
One of the features that I most value in SQL Server is Row-Level Security (RLS). This feature was introduced on the Azure SQL Database platform in 2015 and in the on-premise product with SQL Server 2016. This feature allows administrators and developers to more easily limit access to users on a row by row basis, when there is information available to somehow determine if a user should view the data in a row. This article will look at the basic ways in which RLS works and can be implemented in your applications.
This article takes a basic look at how RLS can provide limited access to rows of data.
A Quick Demo
Let's start by setting up a small database and a couple users. Run the RLS__02_Setup.sql script to create a database and add a couple logins. Make sure you do this on a development system.
Once you execute the entire script, there will be an OrderHeader table with 6 rows of data. These rows are:
OrderID Orderdate CustomerID OrderTotal OrderComplete SalesPersonID ----------- --------------------------- ----------- --------------------------------------- ------------- ------------- 1001 2016-01-12 00:00:00.000 1 5000.0000 1 1 1002 2016-01-23 00:00:00.000 2 1250.2500 1 2 1003 2016-01-23 00:00:00.000 1 922.5000 1 2 1004 2016-01-24 00:00:00.000 3 125.0000 0 1 1005 2016-02-03 00:00:00.000 3 4200.9900 0 3 1006 2016-02-13 00:00:00.000 2 1652.8900 1 2
Note there is a SalesPersonID in the table. This corresponds to a SalesPersonID in the SalesPeople table. In this demo, the user bsmith has been assigned SalesPersonID=1 and sjones has SalesPersonID = 2.
If you now run the RLS_1_DemoQueries.sql script, you will see these results.
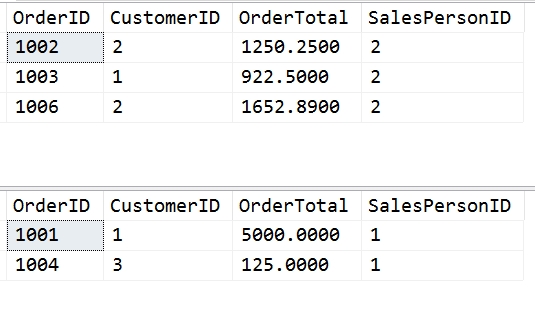
The first result set is run as bsmith, and consists of this code:
SELECT OrderID, CustomerID, OrderTotal, SalesPersonID FROM dbo.OrderHeader AS oh
Note that only 3 rows are returned. These are the 3 rows with SalesPersonID = 2. The second result set shows 2 rows, each of these with SalesPersonID = 1. This second query was executed as sjones.
In each case, a normal query, a SELECT without any joins or other changes, against a table, returns a limited set of data. Let's dive deeper in RLS.
The RLS Advantage
Row Level Security is built into the core SQL Server query engine, which means the setup and ongoing administration is much easier than row based security has ever been in the past. An administrator can apply security to a series of objects, by specifying the rules on which access is granted in a series of functions. More importantly, a function can be applied to multiple objects. This consolidates security in a way that is transparent to the developer writing queries, and easily managed at the database level.
This creates consistency for the developer in that the security is always applied without any burden to ensure that T-SQL code checks for access. The developer can write code as if they have access to all rows, and the final implementation will ensure that each time a query attempts to access a table with a security policy applied, the limitations are enforced.
RLS also allows for separate control of reads versus write activity. There are two types of predicates that can be assigned to a table: filter and block. Filter predicates will work to limit access on read operations, which can be SELECT, UPDATE, and DELETE operations. Block predicates work by explicitly blocking write operations with the application available before insert or delete operations, and either before or after updates. This ensures that the security needs of your organization can be implemented in the application.
RLS Requirements
As with any method of enforcing access on a row level, there must be some way to discern if a particular user should access that row. This means that some aspect of the data, a name or key, must be stored in the row. This means that the database design must include mechanisms that allow a row to be related to a user in some way. This can be through a series of joins or relationships, implicit or explicit, that exist inside the tables. This means an application must be able to determine how to segregate rows according to some value.
There must also be a way to relate a particular user or login to this data. There are a few possibilities that can be used to do this. One is to store the user or login name in a table and relate that to data rows in some way. The other way is to use a variable of some sort, such as the data returned from CONTEXT_INFO() to store information about a user. The choice made often depends on the application architecture, as some applications used a shared login to the database instance and must pass along some identifying information about the actual user.
In future levels, we will examine the various ways in which user RLS can be implemented, both from the data side and the user identification side.
