

This article shows how elementary graph theory can sometimes be used to group records in SQL Server tables more naturally than the GROUP BY operator.
When porting tables from a source database to a target database with a different schema, it is sometimes necessary to group records in a source table so that "virtual" records may be produced that "represent" the members of each group.
For example, if students (and student contacts for them) are ported to a new schema it may be necessary to create a person table so that each record in the former tables has a person associated with it. Students generally have an identification number (so that part is easy) but student contacts often don't. A parent may be a student contact for several students, and each student may have multiple contacts. This typically occurs when the target database has a person table, but the source database does not.
Consider the following student contacts table in the source database (not all columns are shown):
| ID | LAST NAME | FIRST NAME | HOME PHONE | OFFICE PHONE | CELL PHONE | |
| 1 | Doe | Jane | 604 222 2222 | Jane@HOME.COM | ||
| 2 | Doe | Jane | 604 222 2222 | 604 333 3333 | Jane@HOME.COM | |
| 3 | Doe | Jane | 604 333 3333 | 604 444 4444 | Jane@HOME.COM | |
| 4 | Doe | Jane | 604 444 4444 | |||
| 5 | Doe | J | 604 222 2222 | |||
| 6 | Doe | J | J@WORK.COM | |||
| 7 | Doe | J | 604 222 2222 | J@WORK.COM | ||
| 8 | Doe | J | 604 111 1111 | 604 555 5555 |
Here the source database allows contacts to be added for any student, but there's no requirement to assign each contact to a person. Because all columns are entered free-form (no drop-down list of contacts is available, for example) users may enter insufficient, inconsistent or incorrect information to check if two records represent the same person. For example, is J Doe the same person as Jane Doe (or is it her husband John?).
Let's assume that if two contacts have the same LAST NAME and FIRST NAME, and match on at least one of the other columns shown above, then they're the same person. Obviously, if any record A is the same person as record B, and record B is the same person as record C, then record A must be the same person as record C (no actual comparison is needed). So, record 1 and record 4 must be the same person, even though they don't match on anything except their names.
More generally, a pair of records A and B must be the same person if there is a sequence of records R1, R2, …, Rn where A matches R1, R1 matches R2, …, Rn matches B. In other words, if A and B are connected by a path of comparisons leading from one to the other, then they're the same person. It's easy to see that connectivity between two records is an equivalence relation, so it partitions the set of records in a natural way.
This is starting to look like graph theory. Let S be the graph consisting of the set of student contacts (as vertices) where an edge occurs between any two vertices if they match in the above fashion. Then the set of persons for the student contacts may be defined as the set of (maximally) connected subgraphs of S.
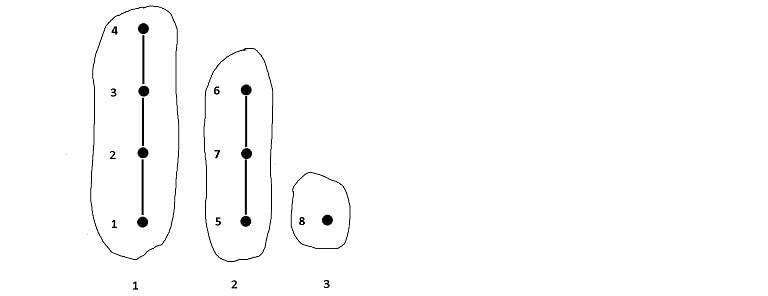
By assigning a number to each connected subgraph, the set of persons becomes a table of numbers to which each student contact may reference by a foreign key:
Here, the connected subgraph 1 represents records 1, 2, 3, 4 while subgraph 2 represents records 5, 6, 7. The remaining record 8 doesn't match with any other record, so it becomes its own subgraph.
To list these numbers, we will first construct the edges connecting the vertices that match, and then use those edges to build the subgraphs. To start, let's assume that the table for the above data is called dbo.Data and that another table called dbo.Edges will be used to list the edges:
| L | R |
| 5 | 7 |
| 1 | 2 |
This table has two columns (left and right vertices) needed to define and store edges between them. Here two edges are listed, representing the matching that occurs on HOME PHONE for adjacent records when dbo.Data is grouped by LAST NAME, FIRST NAME, HOME PHONE. By grouping this way on the remaining columns all edges will be listed:
| L | R |
| 5 | 7 |
| 1 | 2 |
| 2 | 3 |
| 3 | 4 |
| 6 | 7 |
| 1 | 2 |
| 2 | 3 |
The third record represents the LAST NAME, FIRST NAME, OFFICE PHONE grouping.
