

Introduction
When you see high CPU and the query plan says "parallelism," one of the first suspects is CXPACKET. Since SQL Server 2016 SP2, Microsoft split this into two wait types: cxconsumer and cxpacket. These are critical for understanding whether your server is suffering from parallelism inefficiencies or just synchronizing threads as expected. This blog demonstrates how to simulate both waits, how to capture them live, and how to determine which part of your execution plan is to blame.
This article walks through how to simulate both waits—CXCONSUMER and CXPACKET—under controlled conditions. We’ll first demonstrate how CXCONSUMER arises when a query plan includes a Gather Streams operator, typically involving the coordinator thread waiting for results. Then we’ll simulate real CXPACKET waits by introducing thread imbalance through a skewed join condition. Finally, we’ll show how to monitor worker threads and execution context IDs in real time, so you can pinpoint exactly where the parallel plan is stalling.
We’ll also explore how seemingly harmless operations—like modulus-based joins often written by developers without a second thought—can silently introduce thread imbalances. These patterns trigger repartitioning under the hood, sometimes leading to unexpected CXPACKET waits. The good news? You don’t need to rewrite your business logic. With a few targeted adjustments, you can guide SQL Server toward smarter parallel plans. If you’ve ever wondered why your 16-core box feels sluggish despite low query counts, this is the deep dive that reveals what’s really happening behind the scenes.
Preparing the Test Setup
This query builds a synthetic table called TestCX with around 120 million rows. We use a series of CROSS JOINs between small constant rowsets to explosively generate volume. Each level in the CTE doubles the row count, and by the time we reach alias f, the cross joins have scaled up significantly.
The IDENTITY(INT,1,1) column provides a sequential primary key for use in joins and expressions. The REPLICATE('A', 100) adds a fixed-length character column to inflate row size slightly, ensuring that SQL Server considers the dataset large enough to justify parallel execution.
We use TOP (120000000) to cap the row count but still keep it large enough to engage the optimizer’s costing model and force parallelism in subsequent queries. This setup is intentionally oversized to make sure that even simple aggregations or joins will trigger a multi-threaded plan. Without sufficient row volume, SQL Server might fall back to serial execution—even with MAXDOP set.
We’ll use this table across all upcoming simulations, from basic CXCONSUMER patterns with Gather Streams, to full-blown CXPACKET scenarios using repartition and hash joins.
Simulating CXCONSUMER Waits
This query triggers a parallel plan using a GROUP BY on a computed expression. The use of CHECKSUM and the bitwise XOR operation (id ^ 1234567) ensures there’s no usable index, forcing SQL Server to fully scan and group the data without relying on index seek shortcuts. The ^ symbol is a bitwise XOR operator—it flips specific bits in the number and creates a new hash-like value. We use it here to subtly alter the distribution of values so that SQL Server doesn't treat all rows identically. This variation prevents the optimizer from collapsing the parallel plan into a serial one.
In this query, we combine XOR with a CASE expression to generate minor variations across rows—enough to simulate real-world grouping scenarios without causing extreme skew. The grouping remains relatively balanced, so all parallel threads complete their work at similar times.
The Parallelism (Gather Streams) operator appears at the root of the plan. Its job is to merge the outputs of all worker threads into one unified stream, handled by the coordinator thread (exec_context_id = 0). That thread waits until all workers are done, which is why it shows a CXCONSUMER wait.
Bitwise XOR like this is also used in hashing, randomisation, and even lightweight obfuscation scenarios—so it's not just for query tricks. Here, it helps create a predictable but unindexed grouping pattern that reliably triggers parallelism.
