Introduction
Up to this point, the Stairway has focused on the mechanics of safely deploying a changeset. In Level 4, the focus was on preparing a rehearsed deployment unit for controlled execution in production, ensuring that the deployment artifacts remain consistent with what was validated across environments. The model, therefore, assumes that the work has been structured correctly, rehearsed, and prepared to move through the deployment pipeline.
In smaller environments—such as personal databases or small teams working on a shared schema—this discipline is often sufficient to ensure safe deployments. Things become more complex when responsibility for deployment is shared across multiple developers. In larger teams, across coordinated development groups, or in high-frequency delivery environments, multiple changes are usually developed in parallel, within the same release cycle and against the same baseline. This introduces a new challenge not yet visible in the previous levels: concurrency.
Concurrency and the Deployment Baseline
By now, the deployment baseline stands as a fundamental reference. It is not just a point in time, but a known and stable state of the database, against which a full rehearsal cycle ensures predictable deployment outcomes. As long as changes are developed in isolation, this assumption holds naturally. When several changes are developed in parallel, however, overlapping work is no longer an exception but an inherent characteristic of the development process.
This introduces a subtle but critical risk: deployments can fail or produce unintended results not because of errors in the changeset itself, but because the underlying baseline has shifted. For this reason, managing concurrent development requires explicit control over the deployment baseline. Without such control, the guarantees established so far can no longer be relied upon. To understand how this can be achieved in practice, it is necessary to examine how parallel changesets interact.
A common baseline is not defined only by the state of the database at a given point in time, but also by the scope of the objects involved. Two parallel changesets may originate from the same baseline and still coexist safely if they operate on different parts of the schema. In such cases, they can be developed, rehearsed, and even deployed in parallel without requiring reconciliation. Concurrency becomes a real issue only when their scopes overlap, so the first rule is simple: avoid it where possible.
Keeping the scope of each changeset as narrow as possible, and ensuring clear ownership, reduces the likelihood of overlapping changes. This is a simple and effective practice.
When this is not feasible, and work must be shared across multiple contributors, a valid alternative is to coordinate the effort within a single shared changeset. This brings concurrency back into the rehearsal phase, where it can be controlled, and prevents baseline misalignment.
Dealing with Overlapping Changesets
When overlap occurs and cannot be avoided, it can take different forms. In some cases, the conflict is purely nominal, such as when two changesets introduce objects with the same name, and can be resolved through simple refactoring.
-- Changeset 1
CREATE TABLE cfg.MapCompanyCodes
(
CompanyCode char(6) NOT NULL CONSTRAINT PK_MapCompanyCodes PRIMARY KEY
,CompanyName nvarchar(80) NOT NULL
,LocalCode varchar(20) NOT NULL
)
-- Changeset 2
CREATE TABLE cfg.MapCompanyCodes
(
CompanyCode char(6) NOT NULL CONSTRAINT PK_MapCompanyCodes PRIMARY KEY
,CompanyName nvarchar(80) NOT NULL
,IBRNCode varchar(30)
)
-- Changeset 2 refactored
CREATE TABLE cfg.MapCompanyIBRN
(
CompanyCode char(6) NOT NULL CONSTRAINT PK_MapCompanyIBRN PRIMARY KEY
,CompanyName nvarchar(80) NOT NULL
,IBRNCode varchar(30)
)In other cases, the conflict reflects a difference in intent, for example when one changeset removes an object that another modifies, requiring a clear decision about which direction prevails.
-- Changeset 1 DROP TABLE cfg.MapCompanyCodes -- Changeset 2 ALTER TABLE cfg.MapCompanyCodes ADD IBRNCode varchar(30)
Here, a decision must be made: whether to retain the table cfg.MapCompanyCodes and extend it, or remove it entirely.
More commonly, overlap affects the same structural elements, such as views, programmable objects, or tables. In these situations, changes must be merged so that the resulting definition consistently incorporates all intended modifications.
