

Introduction
 In my previous article titled "Hierarchies on Steroids #1: Convert an Adjacency List to Nested Sets", we learned a new, high performance method for converting a million node Adjacency List to Nested Sets in less than a minute. The problem with that is all we did was the conversion. We're still left with the tasks of what you might expect to have to do with a hierarchy. For example, the conversion only enables us to calculate the answers to questions of the hierarchy such as how many descendants does each node have? How much were the sales for each node and each level of descendants for each node? What is the grand total of sales for all the descendants for each node? What are the total sales for each level of descendants for just 7 levels (a typical MLM requirement)?
In my previous article titled "Hierarchies on Steroids #1: Convert an Adjacency List to Nested Sets", we learned a new, high performance method for converting a million node Adjacency List to Nested Sets in less than a minute. The problem with that is all we did was the conversion. We're still left with the tasks of what you might expect to have to do with a hierarchy. For example, the conversion only enables us to calculate the answers to questions of the hierarchy such as how many descendants does each node have? How much were the sales for each node and each level of descendants for each node? What is the grand total of sales for all the descendants for each node? What are the total sales for each level of descendants for just 7 levels (a typical MLM requirement)?
While the Nested Sets structure certainly makes it easier to calculate such things, there should be an easier way to answer such questions than writing custom code to handle each node separately. It shouldn't take much more time than the (now fast) conversion to Nested Sets, either.
This article is going to show you how to quickly calculate all those things and more for an entire million node hierarchy… without Nested Sets.
Note that there will never truly be a replacement for Nested Sets especially when you need to list the members of a hierarchy in the correct order or make "drill downs". But we can make it so that you don't need to calculate on-the-fly many of the things that you might interrogate a hierarchy for.
Who This Article is For
This article is for folks who already have at least a basic understanding of hierarchies such as what an Adjacency List is and how it's supposed to be maintained. This article also requires a good understanding of T-SQL and some of the "Black Arts" methods (like the Tally Table, for example) that have been developed by the fine community of DBAs in general.
There is some jargon in this article which was covered in the previous article. For that reason, this article also assumes that you've read and understand the previous article at the following URL: http://www.sqlservercentral.com/articles/Hierarchy/94040/.
Last but not least, there are some stored procedures to build test data that have been brought forward from the previous article and they've been attached in the "Resources" section at the end of this article. How those procs work is well beyond the scope of this article. If you'd like to know more about how they work, the procs themselves contain some heavy documentation that should satisfy your curiosity (and thank you for being curious!).
The Example Hierarchy and Quick Review
If you execute the attached "BuildSmallEmployeeTable" stored procedure with no parameters, it will build an "Employee" table in TempDB that looks like the following sans the Bowers we previously built during the conversion to Nested Sets.
Graphically, it looks like the following.
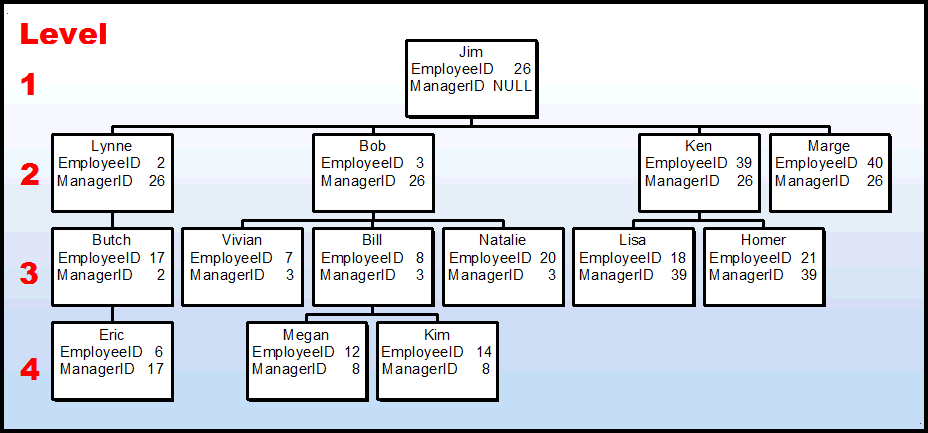
We did the conversion from an Adjacency List to Nested Sets using some high performance code in the form of a stored procedure called "dbo.RebuildNestedSets" which has also been attached.
To summarize that stored procedure, it first ran an rCTE (Recursive CTE) to generate a couple of columns of information we needed to build the Nested Sets and then it ran the following code to actually build the Nested Sets.
--===== Declare a working variable to hold the result of the calculation
-- of the LeftBower so that it may be easily used to create the
-- RightBower in a single scan of the final table.
DECLARE @LeftBower INT
;
--===== Create the Nested Sets from the information available in the table
-- and in the following CTE. This uses the proprietary form of UPDATE
-- available in SQL Serrver for extra performance.
