Welcome to the first level in the series "Stairway to SQL Server Always On". In this Level 1 article, we will discover the technologies "Always On", "Failover Cluster Instance" (FCI) and "Windows Server Failover Cluster". We'll look at each in detail and summarize where in the High Availability stack they sit. This will provide us a sound foundation, which is essential for the ascending stairway levels. Higher level stairways will research the required infrastructure and the different storage requirements and options that are used with Always On Availability groups and FCIs.
After each stairway level you will gain a further understanding of how the Always On structure is built. Although as a DBA, you may not have any direct interaction with the core infrastructure items underneath Always On and FCIs, it helps to have a full understanding of how all the technologies integrate. The final stairway will result in a functional Always On configuration.
We’re going to look at the basics first, which includes a brief description of each of the 3 technologies already mentioned.
There are many acronyms and abbreviations used in the Always On descriptions. We have included a glossary of common terms at the end of this article.
Without further ado, let's delve into a look at each of the technologies.
Windows Server Failover Cluster
Windows Server Failover Cluster (WSFC) is the core High Availability (HA) product that sits underneath all of the Microsoft High Availability applications. WSFC is a part of the Windows Server Operating System software suite. Before you can create a failover cluster instance of SQL Server, an Always On high availability group, or even a Microsoft Exchange mail server cluster, you need to deploy and configure a WSFC.
Windows Server Failover Clusters provide the ability to combine multiple computer nodes (physical and\or virtual) to service a set of applications for high availability. An application is server software such as SQL Server or Exchange, that we want to be able to run on any of the nodes. An application is made highly available by presenting to clients a virtual access point, comprising a unique IP address and a unique computer name or "virtual network name". This address and virtual name become resources in an application group and are passed between participating nodes like tokens. A critical hardware failure of the active computer node would result in the loss of the group service(s) running on that node. The cluster service would automatically attempt a restart of the group on the current node or a partner node, depending on the type of failure (hardware or software).
At a high level, the client access point details are transferred along with any disk and service resources to a failover partner node. A failover of a clustered instance causes disconnection of client connections; the clients may then reconnect once the service is available on another node. The common failures usually are one of these, but any failure of the application could cause the service to move to another node:
- Public NIC or network failure
- Power supply failure
- Motherboard failure
- CPU Failure
With WSFCs, clustered applications are installed into separate groups or "Applications", which contain a set of resources such as disks, services, IP addresses, etc. The group and its resources are owned by a single node at any one time, and the resources are not accessible from any other partner node unless a planned switch or a failover to that node occurs.