Before RLS
Many people have implemented row level security in various ways over the years using the basic mechanisms and objects in SQL Server. Most of those implementations were complex to maintain and difficult to code and manage over time. The reason is that we never want to actually assign security for every row in our database to users or roles. Instead, we need to somehow group rows based on an attribute in the row.
As an example, here's the type of thing that existed in a system I inherited and worked on years ago. The overview is that there is a mapping between users and other tables that is managed. In the image below, we can see the outline of the objects and code.
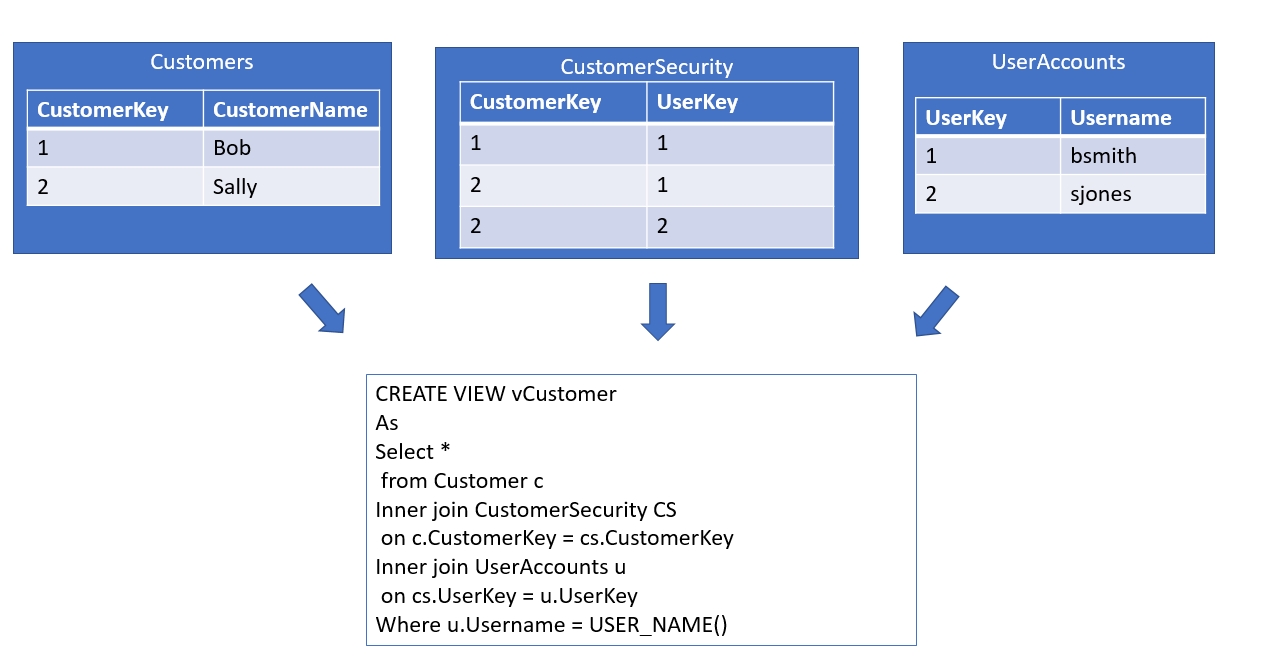
Each username was stored in a table (UserAccounts) with a surrogate PK integer value, UserKey. Each customer also had their own surrogate PK integer, CustomerKey. We had a many to many join table, CustomerSecurity, which contained the CustomerKey and UserKey. Each row allowed a particular user to be mapped to a customer. all query access was done through a view, vCustomers, which always contained the fields from the Customer table along with a join to CustomerSecurity and the user table, along with a WHERE filter that compared the current User_Name() function value to the UserAccounts table. This ensuered that a query would not return any customers if a mapping for that user did not exist in the CustomerSecurity table.
This works well, and can ensure efficient query execution, but this means that the developer is responsible for always using views or performing the requisite joins in their code. This also doesn't explicitly prevent write activity, which must be coded into the application.This puts the burden for consistent security on the developer, and any mistakes or ommissions in coding the application will result in security holes.
Summary
In this level, we have introduced Row Level Security with a short demonstration that shows how two different users can receive different results from the same query. This shows how the data in tables can be used to relate a particular row to a certain user within the RLS system. This is contrasted with one way that row level access might be otherwise be implemented.
Future levels will move forward with more details on predicates and policies, adding to the simplistic structures created in this initial demonstration. The reader is encouraged to experiment with different users and logins, various rights and permissions, and create new objects that might contain similar columns and include them in the RLS structure. keep in mind that the relation between the data and the user is what matters, and this is defined in the Security Predicate. This function defines the way security is applied when a table is accessed.