WITH cteCountDownlines AS
( --=== Count each occurance of EmployeeID in the sort path
SELECT EmployeeID = CAST(SUBSTRING(h.SortPath,t.N,4) AS INT),
NodeCount = COUNT(*) --Includes current node
FROM dbo.Hierarchy h,
dbo.HTally t
WHERE t.N BETWEEN 1 AND DATALENGTH(SortPath)
GROUP BY SUBSTRING(h.SortPath,t.N,4)
) --=== Update the NodeCount and calculate both Bowers
UPDATE h
SET @LeftBower = LeftBower = 2 * NodeNumber - HLevel,
h.NodeCount = downline.NodeCount,
h.RightBower = (downline.NodeCount - 1) * 2 + @LeftBower + 1
FROM dbo.Hierarchy h
JOIN cteCountDownlines downline
ON h.EmployeeID = downline.EmployeeID
;One of the things we needed to know to calculate the Bowers (jargon, refer to previous article) of the Nested Sets was the total number of descendants in the downline (jargon, refer to previous article) of each node. The code that actually does that work is the following line of code from above.
NodeCount = COUNT(*) --Includes current nodeThe key to getting that node count was to actually split the SortPath by the Binary(4) EmployeeIDs embedded in the SortPath. The same holds true in the upcoming code.
A More Complex Problem
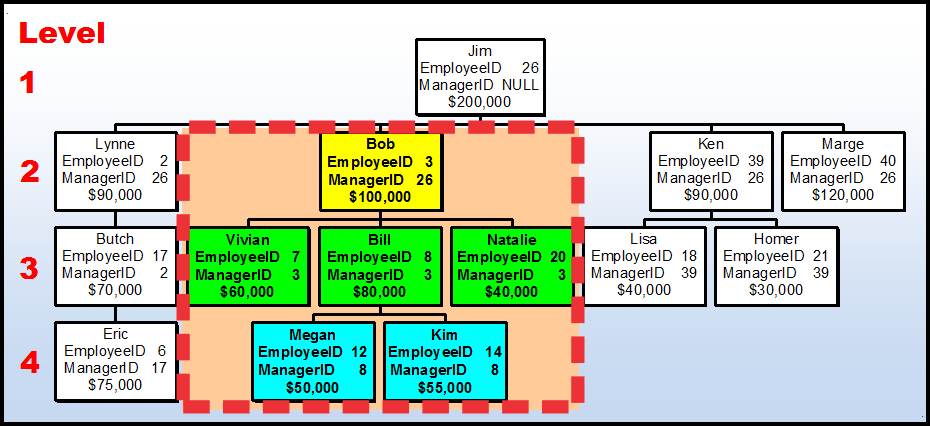
Let’s add some new information to our small Employee table. Let’s add the total sales to each Employee node for a given month (whatever it may be). The small Employee org chart would look like this. Notice that the 4th line in each node is the Total Sales that employee had for a given month.
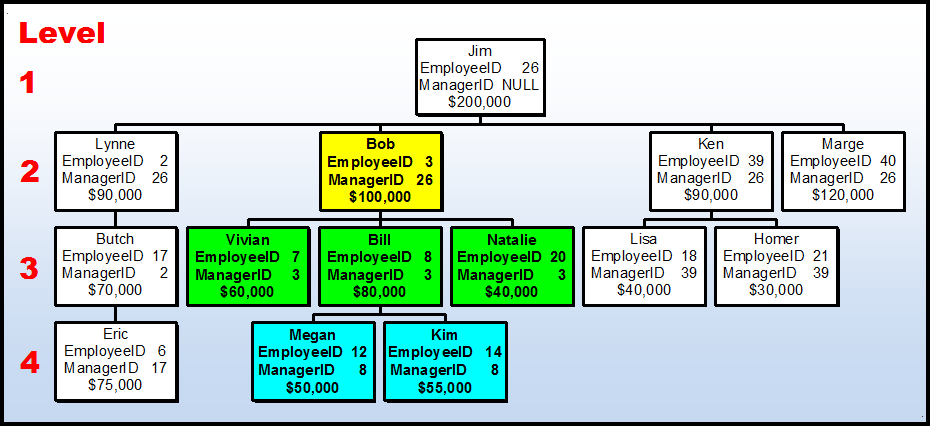
Now, let’s define what we would ordinarily want to do with Nested Sets for such data. I’ve highlighted “Bob” in Yellow because that’s the node we’ll use to explain everything. I’ve also highlighted Bob’s downline in a different color for each level so we can see what happens there, as well. Here’s what we want to calculate in relation to Bob (MLMers are going to love this).
- Calculate the total number of nodes in Bob’s downline including Bob’s node.
- Calculate the total number of nodes for each relative level in Bob’s downline including Bob’s level.
- Calculate the total amount of sales in Bob’s downline including Bob’s node.
- Calculate the total amount of sales for each relative level in Bob’s downline including Bob’s level.
- Calculate the relative level number for each relative level in Bob’s downline including Bob’s level. Bob would have a relative level of 1.
- Calculate the total number of levels in Bob’s downline including Bob’s level.
- Calculate the totals at each level.
There are many other calculations that you could also do such as calculating the % of sales that each level of Bob’s downline has but those are all dependent on the 7 calculations outlined above so I’ll leave those up to you.
The really cool part about these calculations is that we’re going to do them all at once and store the results in what I call a “Pre-Aggregated Hierarchical Table” (some might call it a “data mart”). And, we’re going to do it all in about the same amount of time that it took to calculate Nested Sets.