-- Changeset 1 ALTER VIEW cfg.vwCompanyCodes AS SELECT CompanyCode ,CompanyName ,LocalCode FROM cfg.MapCompanyCodes -- Changeset 2 ALTER VIEW cfg.vwCompanyCodes AS SELECT CompanyCode ,CompanyName ,IBRNCode FROM cfg.MapCompanyCodes -- Merged Changeset ALTER VIEW cfg.vwCompanyCodes AS SELECT CompanyCode ,CompanyName ,LocalCode ,IBRNCode FROM cfg.MapCompanyCodes
These scenarios converge into a deployment discipline that can be visualized as follows:
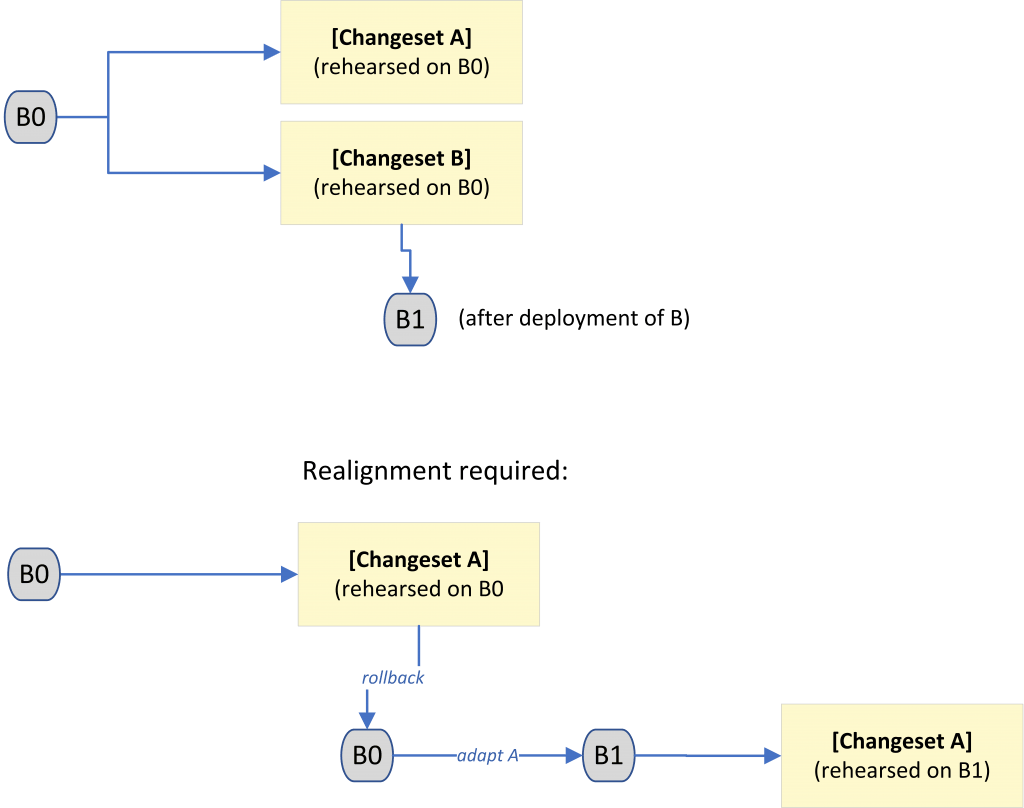
At this point, only one changeset can retain its original baseline; all others must be realigned before they can be safely deployed. Realignment consists of returning to the last known baseline and adapting the changeset to the new one. In practice, this means incorporating the effects of already deployed changes into both the Create and Rollback scripts, ensuring that the changeset remains consistent with the current state of the database. Realignment applies only to changesets that have not yet been deployed. Once a changeset has been released, its baseline becomes fixed and can no longer be altered.
When more than two changesets are involved, this process must be applied iteratively. Each of them is realigned in turn, always within the boundary of its own Create and Rollback scripts. This ensures that every deployment unit remains self-contained and can be validated independently.
Realignment is always performed within the scope of a single changeset. Dependencies are resolved by adapting each changeset individually, rather than by introducing cross-changeset coupling.
Immutability and Controlled Evolution
When introducing the deployment contract in Level 2, the concept of a checkpoint was defined as a boundary between two known structural states. In this context, that boundary applies not at the script level, but at the level of the changeset: once deployed, validated, and released, a changeset becomes immutable. Any subsequent modification affecting the same context or objects must follow a forward-only approach and be expressed through a new changeset. This constraint follows from the need to preserve baseline consistency. Altering a changeset after deployment would invalidate the structural state it helped establish.
With these principles in place, the focus naturally shifts. Once changesets are consistently aligned before deployment and preserved unchanged afterward, they begin to form a structured sequence of evolution. Understanding how these units accumulate and interact over time becomes the next step.