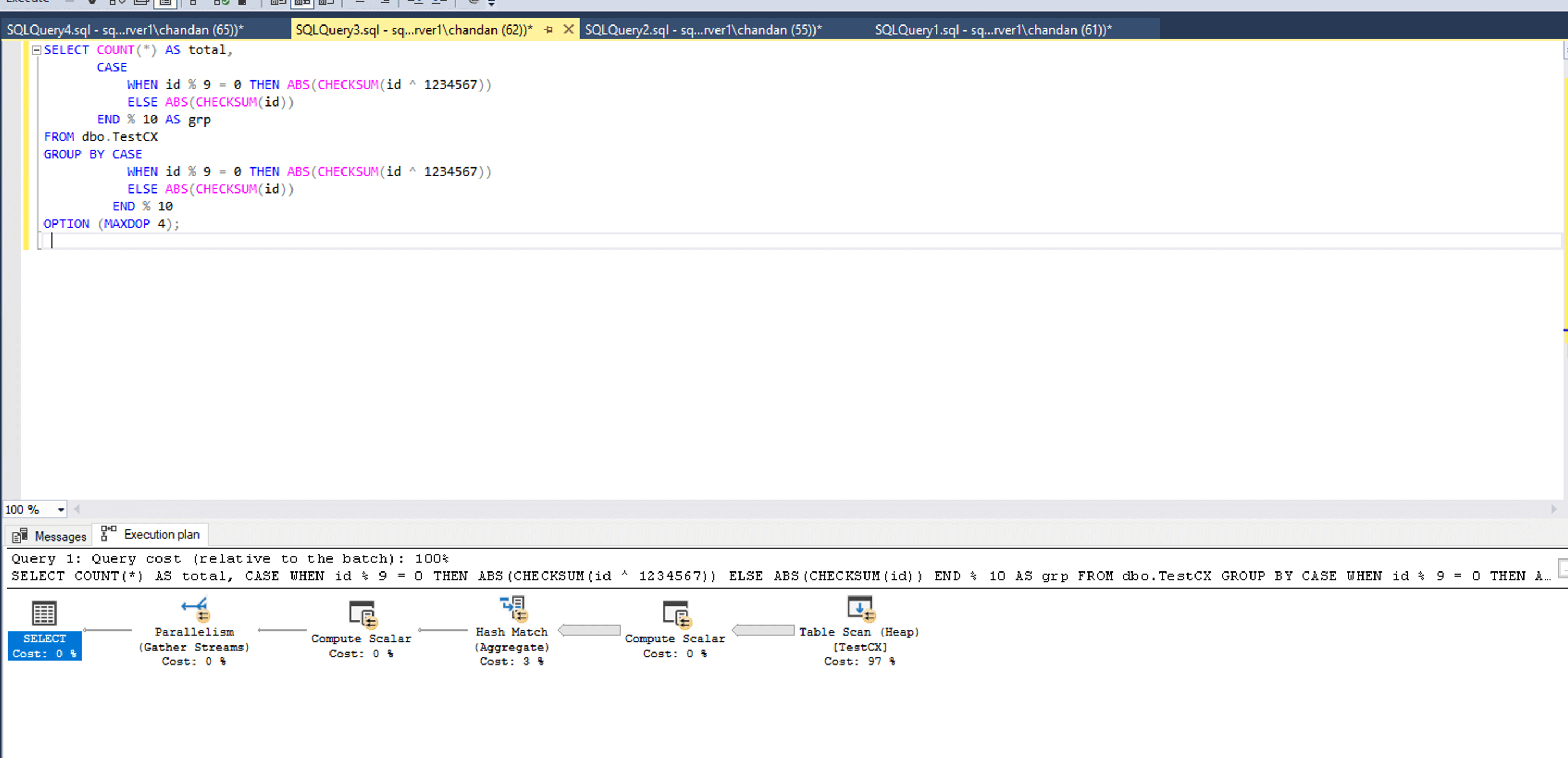 Gather Streams cause coordination thread CXCONSUMER wait
Gather Streams cause coordination thread CXCONSUMER waitVerifying Waits in Real-Time of CXCONSUMER
In a second window, validate the CXCONSUMER waits caused due to Gather Stream operator, as depicted in above execution plan :
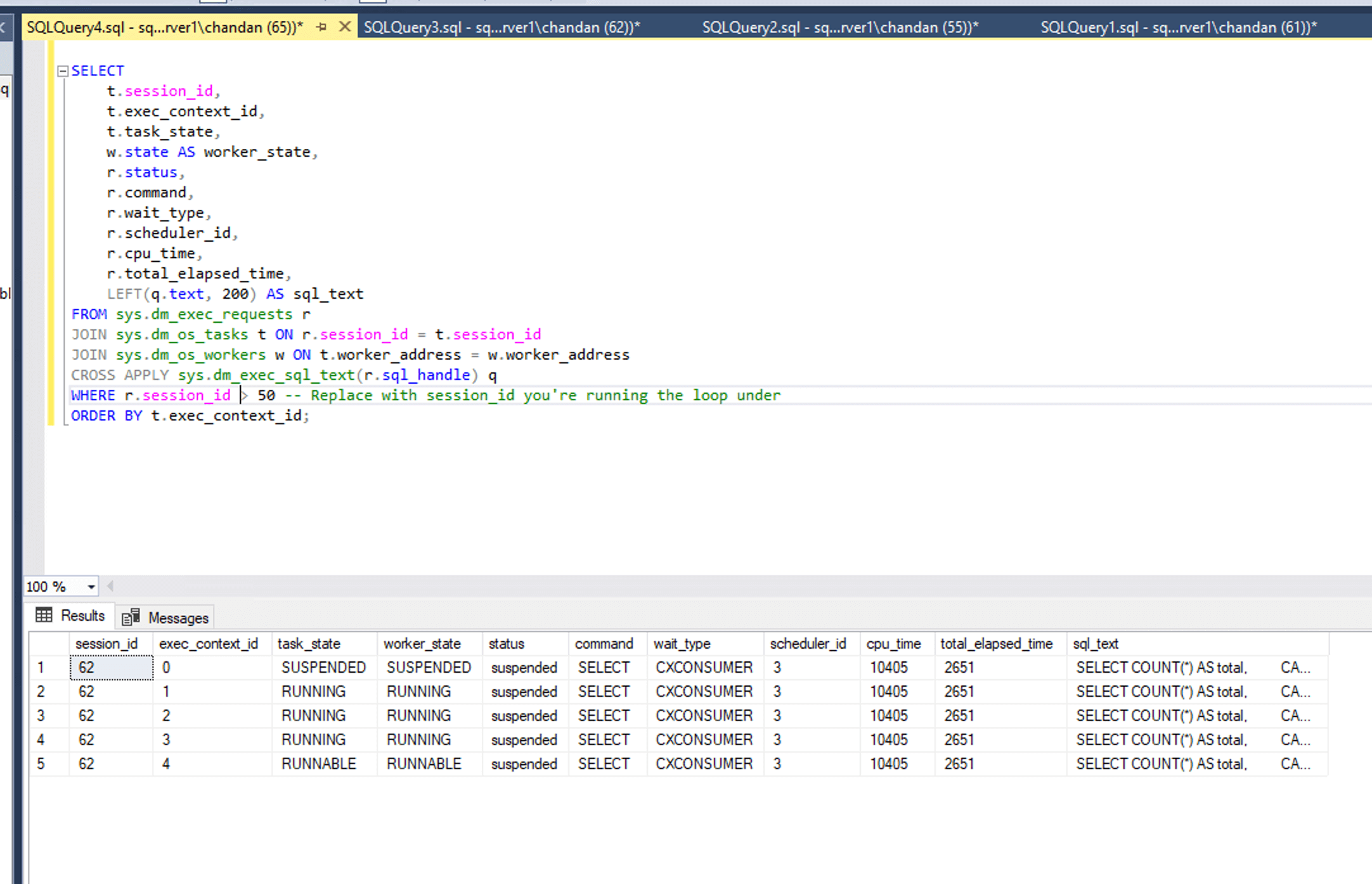 All worker threads having CXConsumer wait type for Query 2
All worker threads having CXConsumer wait type for Query 2Only CXCONSUMER appears—even for worker threads—because the bottleneck is at the final “gather streams" operator as per execution plan.
Simulating CXPACKET Waits
This query performs a parallel hash join using a.id % 200 = b.id % 200, which forces SQL Server to introduce a Repartition Streams operator. It redistributes rows by join key across threads. If one thread gets a heavier bucket, it lags behind while others finish early.
Those faster threads are forced to wait at the exchange point—this is where CXPACKET shows up. The ORDER BY adds a final Gather Streams, causing the coordinator thread to show CXCONSUMER. Together, these waits reveal both thread imbalance and synchronization pressure. On this dataset, the query took over 10 minutes.