Step 1: Create the Interim Hierarchy Table
The first thing we need to do is the same first step we took in converting the Adjacency List to Nested Sets. The following code not only copies the Adjacency List to a new table (dbo.Hierarchy), it calculates the quintessential SortPath and HLevel columns using a Recursive CTE (“rCTE” for short). The only changes I made to the code from the first article were to remove the creation of all of the columns associated with the creation of Nested Sets and to add a place holder column for Sales. Everything else is just as before.
--===========================================================================
-- 1. Read ALL the nodes in a given level as indicated by the parent/
-- child relationship in the Adjacency List.
-- 2. As we read the nodes in a given level, mark each node with the
-- current level number.
-- 3. As we read the nodes in a given level, convert the EmployeeID to
-- a Binary(4) and concatenate it with the parents in the previous
-- level’s binary string of EmployeeID’s. This will build the
-- SortPath.
--===========================================================================
--===== Conditionally drop the final table to make reruns easier in SSMS.
IF OBJECT_ID('FK_Hierarchy_Hierarchy') IS NOT NULL
ALTER TABLE dbo.Hierarchy
DROP CONSTRAINT FK_Hierarchy_Hierarchy;
IF OBJECT_ID('dbo.Hierarchy','U') IS NOT NULL
DROP TABLE dbo.Hierarchy;
--===== Build the new table on-the-fly including some place holders
WITH cteBuildPath AS
( --=== This is the "anchor" part of the recursive CTE.
-- The only thing it does is load the Root Node.
SELECT anchor.EmployeeID,
anchor.ManagerID,
HLevel = 1,
SortPath = CAST(
CAST(anchor.EmployeeID AS BINARY(4))
AS VARBINARY(4000)) --Up to 1000 levels deep.
FROM dbo.Employee AS anchor
WHERE ManagerID IS NULL --Only the Root Node has a NULL ManagerID
UNION ALL
--==== This is the "recursive" part of the CTE that adds 1 for each level
-- and concatenates each level of EmployeeID's to the SortPath column.
SELECT recur.EmployeeID,
recur.ManagerID,
HLevel = cte.HLevel + 1,
SortPath = CAST( --This does the concatenation to build SortPath
cte.SortPath + CAST(Recur.EmployeeID AS BINARY(4))
AS VARBINARY(4000))
FROM dbo.Employee AS recur WITH (TABLOCK)
INNER JOIN cteBuildPath AS cte
ON cte.EmployeeID = recur.ManagerID
) --=== This final INSERT/SELECT creates an iterim working table to hold the
-- original Adjacency List, the hierarchal level of each node, and the
-- SortPath which is the binary representation of each node's upline.
-- The ISNULLs make NOT NULL columns
SELECT EmployeeID = ISNULL(sorted.EmployeeID,0),
sorted.ManagerID,
Sales = ISNULL(CAST(0 AS BIGINT),0), --Place Holder
HLevel = ISNULL(sorted.HLevel,0),
SortPath = ISNULL(sorted.SortPath,sorted.SortPath)
INTO dbo.Hierarchy
FROM cteBuildPath AS sorted
OPTION (MAXRECURSION 100) --Change this IF necessary
;
SELECT * FROM dbo.Hierarchy ORDER BY SortPath;Here’s what we get for our efforts.
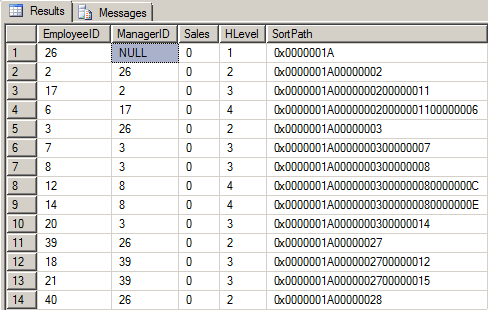
Notice that the original Adjacency List is present in the EmployeeID and ManagerID columns. The SortPath column is the same as it was in the previous article. It contains every EmployeeID from the root Node to the current node from left to right as a Binary(4) (4 byte Hex) representation. We’ve also calculated the level that each node lives in with the Root Node having an HLevel of “1”.
As a bit of a side bar, this type of rCTE isn’t RBAR1 in nature because it processes entire sets of rows for each iteration. The sets are entire levels of nodes. If this were for the millions of parts that go into a 747 (for example), you’d find that there are only 18 or so levels for all those parts and the rCTE would only have to make 18 iterations.
Also notice that we didn’t add any indexes. It turns out that adding an index to the EmployeeID column would actually make the upcoming code run about twice as slow even though we’d get a MERGE JOIN out of it. Do NOT add an index to this interim table! If you intend to keep this table with the Nested Sets calculations (the Left and Right Bowers, etc) in it, add the indexes you'll need AFTER we get done with the rest of the steps below.
Returning to the current code, we’ve also reserved and prefilled a Sales column. Let’s fill that next.
Step 2: Fill in the Sales Data
You’d likely have a separate table for sales by EmployeeID and you’d do an UPDATE to the dbo.Hierarchy table that we created to populate the Sales column with the total for a month (for example). Since that’s not rocket science and I’m sure you already know how to do such a thing, I’m not going to bore you with an example right now (such an example exists in the final code near the end of this article).
