Replacing / Removing All Text In Multiple Sets of Characters in SQL
-
One of the result fields has multiple html references in it such as in the code below. Currently the result set looks like:
Supervisor Employee
----------- --------
Supervisor1 <td><br>Employee1<td><br>Employee2<td><br>Employee3</table>
Supervisor2 <td><br>Employee1<td><br>Employee2</table>
Supervisor3 <td><br>Employee1<td><br>Employee2<td><br>Employee3<td><br>Employee4</table>
Desired Output:
Supervisor Employee
----------- --------
Supervisor1 Employee1 || Employee2 || Employee3
Supervisor2 Employee1 || Employee2
Supervisor3 Employee1 || Employee2 || Employee3 || Employee4
Sample query:
create table #Temp
(
Supervisor varchar(200),
Employee Varchar(200),
)
INSERT INTO #Temp
VALUES ('Supervisor1', '<td><br>Employee1<td><br>Employee2<td><br>Employee3</table>')
, ('Supervisor2', '<td><br>Employee1<td><br>Employee2</table>')
, ('Supervisor3', '<td><br>Employee1<td><br>Employee2<td><br>Employee3<td><br>Employee4</table>')
select * from #temp
drop table #temp
-
Huh? This HTML is messed up. Standard format for an HTML table is
<table>
<tr>
<td>R1C1</td>
<td>R1C2</td>
<td>R1C3</td>
</tr>
<tr>
<td>R2C1</td>
<td>R2C2</td>
<td>R2C3</td>
</tr>
</table>Searched around, because parsing this glop in T-SQL is awful. Then I found this by Bert Wagner (Gotta love the "Don't do it!" face in the photo!) which is here. (basically, use XQuery).
-
One way to do this would be to do search and replace. It would nice to have a regex but it depends on your faith in a single pattern. Per pietlinden, in order to parse the html using sql xml it would have to be a valid document. It doesn't appear to be the case or the fragments might have to be combined with something else.
Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
-
Here's a table based scalar function approach. Actually, I had a very similar issue this week and this code is lifted from that solution. Which I'm not super happy with about because I couldn't figure out a way to do this without a scalar function. Nested REPLACE functions was not an option because the list is variable. Dynamic sql is tantamount to failure imo lol. For the OP maybe nested REPLACE functions would be best.
/* TABLE OF REPLACEMENTS */
drop table if exists dbo.test_string_replacements;
go
create table dbo.test_string_replacements(
sr_id int identity(1,1) constraint pk_string_replacements primary key not null,
search_term nvarchar(20) unique not null,
replace_with nvarchar(80) not null);
go
insert dbo.test_string_replacements(search_term, replace_with) values
('<td><br>', ' || '),
('</table>', ' || ');
/* FUNCTION TO REPLACE STRINGS FROM TABLE */
drop function if exists dbo.test_scalar_string_replace;
go
create function dbo.test_scalar_string_replace(
@string nvarchar(max))
returns nvarchar(max) as
begin
select
@string = trim(replace(@string collate Latin1_General_CS_AS, search_term, replace_with))
from
dbo.test_string_replacements;
select
@string=iif((select left(@string, 3))='|| ', (right(@string, len(@string)-3)), @string);
select
@string=iif((select right(@string, 3))=' ||', (left(@string, len(@string)-3)), @string);
return @string;
end
go
drop table if exists #Temp;
create table #Temp(
Supervisor varchar(200),
Employee Varchar(200));
insert #Temp values
('Supervisor1', '<td><br>Employee1<td><br>Employee2<td><br>Employee3</table>')
, ('Supervisor2', '<td><br>Employee1<td><br>Employee2</table>')
, ('Supervisor3', '<td><br>Employee1<td><br>Employee2<td><br>Employee3<td><br>Employee4</table>');
--select * from #temp;
--drop table #temp;
select
Supervisor,
dbo.test_scalar_string_replace(Employee) Employee
from
#Temp;Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
-
@scdecade - your solution will not work for the OP. The trim function is not available on SQL Server 2016 and would need to be replaced with a rtrim(ltrim(...)). It also, unnecessarily converts the string to nvarchar and returns an nvarchar value instead of the original varchar.