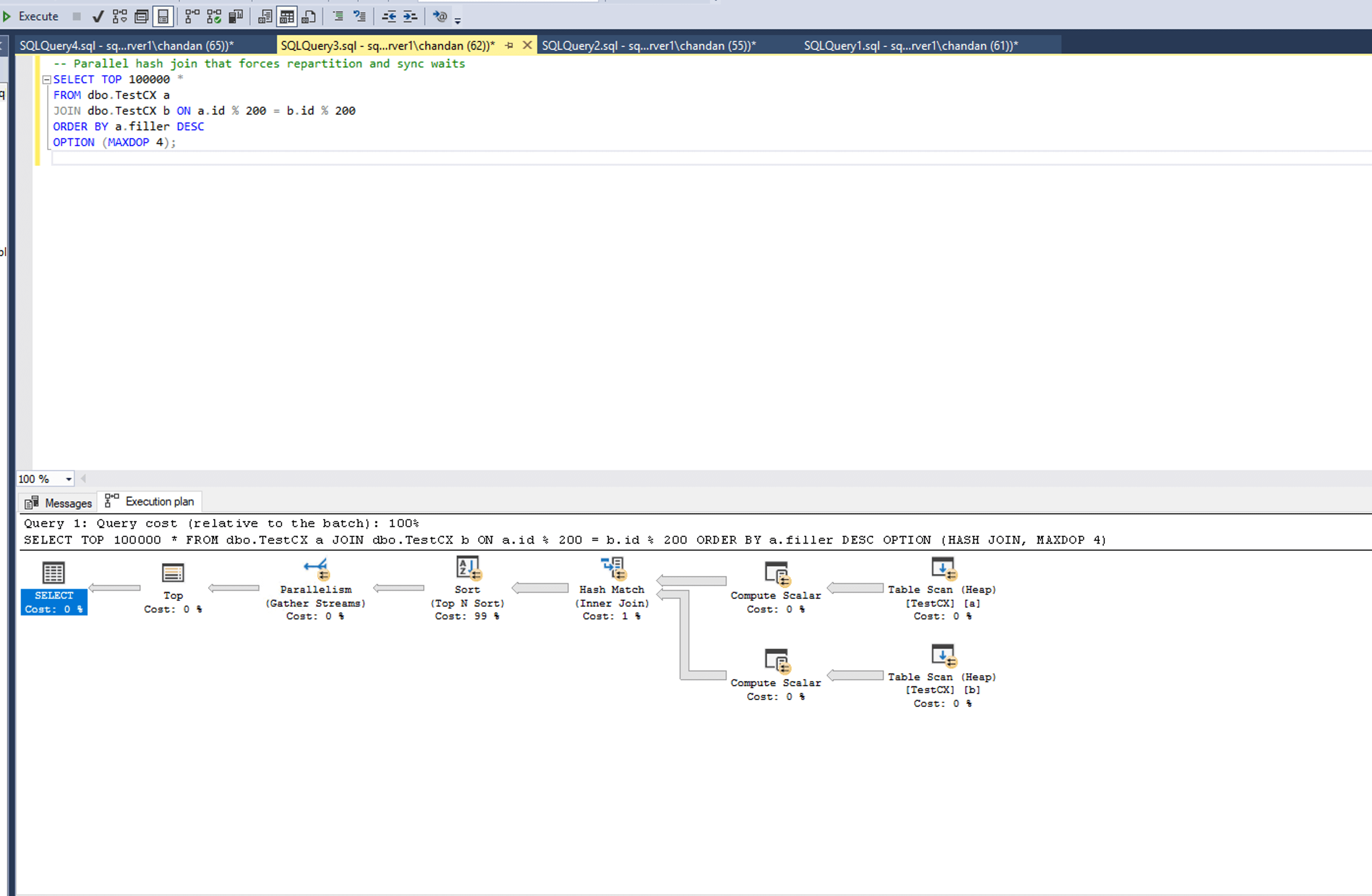 CXPACKET wait type introduced due to HASH Match on a large dataset
CXPACKET wait type introduced due to HASH Match on a large datasetRepartition Streams causes rows to be redistributed by join key. If some buckets are heavier (due to uneven id % 200 values), some threads finish late. Others? They wait—resulting in CXPACKET.
Verifying Waits in Real-Time of CXPacket
Use the same query(Query 2) to confirm CXPacket wait on all worker threads.