I do, however, need to populate this example table with Sales amounts and, since we have so few nodes in the table and I want everyone to have the same data, I’m going to do the update with a little hard-coded data. Here’s the code.
--===== Add an index to expedite the update of Sales data
ALTER TABLE dbo.Hierarchy
ADD PRIMARY KEY CLUSTERED (EmployeeID)
;
--===== Populate the Hierarchy table with curr ent Sales data.
UPDATE h
SET h.Sales = s.Sales
FROM dbo.Hierarchy h
INNER JOIN
(
SELECT 26,200000 UNION ALL
SELECT 2, 90000 UNION ALL
SELECT 3,100000 UNION ALL
SELECT 6, 75000 UNION ALL
SELECT 8, 80000 UNION ALL
SELECT 7, 60000 UNION ALL
SELECT 12, 50000 UNION ALL
SELECT 14, 55000 UNION ALL
SELECT 17, 70000 UNION ALL
SELECT 18, 40000 UNION ALL
SELECT 20, 40000 UNION ALL
SELECT 21, 30000 UNION ALL
SELECT 39, 90000 UNION ALL
SELECT 40,120000
) s (EmployeeID, Sales)
ON h.EmployeeID = s.EmployeeID
;
SELECT * FROM dbo.Hierarchy ORDER BY SortPath
;Here’s what the table looks like now.
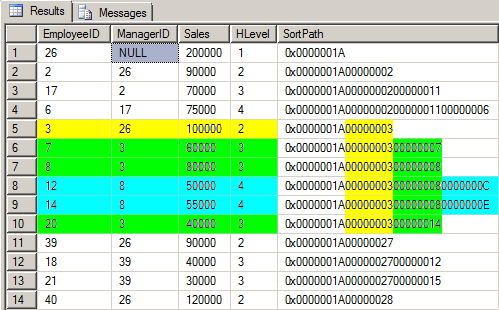
I’ve color-coded the data to match the color coding for Bob and his downline from the org chart. If you look at the SortPath, you can actually see the “Nested Sets” even though we’re not using Nested Sets. Each new level is contained in the previous level from left to right.
Step 3: Calculate Everything
As you can see in the graphic from Step 2, if we split the SortPath by EmployeeID and bring the Sales and HLevel columns along for the ride, we could then aggregate the Sales, the count of the nodes for each node’s downline, and more. We can actually calculate all seven items that we wanted in a single high-performance query.
Once again, this will require the special “HTally” Table that we created in the previous article. It starts at “1” and counts by “4’s” as in 1, 5, 9, 13, etc. These values tell us where the starting position of each EmployeeID is in the SortPath to make splitting out each 4 byte (8 hex characters) EmployeeID an easy task.
The code to build the HTally Table (HTally.sql) is included in the ZIP file in the “Resources” section near the end of this article. Please run that code now.
This step actually has 3 sub-steps that we’ll end up doing using Cascading CTEs (“cCTE” for short).
- Split the EmployeeIDs out of the SortPath and bring each Sales amount and HLevel along for the ride so we can aggregate the sales by HLevel in the next Step.
- Aggregate the sales by EmployeeID and HLevel. We also create and calculate the “Relative Level” (RLevel) for each aggregated level for every EmployeeID in this step.
- Add some sub-totals to the aggregates we created in Step 2 using a filtered ROLLUP. This creates a grand total row for each EmployeeID and forwards the previously calculated sub-totals for each relative level (RLevel).
Step 3, Sub-Step 1: Split the SortPath
The code for this is nearly identical to what we used in the first article. The HTally Table is used to identify the starting position of each EmployeeID in the SortPath and splits out every 4 bytes. The BINARY(4) representation of the EmployeeID is converted to an INT for human readability and to eliminate implicit conversions if we need to join the final table to the original Adjacency List (or any other table) to get things like employee names and the like.
The code also picks up the HLevel and Sales amount so we can aggregate the sales in the next step.
Here’s the code for this sub-step. (Note that each sub-section of code is part of a larger Cascading CTE)
--===== Conditionally drop the final table to make reruns easier in SSMS.
IF OBJECT_ID('dbo.Hierarchy','U') IS NOT NULL
DROP TABLE dbo.PreAggregatedHierarchy
;
WITH
cteSplit AS
(--==== Splits the path into elements (including Sales and HLevel)
-- so that we can aggregate them by EmployeeID and HLevel.
-- Can't aggregate here without including the SortPath so we don't.
SELECT EmployeeID = CAST(SUBSTRING(h.SortPath,t.N,4) AS INT),
h.HLevel, h.Sales
FROM dbo.HTally AS t
CROSS JOIN dbo.Hierarchy AS h
WHERE t.N BETWEEN 1 AND DATALENGTH(SortPath)
),Step 3, Sub-Step 2: Aggregate the Sales by EmployeeID and HLevel
There’s really no magic in this step. It’s a rather straight forward aggregation with a simple GROUP BY. The only “odd” thing that we do here is that we calculate the RLevel by partitioning a simple ROW_NUMBER() by EmployeeID and sort it by the hierarchy level of each level contained in the employee’s downline. We need that column (RLevel) to create sub-totals by relative level in the coming Sub-Step 3.
cteAggregate AS
(--==== Creates the aggregates and introduces the "Relative Level" column.