Assuming the pattern for that column always begins with '<td><br>' and always ends with '<\table>' then you could do this:
Select *
From #temp tt
Cross Apply (Values (replace(replace(tt.Employee, '<td><br>', '||'), '</table>', '||'))) As v(x)
Cross Apply (Values (substring(v.x, 3, len(v.x) - 4))) As e(Employees)If the OP really does want a space before and after - this can be adjusted to include the spaces. If the data does not conform to that pattern - then you would need to adjust the code for each pattern found. That could be done using multiple CTE's for each pattern...for example:
Drop Table If Exists #temp;
Create Table #temp (
Supervisor varchar(200)
, Employee varchar(200)
);
Insert Into #Temp
Values ('Supervisor1', '<td><br>Employee1<td><br>Employee2<td><br>Employee3</table>')
, ('Supervisor2', '<td><br>Employee1<td><br>Employee2</table>')
, ('Supervisor3', '<td><br>Employee1<td><br>Employee2<td><br>Employee3<td><br>Employee4</table>')
, ('Supervisor4', '<td>Employee1<td><br>Employee2</td>')
, ('Supervisor5', '<td>Employee1<td><br>Employee2<td><br>Employee3<td><br>Employee4</td>')
, ('Supervisor6', 'Employee1||Employee2')
, ('Supervisor7', 'Employee1||Employee2||Employee3||Employee4');
With patternOne
As (
Select tt.Supervisor
, e.Employees
From #temp tt
Cross Apply (Values (replace(replace(tt.Employee, '<td><br>', '||'), '</table>', '||'))) As v(x)
Cross Apply (Values (substring(v.x, 3, len(v.x) - 4))) As e(Employees)
Where tt.Employee Like '<td><br>%'
And tt.Employee Like '%</table>'
)
, patternTwo
As (
Select tt.Supervisor
, e.Employees
From #temp tt
Cross Apply (Values (replace(replace(replace(tt.Employee, '<td><br>', '||'), '<td>', '||'), '</td>', '||'))) As v(x)
Cross Apply (Values (substring(v.x, 3, len(v.x) - 4))) As e(Employees)
Where tt.Employee Like '<td>%'
And tt.Employee Like '%</td>'
)
Select tt.Supervisor
, tt.Employee
, Employees = coalesce(p1.Employees, p2.Employees, tt.Employee)
From #temp tt
Left Join patternOne p1 On p1.Supervisor = tt.Supervisor
Left Join patternTwo p2 On p2.Supervisor = tt.Supervisor;If this has to be repeated and available across multiple queries and patterns - you could create an inline-table valued function that accepts the input string, the start characters, the end characters and the delimiter characters. It all depends on the data...
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs -
If using nested replace then this could be done in the select list. What if the list of replacements is variable?
select
ltrim(rtrim(replace(replace(replace(replace(replace(Employee, '<td><br>', '||'), '<td>', '||'), '</td>', '||'), '</table>', ' '), '||', ' '))) Employee
from
#Temp;Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
- Jeffrey Williams wrote:
@scdecade - your solution will not work for the OP. The trim function is not available on SQL Server 2016 and would need to be replaced with a rtrim(ltrim(...)). It also, unnecessarily converts the string to nvarchar and returns an nvarchar value instead of the original varchar.
This version is cleaned up a bit and fixes trivial issues.