A typical view of a Windows Server Failover Cluster is shown below. The cluster nodes are all connected by a network, and the domain controller and DNS service work with the WSFC to allow clients to connect to the virtual IP or virtual network name, no matter on which node the service is actually running.
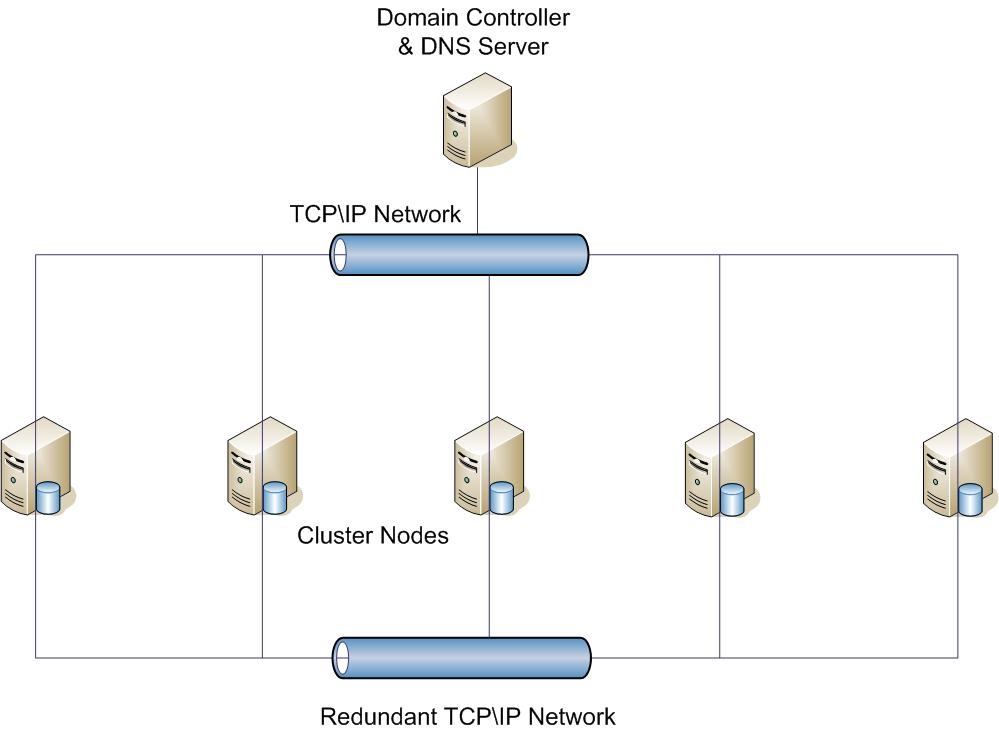
For the deployment of an FCI, the computer nodes must use shared storage that is presented to each node, usually from a SAN. For the deployment of a typical Always On group, the nodes utilize their own local storage, which is not shared with other cluster partners.
Although cluster nodes may have disparate hardware, it is usually best to keep the hardware uniform across nodes to avoid any situations where a less powerful node has to handle loads beyond its capability. However, the nodes must all use the same OS patch levels and network configurations; this will become clear when validating your configuration before deploying the Windows Server Failover Cluster. The maximum cluster node counts differ between Windows Server versions (8 nodes in Windows 2003, 16 nodes in Windows 2008 and 64 nodes in Windows 2012).
Deploying a robust Windows Server Failover Cluster requires careful design, supported hardware and the appropriate edition of the Windows Server Operating System. Geo-graphically dispersed clusters (clusters across multiple WANs) further increases the amount of design and planning required and significantly increases the cost as well.
It is important to know that a WSFC provides failover partner capability only. The applications are not load balanced or scaled out across the nodes. Each service runs on one and only one node.
Typically, in large multi node clusters you install your clustered applications across a subset of the Windows Server Failover Cluster nodes. Making the mistake of installing the applications across all nodes can cause some undesired failovers and, as we'll see later, also violates the Always On group restriction policy which ensures that all Always On instances are homed on separate nodes in the cluster.
The WSFC requires some form of mediation to control cluster resource ownership. This mediation is provided in the form of Cluster Quorum. Since Windows 2003 SP1, this Quorum takes the form of a node voting system with the majority votes required to maintain Quorum. You may also use additional quorum resources in the form of a disk for localized clusters or a remote file share for multi-site clusters. Starting with Windows Server 2012, Quorums utilize a Dynamic Node Weight Configuration to balance cluster votes dynamically during a planned outage to prevent unnecessary failovers. We will discuss Quorums in more detail in future levels.
Failover Cluster Instances
Failover cluster instances of SQL Server have long been a popular High Availability technology within the SQL Server product. A highly available instance of SQL Server is clustered to mitigate any node hardware failures and any potential software failures. The only weak link here is the storage; the storage subsystem becomes the Single Point of Failure.
A Failover Cluster Instance is an instance of SQL Server, default or named, that has been installed onto a WSFC as a clustered application. The clustered application typically has the following resources as a minimum:
- IP address
- Network name
- Shared disk(s)
- SQL Server service
- SQL Server agent service
A standalone instance shares the same base requirements, except that with a standalone instance, the IP address and Networkname are taken from the computer node itself and the disk storage is provided by the computer’s local disk resources.