-- NodeCount = Count of nodes in downline for each EmployeeID by Level
-- Sales = Total Sales in downline for each EmployeeID by Level.
SELECT EmployeeID,
HLevel,
RLevel = ROW_NUMBER() OVER (PARTITION BY EmployeeID
ORDER BY EmployeeID, HLevel),
NodeCount = COUNT(*),
Sales = SUM(CAST(Sales AS MONEY))
FROM cteSplit
GROUP BY EmployeeID, HLevel
)Step 3, Sub-Step 3: Use ROLLUP to Create Sub-Totals by Relative Level
There’s a tiny bit of maybe not-so-obvious magic in this section of the code. We need to bring several columns “forward” from the previous CTE to include them in our final table. The problem is that we don’t actually want to have to include them in the GROUP BY which would not only make the GROUP BY much more complicated, but would also cause the ROLLUP to generate a whole lot of unnecessary rows that we’d just have to throw away.
To get around those problems, we just need to aggregate that which has already been aggregated. Since the HLevel for each EmployeeID is actually unique at this point, we can aggregate even that by using the MIN aggregate function.
The ROLLUP will also create a “grand total” row with a NULL EmployeeID. The total on that row is actually incorrect because it contains the total from all of the repeated rows we’re generating. In other words, each relative level sub-total of one EmployeeID will be included in the sub-totals of EmployeeIDs in the upline of each node causing an incorrect “grand total” calculation by the ROLLUP. In order to keep that row from showing up in the output, we simply convert the NULL EmployeeID that it will have to a “0” and then tell the output to ignore that line by using a HAVING filter to ignore any EmployeeID not having an EmployeeID > 0.
Here’s the code for the final sub-step in this cCTE code.
--===== Adds a "Rollup" to create all the subtotals that we need.
-- We couldn't do this in the previous step because we didn't know what
-- the "Relative Level" was for each row, yet.
-- The HAVING eliminates unnecessary subtotals that are created.
SELECT EmployeeID = ISNULL(a.EmployeeID,0), --Convert NULL total lines to 0
HLevel = MIN(a.HLevel), --Just so we don't have to GROUP BY
RLevel = ISNULL(CAST(a.RLevel AS TINYINT),0),
NodeCount = SUM(a.NodeCount), --Just so we don't have to GROUP BY
Sales = SUM(a.Sales) --Just so we don't have to GROUP BY
INTO dbo.PreAggregatedHierarchy
FROM cteAggregate a
GROUP BY EmployeeID, RLevel WITH ROLLUP
HAVING EmployeeID > 0 --Eliminates the NULL total lines for cleaner output
;Of course, we’d add at least one index that’s critical to performance when using this result table but let’s see what we’ve got in the final “PreAggregateHierarchy” table.
The Result Can Replace the Need for Nested Sets
To keep from having to look back at the beginning of this article, here’s the org chart again with the Sales figures that we used for all of this. I’ve added the Tan color (and a heavy dashed line in contrasting color for my color blind friends) to represent all sales within Bob’s downline including Bob.
And, we can see the first several rows of data that the code we’ve created has produced.
SELECT * FROM dbo.PreAggregatedHierarchy ORDER BY EmployeeID, RLevel;
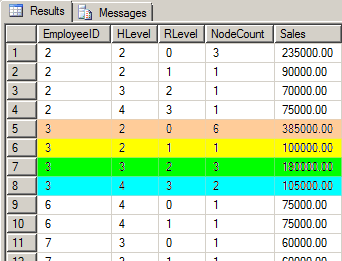
Once again, Bob is EmployeeID 3 and I’ve color coded his rows in the output. Let’s first look at Bob in the Yellow row (line 6 on the far left side). If you look back at the org chart, Bob is at the top of his own downline. Relatively speaking, he’s at Level 1 of his downline and that’s reflected in the RLevel column as "1". For the relative level that Bob is at, he’s the only node at that level and that’s reflected in the NodeCount column. Bob also has a Sales amount of $100,000 which is reflected in the Sales column.
Bob also has two other levels of downline. Vivian, Bill, and Natalie make up the next level in Bob’s downline. Relatively speaking, it’s Bob’s second level and that’s reflected in the RLevel as "2" of the Green row (line 7) for Bob (EmployeeID is still “3” for Bob). Since there are 3 employees in Bob’s second relative level, that’s reflected in the NodeCount as "3" for that row. Those three employees also had sales which total to $180,000 and that’s also reflected in the Sales column of that row.
Bob’s third relative level has 2 people whose Sales total to $105,000 and all of that is reflected in the RLevel, NodeCount, and Sales columns of the Blue row (line 8).
If you take the MAX(RLevel) for Bob (EmployeeID = 3), then you’ll know the total number of levels that Bob has in his downline including himself.
Last but not least, the Tan row (line 5) is the grand total line for Bob’s entire downline. The RLevel is “0” to indicate this is a grand total rather than a total for a relative level. The NodeCount is “6” which is how many nodes there are in Bob’s downline including himself. And, finally, the Sales column contains the grand total of Sales for Bob's entire downline including Bob.