The fourth record represents the LAST NAME, FIRST NAME, CELL PHONE grouping.
The remaining records represent the LAST NAME, FIRST NAME, EMAIL grouping.
Note that duplicates will occur in this table whenever a pair of records matches on more than one column. They will be removed later.
The procedure for populating dbo.Edges for a given column is the following:
CREATE PROCEDURE [dbo].[spSetUpEdges](
@ColumnName NVARCHAR(128)
)
AS
BEGIN
DECLARE @SQL AS NVARCHAR(MAX)
SET @SQL =
'SET NOCOUNT ON ' +
' ' +
'IF OBJECT_ID(''tempdb..#t'') IS NOT NULL DROP TABLE #t ' +
' ' +
';WITH e AS ' +
'( ' +
' SELECT [ID],[LAST NAME],[FIRST NAME],[HOME PHONE],[OFFICE PHONE],[CELL PHONE],, ' +
' ROW_NUMBER() OVER ' +
' ( ' +
' PARTITION BY [LAST NAME], [FIRST NAME], [' + @ColumnName + '] ORDER BY ID ' +
' ) AS SeqNum ' +
' FROM dbo.Data ' +
') ' +
'SELECT * INTO #t FROM e ' +
'INSERT INTO dbo.Edges ' +
'SELECT t1.ID, t2.ID FROM #t t1 ' +
'INNER JOIN #t t2 ' +
'ON t1.[LAST NAME] = t2.[LAST NAME] and t1.[FIRST NAME] = t2.[FIRST NAME] and t1.[' + @ColumnName + '] = t2.[' + @ColumnName + '] and t1.SeqNum = t2.SeqNum - 1 ' +
'WHERE t1.[' + @ColumnName + '] <> '''' AND t2.[' + @ColumnName + '] <> '''''
exec dbo.sp_executesql @SQL
END
GOBasically, it groups the records by the given column before computing a sequence number within each group by way of the ROW_NUMBER() function. Then the query INNER JOINs on itself by matching each row number with its successor to get adjacent records that match. These are the edges.
For example, the HOME PHONE grouping produces the following dynamically generated insert query:
SET NOCOUNT ON
IF OBJECT_ID('tempdb..#t') IS NOT NULL DROP TABLE #t
;WITH e AS
(
SELECT [ID],[LAST NAME],[FIRST NAME],[HOME PHONE],[OFFICE PHONE],[CELL PHONE],,
ROW_NUMBER() OVER (PARTITION BY [LAST NAME], [FIRST NAME], [HOME PHONE] ORDER BY ID) AS SeqNum
FROM dbo.Data
)
SELECT * INTO #t FROM e
INSERT INTO dbo.Edges
SELECT
t1.ID,
t2.ID
FROM #t t1
INNER JOIN
#t t2
ON
t1.[LAST NAME] = t2.[LAST NAME]
AND
t1.[FIRST NAME] = t2.[FIRST NAME]
AND
t1.[HOME PHONE] = t2.[HOME PHONE]
AND
t1.SeqNum = t2.SeqNum - 1
WHERE
t1.[HOME PHONE] <> '' AND t2.[HOME PHONE] <> ''
To remove duplicates and prepare the data for running the proc that computes the connected subgraphs, the dbo.Edges table is copied to an identical table dbo.Edge with an extra column called E (set to zero):
TRUNCATE TABLE dbo.Edge INSERT INTO dbo.Edge SELECT 0 AS E, L, R FROM dbo.Edges GROUP BY L, R
| E | L | R |
| 0 | 1 | 2 |
| 0 | 2 | 3 |
| 0 | 3 | 4 |
| 0 | 5 | 7 |
| 0 | 6 | 7 |
The column E will be populated with positive integers representing the connected subgraphs by partitioning its edges.
