orders 1 to 10.
- Lightning strikes Site A so Site B becomes active while repairs take place on Site A
- Site B takes orders 11 to 20 but there is no backflow to crippled site A.
- Site A comes back on line and starts taking orders 11 to 20 in direct conflict with activity that has taken place on Site B.
There is another problem with IDENTITY values that relate to scalability that can be illustrated by the sequence diagram below.
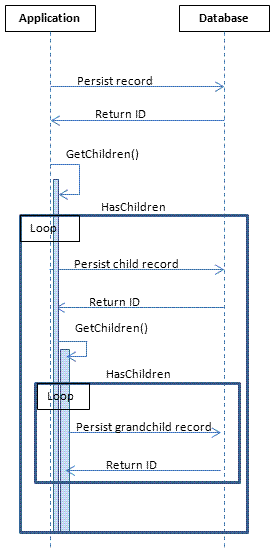
The application has to persist the principal record and wait for the DB to return the SCOPE_IDENTITY() value before it can start to persist the child records. For each of those child records the application has, in turn, to wait for the DB to return the SCOPE_IDENTITY() value before it can start to persist the grandchild records and so on.
You do need a very busy application before this becomes a real problem but you can see that the application has to wait for the database before it can proceed.
This is part of the reason that developers love GUIDs
Why do developers love GUIDS?
In a nutshell they can assign keys to a hierachy of objects completely independent to the database. This means that multiple instances of the application can be beavering away and the only thing they need to worry about from a database perspective is that they don't attempt to violate referential integrity. They are free to persist all children in one go if they so wish because they don't have to wait for, and use the returned SCOPE_IDENTITY() for each record there and then!
If you have 50 instances of an application where the database assigns the ID values then you have 50 instances that have to queue up behind one another and have to persist the records in a very strict logical order. For this reason NEWSEQUENTIALID() really doesn't offer developers much of a way forward as it reintroduces a dependency on the database.
Thought process behind a new key structure
I spent a lot of time thinking about the conflicting requirements
- DBAs prefer keys that don't cause fragmentation, page splits and other performance headaches
- Developers prefer to assign keys themselves
- Architects was scalability, good software engineering principals, particularly strong cohesion and loose coupling.
It was when the architect described a GUID as being globally unique in time and space that I had a break through.
I started off thinking about time.
1 second = 1000 milliseonds
1 minute = 60 seconds = 60,000 milliseconds
1 hour = 60 minutes = 3,600 seconds = 3,600,000 milliseconds
1 day = 24 hours = 1,440 minutes = 84,400 seconds = 84,400,000 milliseconds
4 years = 1,461 days = (3 x 365) + 366 days
4 years = 126,230,400,000 milliseconds
In fact 40 years worth of milliseconds comfortably fits into a 64 BIT integer
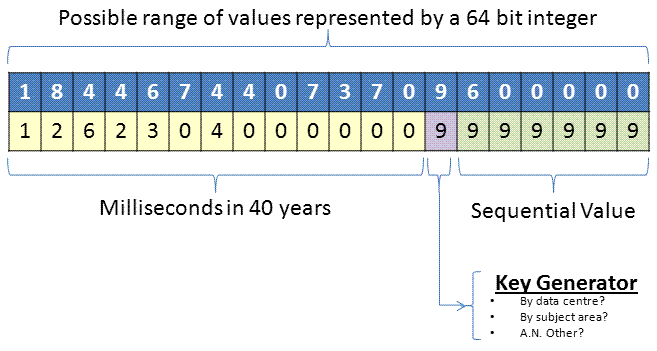
In fact from the diagram above we can see that a 64 BIT ineger allows us to have 10 key generators each inserting 1 million records per millisecond for 40 years! What happens after 40 years (well actually nearer 60 years)? Well, it will be job security for my great-grandchildren so I'm not going to worry about it.
Of course we have to remember that in SQL Server a BIGINT is a signed 64 BIT integer so we would have to subtract 9,223,372,036,854,775,808 from our key value to be able to get the full range of possible values.
What should generate the key?
We only want to use the keys we do not need to keep a permanent record of the keys being generated other than when they are attached to a record. In fact the generation of keys can be achieved purely from within the memory of the key generation application.
If the machine fails on which the key generator is running then on restart the machine simply continues to parcel out keys as the key is time bound.
The key generator has to be exposed as a service of some kind that can be accessed by the application and of course there can be up to ten of these. The flowchart that descibes the operation of the key generator is shown below:-
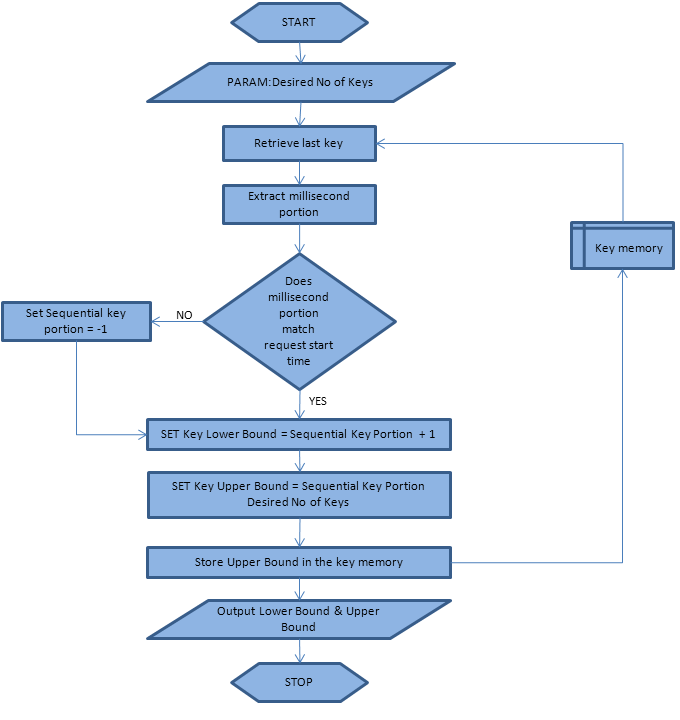
In short the key generator is a tiny program where key storage is entirely in memory and purely for the purposes of determining whether multiple requests have happened in a single millisecond.
Does this fulfill all requirements?
The key generator itself is miniscule and has no persistent storage so its performance is going to be blindingly fast. The method of communication between the application and the key generator needs to be thrashed out. There is no point having an immensely fast system if negotiation and communication is painfully slow! The developer can easily determine the number of objects in their object hierachy and in a single call they can reserve an entire range of keys to use as they see fit.
There is however one small fly in the ointment. Security.
A GUID is effectively a 128 bit random number. The chances of someone guessing a valid GUID representing a record in the database is extremely low. Therefore exposing a key as part of an autologin url on a website is not an unacceptably high risk. Our key is sequential and time based so is predicatable. However there are two mitigating arguments for our key
- You should avoid exposing internal keys wherever possible
- If you do need to expose them then you should obfuscate the value. Just because the value is sequential and therefore predictable does not mean you have to expose it as such.
Concluding thoughts
There is some flexibility in this proposed key generator
- If you do not need a million records per millisecond then you can either provision for more key generators or extend the life of the key generator by a few decades.
- If a single key generator provides for all your needs and beyond your predicted growth then you can simply eliminate it from your key entirely.
If you are running multiple key generators then of course you are going to get some fragmentation though by having the time portion of the key as the most significant digits this should be kept to a minimum.