As an artifact that may prove useful, the original hierarchical level for each row is also preserved. For example, what if we wanted to know not only the total sales for the entire hierarchy but also the total sales for the entire hierarchy by Level? You could try to implement CUBE instead of ROLLUP or any of several time consuming and code-lengthy methods or... we could just remember that the Root Node will have all of that information available in it. Since there's no NULL ManagerID in the table to identify the Root Node, you might think that we'd have to join back to the original Adjacency List to find the EmployeeID of the Root Node. Not true! We know there can only be one Root Node and it lives in HLevel 1 all by itself. With that thought in mind, the following extremely simple code (please pardon the "*" for this example) will find the total sales for the entire hierarchy and the total sales for each level in the hierarchy. With the index that we'll add in the final code, the result is almost instantaneous even on a million node hierarchy.
SELECT *
FROM dbo.PreAggregatedHierarchy
WHERE EmployeeID IN
(
SELECT TOP 1 EmployeeID
FROM dbo.PreAggregatedHierarchy
WHERE HLevel = 1
)
ORDER BY HLevel, RLevel;Here are what the results look like from the small Employee table.
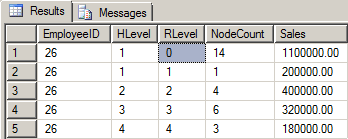
For you MLM’ers in the crowd, calculating monthly payouts according to your level driven qualification and percentage scales becomes the proverbial walk in the park using this type of pre-aggregated hierarchy table. If you have something like a 7 Level Uni-Level payout structure, you would, of course, limit this table to contain only 7 levels per node. Milestone Bonuses will be pretty easy to calculate, as well.
This will also work with “binary” structures although it does absolutely nothing to ensure the binary nature of the hierarchy. You should already have such constraints in place, anyway.
Yeah, but how fast is it?
From the previous article, we found that we could convert a million node Adjacency List to Nested Sets in about 54 seconds. Let’s see how well the code in this article fairs against that. We’ll first build the million node hierarchy, build a million node sales table, and then put all the code together with all the right indexes and see what happens. I’m not going to limit the downline nodes in the final table to 7, either. We’re going for the “full Monty”!
The Test Data
You’ll find a stored procedure in the ZIP file in the “Resources” section near the bottom of this article to build the large Employee hierarchy table with. If you haven’t done so already, open the code for “BuildLargeEmployeeTable” and execute it to build the proc. It all runs in TempDB just to be on the safe side. We don’t want to accidentally drop anyone’s real tables.
Next, run the following code. It will build both the million node “Employee” table and the million row “CurrentMonthlySales” table. It all takes about 11 seconds on my laptop.
--===== Do this in a nice, safe place that everyone has.
USE tempdb
;
--===== Build the million row employee table.
-- This takes about 17 seconds on my laptop and builds the correct
-- indexes, as well. Because of the second parameter, it builds
-- a more realistic hierarchy with randomized EmployeeID's.
EXEC dbo.BuildLargeEmployeeTable 1000000 ,1
;
--===== Conditionally drop the final table to make reruns easier in SSMS.
IF OBJECT_ID('dbo.CurrentMonthlySales','U') IS NOT NULL
DROP TABLE dbo.CurrentMonthlySales
;
--===== Create and randomly populate the new Sales table on-the-fly.
-- Each EmployeeID will have somewhere between $0 and $1,000 of sales.
-- This only takes about 3 seconds on my laptop.
SELECT TOP 1000000
EmployeeID = IDENTITY(INT,1,1),
Sales = ABS(CHECKSUM(NEWID()))%1001
INTO dbo.CurrentMonthlySales
FROM sys.all_columns ac1
CROSS JOIN sys.all_columns ac2
;
--===== Add the expected Clustered Index as a Primary Key
-- This only adds about a second of time to the run.
ALTER TABLE dbo.CurrentMonthlySales
ADD CONSTRAINT PK_CurrentMonthlySales
PRIMARY KEY CLUSTERED (EmployeeID)
;Putting the Code Together
The following could be turned into a stored procedure. It’s all of the code we’ve gone through in this article along with some extra code to add an index that we left out for simplicity’s sake. If you run the following code, it will build the interim “Hierarchy” table (which you could easily convert to a Temp Table, if desired), applies the Sales figures to that from the “CurrentMonthlySales” table we just created above, builds the final “PreAggregatedHierarchy” table, and adds a Clustered Index to the final table.
Here’s the code.
--===== Start a "Timer" to see how long this all takes.
DECLARE @StartTime DATETIME;
SELECT @StartTime = GETDATE();
--===========================================================================
-- 1. Read ALL the nodes in a given level as indicated by the parent/
-- child relationship in the Adjacency List.
-- 2. As we read the nodes in a given level, mark each node with the
-- current level number.
-- 3. As we read the nodes in a given level, convert the EmployeeID to
-- a Binary(4) and concatenate it with the parents in the previous
-- level’s binary string of EmployeeID’s. This will build the
-- SortPath.
--===========================================================================
--===== Conditionally drop the work table to make reruns easier in SSMS.
IF OBJECT_ID('dbo.Hierarchy','U') IS NOT NULL
DROP TABLE dbo.Hierarchy;
--===== Build the new table on-the-fly including some place holders
WITH cteBuildPath AS
( --=== This is the "anchor" part of the recursive CTE.