Since we'll be dealing with edges (rather than vertices) when computing connected subgraphs, those vertices not connected to anything will eventually be assigned the negative of their IDs as their own equivalence class, or person. That way, their unique E values won't clash with the computed E values that are always positive numbers.
To compute E for any edge, a simple definition is required. A pair of edges (L1,R1) and (L2,R2) is said to "meet" if they have a common vertex:

That is, L1 = L2 or R1 = R2 or L1 = R2 or R1 = L2
A pair of edges E and F is said to be connected if there is a sequence of edges R1, R2, …, Rn where E meets R1, R1 meets R2, …, Rn meets F.
Computing the E values from the dbo.Edge table may be done as follows:
- If E > 0 for all records, we're done
- Select a record where E = 0
- Compute the smallest integer for E not yet used (say E1)
- Assign it to the selected record, and all records that meet it
- Look for a record where E = 0 but meets a record with the E1 value
- If there are none, go to step 1
- Assign E1 to all records that meet a record with the E1 value
- Go to step 5
In other words, select any edge where E = 0, get the next E value that's not been used, and assign it to the selected edge and all edges connected to it. Repeat until no edge with E = 0 can be found.
The following procedure, spLabelEdges, repeatedly looks for edges that haven't yet been assigned an E value. It also calls a second procedure, spLabelEdge, to assign it, and all edges connected to it, the next available E value.
CREATE PROCEDURE [dbo].[spLabelEdges] AS BEGIN DECLARE @MaxE int DECLARE @L int DECLARE @R int SET NOCOUNT ON UPDATE dbo.Edge SET E = 0 WHILE EXISTS(SELECT 1 FROM dbo.Edge WHERE E = 0) BEGIN SET @MaxE = (SELECT TOP 1 max(E) FROM dbo.Edge) SET @MaxE = @MaxE + 1 SELECT TOP 1 @L = L, @R = R FROM dbo.Edge WHERE E = 0 exec dbo.spLabelEdge @MaxE, @L, @R END END GO
The procedure, spLabelEdge, locates those edges connected to a given edge, and assigns them the passed E value. By dealing with edges (ie. rows of a table) instead of vertices, SQL queries may be employed in a natural way.
CREATE PROCEDURE [dbo].[spLabelEdge](
@Label int,
@L int,
@R int
)
AS
BEGIN
SET NOCOUNT ON
UPDATE dbo.Edge
SET E = @Label
WHERE L = @L
AND R = @R
OR L = @R
OR R = @L
OR L = @L
OR R = @R
WHILE EXISTS( SELECT 1 FROM dbo.Edge d1
WHERE d1.E = 0
AND EXISTS(
SELECT 1 FROM dbo.Edge d2
WHERE d2.E = @Label
AND (d1.L = d2.R
OR d1.R = d2.L
OR d1.L = d2.L
OR d1.R = d2.R
)
)
)
UPDATE d
SET E = @Label
FROM
(
SELECT * FROM dbo.Edge d1
WHERE d1.E = 0
AND EXISTS(SELECT 1 FROM dbo.Edge d2
WHERE d2.E = @Label
AND (d1.L = d2.R OR d1.R = d2.L OR d1.L = d2.L OR d1.R = d2.R)
)
) d
END
GOFinally, join the dbo.Data table with dbo.Edge to pick up the E values (along with a value of -ID for any records not meeting any others):
SELECT DISTINCT d2.E, d1.[ID], d1.[LAST NAME], d1.[FIRST NAME] FROM dbo.Data d1 INNER JOIN dbo.Edge d2 ON d1.ID = d2.L OR d1.ID = d2.R UNION SELECT -d1.[ID] AS E, d1.[ID], d1.[LAST NAME], d1.[FIRST NAME] FROM dbo.Data d1 LEFT OUTER JOIN dbo.Edge d2 ON d1.ID = d2.L OR d1.ID = d2.R WHERE d2.L IS NULL OR d2.R IS NULL
| E | ID | LAST NAME | FIRST NAME |
| -8 | 8 | Doe | J |
| 1 | 1 | Doe | Jane |
| 1 | 2 | Doe | Jane |
| 1 | 3 | Doe | Jane |
| 1 | 4 | Doe | Jane |
| 2 | 5 | Doe | J |
| 2 | 6 | Doe | J |
| 2 | 7 | Doe | J |
The values in column E may be viewed as the IDs of those "persons" just created and assigned to the student contacts.