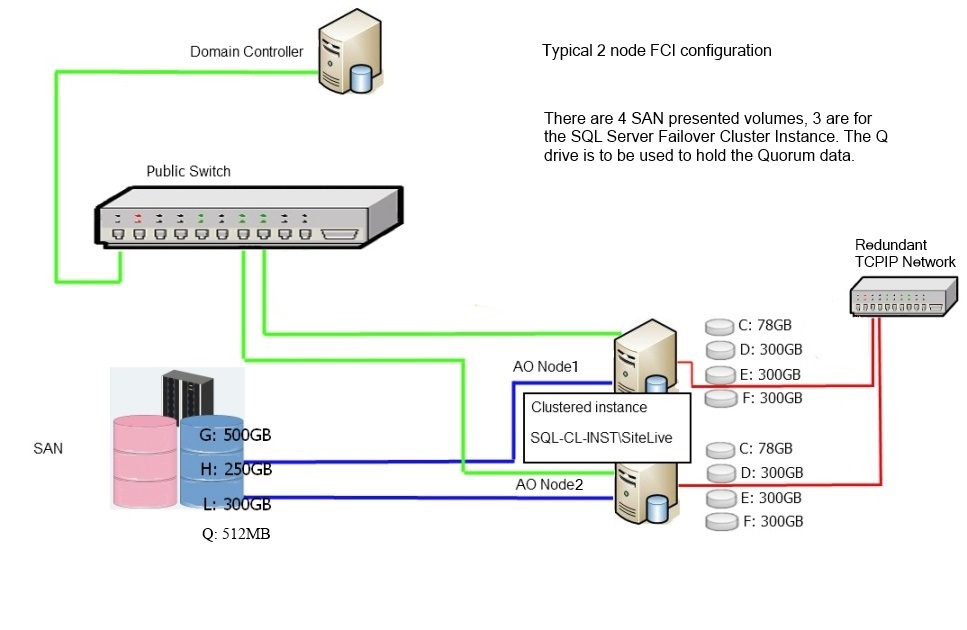
Referring to the diagram above, we see a typical view of a 2 node cluster with a single FCI. A clustered instance of SQL Server will utilize any shared storage that has been presented to the WSFC nodes. Usually this storage will take the form of LUNs presented from a SAN. An FCI of SQL Server is deployed in a 2 step process which will be covered in a later stairway. For now, here’s a basic overview of the 2 step process to deploy a Failover Cluster Instance of SQL Server:
- Launch the "New SQL Server Failover Cluster Installation" wizard on the first computer node that will participate in the FCI. Once this has been performed and completed successfully, you are ready for Stage 2.
- Launch the "Add Node to a SQL Server Failover Cluster" wizard on any computer node in the WSFC that you wish to participate in the new SQL Server FCI.
Note: Although Standard Edition limits a FCI to 2 nodes, this does not dictate how many nodes have membership of the Windows cluster (you may have any number up to the Operating System maximum). The limitation is enforced at the SQL Server installer level.
An FCI is a little like a running track relay team hand-off process; a computer node owns the clustered SQL Server application and its resources and then provides access to clients to the SQL Server service (holds the baton). Upon failure of the active computer node (dropping of the baton), a partner node steps in and takes ownership of the clustered application and its resources (picks up the baton).
Always On Availability Groups
For many years now, Failover Clusters have been the primary method of providing High Availability for SQL Server. When one node fails, the other takes over providing the SQL Server services to clients. Always On integrates with the Windows Server Failover Cluster technology to provide a more resilient High Availability platform.
Whereas clustering works at the instance level, Always On is configured on the database level. Always On Availability Groups are the new technology introduced in SQL Server 2012 to replicate pre-defined groups of databases to a set of Read Only partner instances, or replicas, as they are known in Always On. Multiple nodes each host a synchronized copy of the Always On database(s), and access is best provided by the configuration of a listener (more on this shortly).
The Always On Availability Group requires one or more secondary replicas to host a copy of the highly available database(s). These secondary databases may be either readable or not. They may also be updated in an asynchronous or synchronous manner. Asynchronous replicas support only manual forced failovers while synchronous replicas support automatic or manual failovers.