-- The only thing it does is load the Root Node.
SELECT anchor.EmployeeID,
anchor.ManagerID,
HLevel = 1,
SortPath = CAST(
CAST(anchor.EmployeeID AS BINARY(4))
AS VARBINARY(4000)) --Up to 1000 levels deep.
FROM dbo.Employee AS anchor
WHERE ManagerID IS NULL --Only the Root Node has a NULL ManagerID
UNION ALL
--==== This is the "recursive" part of the CTE that adds 1 for each level
-- and concatenates each level of EmployeeID's to the SortPath column.
SELECT recur.EmployeeID,
recur.ManagerID,
HLevel = cte.HLevel + 1,
SortPath = CAST( --This does the concatenation to build SortPath
cte.SortPath + CAST(Recur.EmployeeID AS BINARY(4))
AS VARBINARY(4000))
FROM dbo.Employee AS recur WITH (TABLOCK)
INNER JOIN cteBuildPath AS cte
ON cte.EmployeeID = recur.ManagerID
) --=== This final INSERT/SELECT creates an iterim working table to hold the
-- original Adjacency List, the hierarchal level of each node, and the
-- SortPath which is the binary representation of each node's upline.
-- The ISNULLs make NOT NULL columns
SELECT EmployeeID = ISNULL(sorted.EmployeeID,0),
sorted.ManagerID,
Sales = ISNULL(CAST(0 AS BIGINT),0), --Place Holder
HLevel = ISNULL(sorted.HLevel,0),
SortPath = ISNULL(sorted.SortPath,sorted.SortPath)
INTO dbo.Hierarchy
FROM cteBuildPath AS sorted
OPTION (MAXRECURSION 100) --Change this IF necessary
;
--===== You'll be tempted to add the following index because it seems so
-- logical a thing to do for performance, but DON'T do it! It will
-- actually slow the rest of the code down by a factor of 2!!!!
--ALTER TABLE dbo.Hierarchy
-- ADD CONSTRAINT PK_Hierarchy PRIMARY KEY CLUSTERED (EmployeeID)
--;
--===== Populate the Hierarchy table with current Sales data.
UPDATE h
SET h.Sales = s.Sales
FROM dbo.Hierarchy h
INNER JOIN dbo.CurrentMonthlySales s
ON h.EmployeeID = s.EmployeeID
;
--===== Conditionally drop the final table to make reruns easier in SSMS.
IF OBJECT_ID('dbo.PreAggregatedHierarchy,'U') IS NOT NULL
DROP TABLE dbo.PreAggregatedHierarchy
;
--===== Now, build "Everything" into the PreAggregatedHierarchy table.
WITH
cteSplit AS
(--==== Splits the path into elements (including Sales and HLevel)
-- so that we can aggregate them by EmployeeID and HLevel.
-- Can't aggregate here without including the SortPath so we don't.
SELECT EmployeeID = CAST(SUBSTRING(h.SortPath,t.N,4) AS INT),
h.HLevel, h.Sales
FROM dbo.HTally AS t
CROSS JOIN dbo.Hierarchy AS h
WHERE t.N BETWEEN 1 AND DATALENGTH(SortPath)
),
cteAggregate AS
(--==== Creates the aggregates and introduces the "Relative Level" column.
-- NodeCount = Count of nodes in downline for each EmployeeID by Level
-- Sales = Total Sales in downline for each EmployeeID by Level.
SELECT EmployeeID,
HLevel,
RLevel = ROW_NUMBER() OVER (PARTITION BY EmployeeID
ORDER BY EmployeeID, HLevel),
NodeCount = COUNT(*),
Sales = SUM(CAST(Sales AS MONEY))
FROM cteSplit
GROUP BY EmployeeID, HLevel
)
--===== Adds a "Rollup" to create all the subtotals that we need.
-- We couldn't do this in the previous step because we didn't know what
-- the "Relative Level" was for each row, yet.
-- The HAVING eliminates unnecessary subtotals that are created.
SELECT EmployeeID = ISNULL(a.EmployeeID,0), --Convert NULL total lines to 0
HLevel = MIN(a.HLevel), --Just so we don't have to GROUP BY
RLevel = ISNULL(CAST(a.RLevel AS TINYINT),0),
NodeCount = SUM(a.NodeCount), --Just so we don't have to GROUP BY
Sales = SUM(a.Sales) --Just so we don't have to GROUP BY
INTO dbo.PreAggregatedHierarchy
FROM cteAggregate a
GROUP BY EmployeeID, RLevel WITH ROLLUP
HAVING EmployeeID > 0 --Eliminates the NULL total lines for cleaner output
;
--===== Add the Clustered Index as a Primary Key
ALTER TABLE dbo.PreAggregatedHierarchy
ADD CONSTRAINT PK_PreAggregatedHierarchy
PRIMARY KEY CLUSTERED (EmployeeID, RLevel) WITH FILLFACTOR = 100
;
--===== Display how long it all took
PRINT 'Duration: ' + CONVERT(CHAR(12),GETDATE()-@StartTime,114) + ' (hh:mi:ss:mmm)';Here are the run results showing the row-counts and the duration.