/* TABLE OF REPLACEMENTS */
drop table if exists dbo.test_string_replacements;
go
create table dbo.test_string_replacements(
sr_id int identity(1,1) constraint pk_string_replacements primary key not null,
search_term varchar(20) unique not null,
replace_with varchar(80) not null);
go
insert dbo.test_string_replacements(search_term, replace_with) values
('<td><br>', '||'),
('</table>', '||'),
('<td>', '||'),
('</td>', '||'),
('||', ' ');
/* FUNCTION TO REPLACE STRINGS FROM TABLE */
drop function if exists dbo.test_scalar_string_replace;
go
create function dbo.test_scalar_string_replace(
@string varchar(max))
returns varchar(max) as
begin
select
@string = ltrim(rtrim((replace(@string collate Latin1_General_CS_AS, search_term, replace_with))))
from
dbo.test_string_replacements;
return @string;
end
go
drop table if exists #Temp;
create table #Temp(
Supervisor varchar(200),
Employee Varchar(200));
insert #Temp values
('Supervisor1', '<td><br>Employee1<td><br>Employee2<td><br>Employee3</table>'),
('Supervisor2', '<td><br>Employee1<td><br>Employee2</table>'),
('Supervisor3', '<td><br>Employee1<td><br>Employee2<td><br>Employee3<td><br>Employee4</table>'),
('Supervisor4', '<td>Employee1<td><br>Employee2</td>'),
('Supervisor5', '<td>Employee1<td><br>Employee2<td><br>Employee3<td><br>Employee4</td>'),
('Supervisor6', 'Employee1||Employee2'),
('Supervisor7', 'Employee1||Employee2||Employee3||Employee4');
select
Supervisor,
dbo.test_scalar_string_replace(Employee) Employee
from
#Temp;Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
-
IF the pattern is consistent, this is easy.
--===== Create the test data. This is not a part of the solution.
CREATE TABLE #Temp
(
Supervisor VARCHAR(200)
,Employee VARCHAR(200)
)
;
INSERT INTO #Temp
(Supervisor,Employee)
VALUES ('Supervisor1','<td><br>Employee1<td><br>Employee2<td><br>Employee3</table>')
,('Supervisor2','<td><br>Employee1<td><br>Employee2</table>')
,('Supervisor3','<td><br>Employee1<td><br>Employee2<td><br>Employee3<td><br>Employee4</table>')
;
--===== If the pattern is consistent and ignoring the original sin here, the following will work just fine.
SELECT Supervisor
,Employee = STUFF(REPLACE(REPLACE(Employee,'<td><br>',' || '),'</table>',''),1,4,'')
FROM #Temp
;Of course, if the pattern is not consistent, then you'll have to resort to some other "nasties" to get the data. I think that would also be a "sin" and so I'm not even going there.
Ok. So what's the "original sin" I'm talking about? The answer is converting denormalized data to a different format of more denormalized data. It just doesn't make sense to me even if this were Oracle where "||" is used for concatenation.
With that in mind, and I DO realize it's not what the OP asked for but it's what I believe he'll need someday (if not sooner), let's normalize this data... (and this is one place where STRING_SPLIT() is actually useful)...
WITH cteDelimit AS
(
SELECT Supervisor
,Employee = REPLACE(REPLACE(REPLACE(REPLACE(Employee,'<br>',''),'<td>',CHAR(9)),'</table>',''),'<table>','')
FROM #Temp
)
SELECT DISTINCT -- Just a safeguard against dupe employees for the same Supervisor.
Supervisor
,Employee = split.value
FROM cteDelimit cte
CROSS APPLY STRING_SPLIT(cte.Employee,CHAR(9)) split
WHERE split.value > '' --Don't return NULLs, Blanks, or Empty Strings
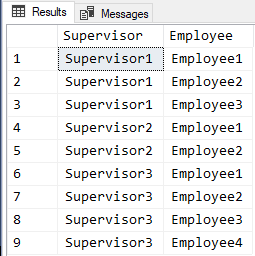
;And that returns the following for the test data given.

That (if we had more realism in the names) leads to a whole lot of wonderful possibilities including creating of an Adjacency List that can easily be maintained and converted to and analyzed by Nested Sets in many wonderful ways. Who knows? You might even find some names that are no longer employees and some new names that are. 😀
Please see the following article for more information on hierarchies and org charts, etc.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 8 posts - 1 through 8 (of 8 total)
You must be logged in to reply to this topic. Login to reply