This article shows how connected subgraphs can be used to group records in a table where multiple columns are used to compare them independently (instead of the usual grouping that employs all of them each time).
The scripts for this example may be in the Resources section below. The script for this example is also shown here:
-- No counting SET NOCOUNT ON -- Populate dbo.Data TRUNCATE TABLE dbo.Data INSERT INTO dbo.Data(ID,[LAST NAME],[FIRST NAME],[HOME PHONE],[OFFICE PHONE],[CELL PHONE],EMAIL) VALUES(1,'Doe','Jane','604 222 2222',NULL,NULL,'Jane@ABC.COM') INSERT INTO dbo.Data(ID,[LAST NAME],[FIRST NAME],[HOME PHONE],[OFFICE PHONE],[CELL PHONE],EMAIL) VALUES(2,'Doe','Jane','604 222 2222','604 333 3333',NULL,'Jane@ABC.COM') INSERT INTO dbo.Data(ID,[LAST NAME],[FIRST NAME],[HOME PHONE],[OFFICE PHONE],[CELL PHONE],EMAIL) VALUES(3,'Doe','Jane',NULL,'604 333 3333','604 44444','Jane@ABC.COM') INSERT INTO dbo.Data(ID,[LAST NAME],[FIRST NAME],[HOME PHONE],[OFFICE PHONE],[CELL PHONE],EMAIL) VALUES(4,'Doe','Jane',NULL,NULL,'604 44444',NULL) INSERT INTO dbo.Data(ID,[LAST NAME],[FIRST NAME],[HOME PHONE],[OFFICE PHONE],[CELL PHONE],EMAIL) VALUES(5,'Doe','J','604 222 2222',NULL,NULL,NULL) INSERT INTO dbo.Data(ID,[LAST NAME],[FIRST NAME],[HOME PHONE],[OFFICE PHONE],[CELL PHONE],EMAIL) VALUES(6,'Doe','J',NULL,NULL,NULL,'J@WORK.COM') INSERT INTO dbo.Data(ID,[LAST NAME],[FIRST NAME],[HOME PHONE],[OFFICE PHONE],[CELL PHONE],EMAIL) VALUES(7,'Doe','J','604 222 2222',NULL,NULL,'J@WORK.COM') INSERT INTO dbo.Data(ID,[LAST NAME],[FIRST NAME],[HOME PHONE],[OFFICE PHONE],[CELL PHONE],EMAIL) VALUES(8,'Doe','J',NULL,'604 111 1111','604 555 5555','') -- Populate dbo.Edges using matching records in dbo.Data -- Duplicate records will occur when records match on multiple criteria TRUNCATE TABLE dbo.Edges exec dbo.spSetUpEdges 'HOME PHONE' exec dbo.spSetUpEdges 'OFFICE PHONE' exec dbo.spSetUpEdges 'CELL PHONE' exec dbo.spSetUpEdges 'EMAIL' -- Insert unique records from dbo.Edges into dbo.Edge TRUNCATE TABLE dbo.Edge INSERT INTO dbo.Edge SELECT 0 AS E, L, R FROM dbo.Edges GROUP BY L, R -- Label records in dbo.Edge with E values exec dbo.spLabelEdges -- Group records in dbo.Data using labels in dbo.Edge and join them to remaining records SELECT DISTINCT d2.E, d1.[ID], d1.[LAST NAME], d1.[FIRST NAME] FROM dbo.Data d1 INNER JOIN dbo.Edge d2 ON d1.ID = d2.L OR d1.ID = d2.R UNION SELECT -d1.[ID] AS E, d1.[ID], d1.[LAST NAME], d1.[FIRST NAME] FROM dbo.Data d1 LEFT OUTER JOIN dbo.Edge d2 ON d1.ID = d2.L OR d1.ID = d2.R WHERE d2.L IS NULL OR d2.R IS NULL