(1000000 row(s) affected)
(1000000 row(s) affected)
(3231566 row(s) affected)
Duration: 00:01:01:943 (hh:mi:ss:mmm)
Imagine that. Most of the work you would ever need to do in a million node hierarchy is done and stored in a ready-to-lookup pre-aggregated table in about 62 seconds.
Hold the Phone! 3.3 Million Rows? Why?
Where did all the “extra” rows come from in the final table? Remember that each node in the hierarchy can have multiple levels in the downline and that each node also has a “0” level for the grand totals for that node. If you have a million node hierarchy and each node has 7 levels of downline (not actually possible for the nodes nearest the Leaf Nodes or the Leaf Nodes themselves), that would make for an 8 million row table. 1 million for each relative level and 1 million for the “0” level.
Don’t be intimidated by such an expansion of rows or the size of the final table. This is what indexes were created for, to make sure that lookups and other aggregations on such a table will run with blistering speed. And ask anyone in the MLM business. An 8 million row, relatively skinny table is nothing to them. 😉
I Can’t Afford the 62 Seconds of “DownTime”
I hear ya!!! If the final PreaggregatedHierarchy table is the source of information for a 24/7/.999999999 web site or application, then you really can’t afford even the 62 seconds of downtime especially if you’re running a world wide Multi-Level Marketing company! You really don’t want to make any of the members angry with even a minute of “downtime” while you rebuild the table.
So what do you do?
It’s simple. Have a synonym (or pass-through view) pointing at the current version of the pre-aggregated hierarchy table while you build up a new version. Once completed, simply repoint the synonym or view to the new table and drop the old table (or keep it to do monthly comparisons for a month). The total “downtime” is now measured in milli-seconds.
Next month, you do the same thing. Just keep “flip-flopping” the synonym or view between the two tables.
You can even include the building of the Primary Key in an online fashion like this IF you let the system name the PKs for you instead of adding them as a “named constraint”. Adding the other indexes are a piece of cake because index names don’t need to be unique in a database like constraints need to be.
Conclusion
Don’t let this actually be the “conclusion” for you. Whether you decide to go with the high performance conversion of an Adjacency List to Nested sets like we did in the first article, use the pre-aggregated hierarchy table in this article, or some interesting further hybrid of the two, we’ve just scratched the surface on hierarchies and all the things you can do with them.
As you've also seen, the code doesn't need to be complicated or perform poorly just because we have a million rows.
The main purpose of these two articles was to show you that you can have your multi-layered cake (a hierarchy, sorry about the pun) and eat it, too! You CAN enjoy all the quick, easy, and simple maintenance benefits of the Adjacency List and still have gobs of reporting horse-power through Nested Sets and/or the PreAggregated Hierarchy table that you might use instead of Nested Sets.
If you’ve already converted your hierarchy to use just Nested Sets and would really like to enjoy the ease of maintenance realized with an Adjacency List, don’t despair. Just do a web search for “Convert Nested Sets to an Adjacency List”. I haven’t tested any of the methods that you'll find for performance, but they at least look Set Based and should be pretty fast. Besides, you'd only have to do it once. 😉
Last but certainly not least, if you maintain the "dbo.Hierarchy" table as Nested Sets, there's no reason why you can't have the best of 3 worlds by keeping your Adjacency List as before, having the Nested Sets in the "Hierarchy" table, and having all the pre-aggregated answers to most hierarchical questions in the "PreAggregatedHierarchy" table.
Acknowledgements
As with the previous article, this article would not have been possible without some of the knowledge I've gained from several individuals in particular either directly or indirectly. There isn’t room to mention all of them but here’s a few.
First, and once again, when you say “hierarchies in SQL” or “Nested Set”', you have to stand up and salute Joe Celko for the work he's done on the subject over the years. He literally wrote the book on the subject.
I also want to thank Grant Fritchey for the incredible work he’s done in teaching people like me how to read an “execution plan”. I had the honor and privilege of reviewing both of his fine books on dissecting execution plans and they taught me how to figure out what I needed to do and which indexes to add to make otherwise slothful code run at light speed. One of his books is available right here on SQLServerCentral at the following URL. Yes, you can download it for free but if you don’t have the physical book in your library, then I have to tell you that your library just isn’t complete without it.
http://www.sqlservercentral.com/articles/books/65831/
I also want to thank Peter Larsson (aka “Peso”) for the fine work he’s done in teaching people (like me) about “Pre-Aggregation” and some of the tricks I used in bringing various columns forward in a GROUP BY without actually having to group by them. So far as I’m concerned, Peter coined the phrase “Pre-Aggregate” and I’ve used his techniques in many areas where I needed to create high performance aggregations.
Last but not least, I don't know who actually wrote the very first article I ever saw on the use of Numbers Tables (I call them Tally Tables), but thank you for making my life a whole lot easier. Thanks go out to Adam Machanic for first bringing the subject of “Calendar Tables” up which led me to the article on Numbers (Tally) Tables.
Thanks for listening, folks. You’re the best.
--Jeff Moden
1 "RBAR is pronounced "ree-bar" and is a "Modenism" for "Row-By-Agonizing-Row"
© Copyright Jeff Moden, 27 Oct 2012, All Rights Reserved