Secondary Read Only replicas may be configured to respond to read only queries, you may also target Secondary’s for backup\maintenance operations to relieve the pressure on the Primary database. This Primary to Secondary relationship is also reversible to ensure true High Availability. Any Read Only partner that is appropriately configured may assume the Primary role in the event of a failure within the system.
Always On relies on the WSFC core functionality to achieve the high availability that AO offers, but does not require any of the following shared resources associated with an FCI.
- Shared disks
- Shared IP address
- Shared network name
- Shared SQL Server and SQL Server agent resources
There is one exception to this shared resource rule. When creating an Always On group listener, this will create an IP Address and Network name resources that will be shared by the AO group replicas.
As we have discovered, the weak link in the chain for Failover Cluster Instances is the shared storage. There are many ways to achieve redundancy here, but it usually comes at significant cost, and it is often difficult to setup and maintain. Of course, as previously mentioned, a failover cluster instance only mitigates the server hardware. It does not provide a single or even multiple secondary databases. We have database mirroring in SQL Server versions prior to SQL Server 2012, but these only provide scope for a single, non-readable, secondary database.
Always On still uses the familiar SQL Server endpoints for instance to instance communication. Endpoints are automatically configured when using the availability group deployment wizard. The wizard driven deployment offers the easiest deployment route, whereas manual deployment requires a great deal of manual interaction. Despite this, a basic Always On group configuration is still extremely easy to deploy and configure and offers a level of HA that was previously not available without resorting to complicated levels of feature integration.
You may also create a highly available listener service, which you will use to accept incoming connections to the availability group. The listener consists of a unique IP address and a unique virtual network name. This is by far one of the most significant changes in making the databases within the group highly available.
During the creation of an Always On Availability group, a clustered role is created within the Windows Server Failover Cluster and contains a single resource. This resource is failed over between partner nodes during an Always On group failover and identifies the Primary replica for the Always On group.
Always On Listener
The listener, when configured, will be created as resources and reside within the Failover Cluster application\role for the Always On Availability Group. The resources are:
- Virtual IP address
- Virtual network name
The listener uses a TCP port to accept incoming connections and by default connects to the Primary replica. When read only routing has been configured, a connection to the listener specifying a read only intent connection will be routed to a secondary partner rather than the primary replica. This is another way in which we may ease the load on the Primary replica.
During a failover of the Always On group, the clustered application and its resources are failed over between nodes in the cluster. The node location of the clustered application tracks the Primary replica and its underlying node and moves around in the cluster as required. Where the Primary replica is a clustered instance of SQL Server, the Listener is owned by the active node for that FCI\replica.
Conclusion
This concludes level 1 of the stairway, which offered a quick introduction to 3 core technologies used to make our SQL Server instances and their objects highly available. In our High Availability stack we have the WSFC as the base level, which is the primary requirement for an installation of an FCI or an Always On Availability group. Next we have the FCI, which sits atop the WSFC and relies on the cluster to serve and protect the SQL Server instance. Lastly we have the Always On group, sitting atop standalone instances of SQL Server and\or Failover Cluster Instances of SQL server.
In Level 2 we will look at the storage types available and their typical usages within SQL Server High Availability. This will help you to understand future Stairway levels in the series.
Glossary
| AO | Always On availability group |
| FCI | Failover cluster instance of SQL Server |
| TCPIP | Transport control protocol/internet protocol. The network protocol used by Microsoft client networks |
| OS/NOS | Network Operating system |
| WSFC | Windows Server failover cluster |
| LAN | Local area network |
| WAN | Wide area network |
| DNS | Domain name system |
| DHCP | Dynamic host configuration protocol, automatically assigns IP addresses to network computers |
| IP Address | a 32 bit (IPV4), unique address assigned to a computer object |
| AD | Active Directory, directory services. The Microsoft technology used for object management in Windows domains |
| DR | Disaster recovery |
| SPF | Single point of failure |
| SCSI | Small computer systems interface |
| iSCSI | Internet Small computer systems interface |
| FC | Fibre channel |
| Replica | The terminology used in SQL Server Always On Availability Groups to refer to an instance of SQL Server which is part of a particular Always On group |