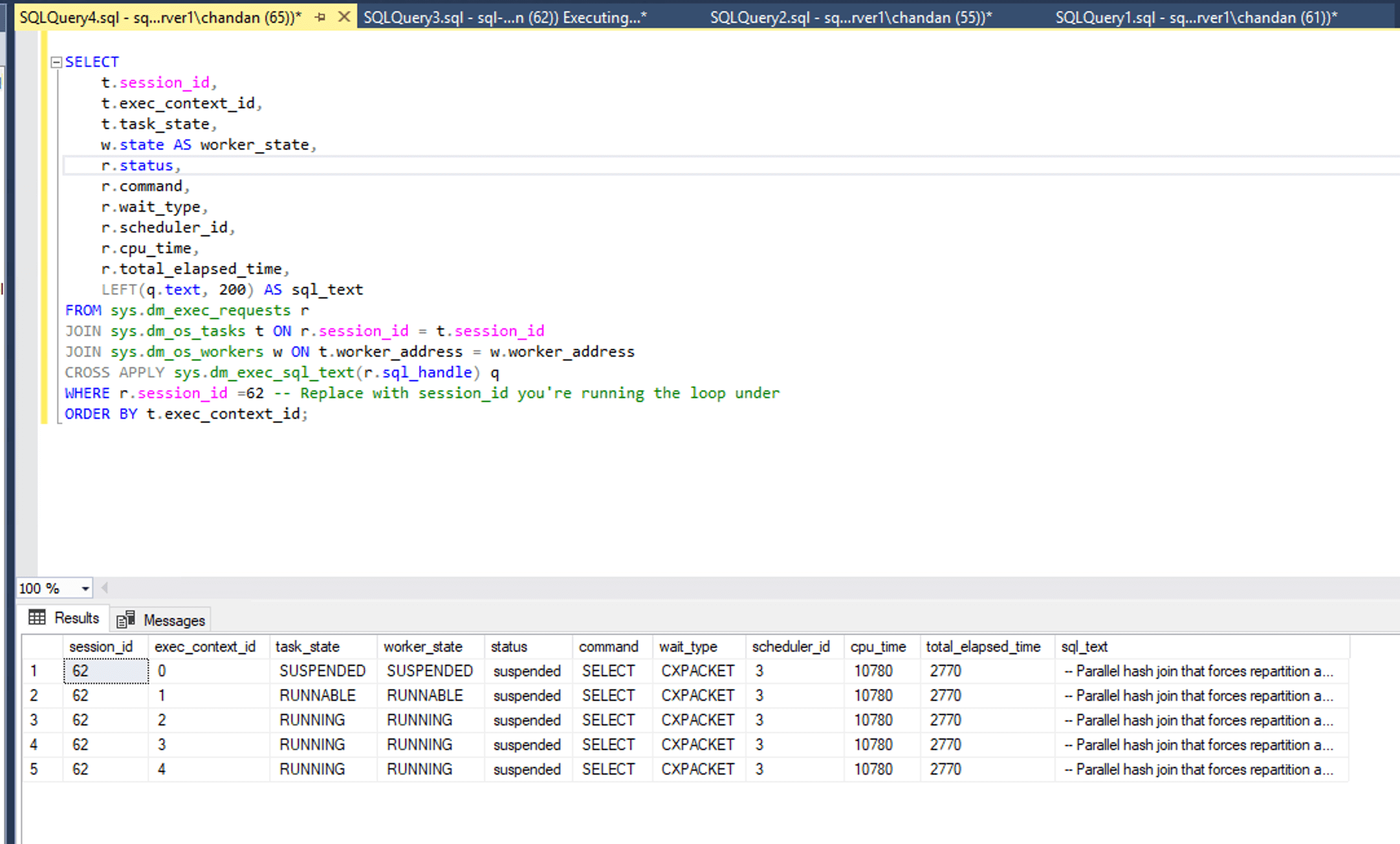 All worker threads causing CXPACKET wait for Query 4
All worker threads causing CXPACKET wait for Query 4How to Fix Without Changing Logic CXPacket and CXConsumer wait
Instead of rewriting the core logic, we can guide the optimizer by adding calculated metadata and indexing it effectively. For example, in Query 3, we used id % 200 as a join condition—which is simple but not index-friendly. To help SQL Server execute this join more efficiently without changing the logic, we can add a computed column that captures this expression and persist it.
We start by adding a computed column to materialize the modulus operation Add an index:
The estimated execution plan shows an index seek instead of a scan, and the query runtime drops dramatically—from over 10 minutes to under 1 second. This reduces the overall cost and minimizes unnecessary parallelism, helping mitigate CXPACKET waits.
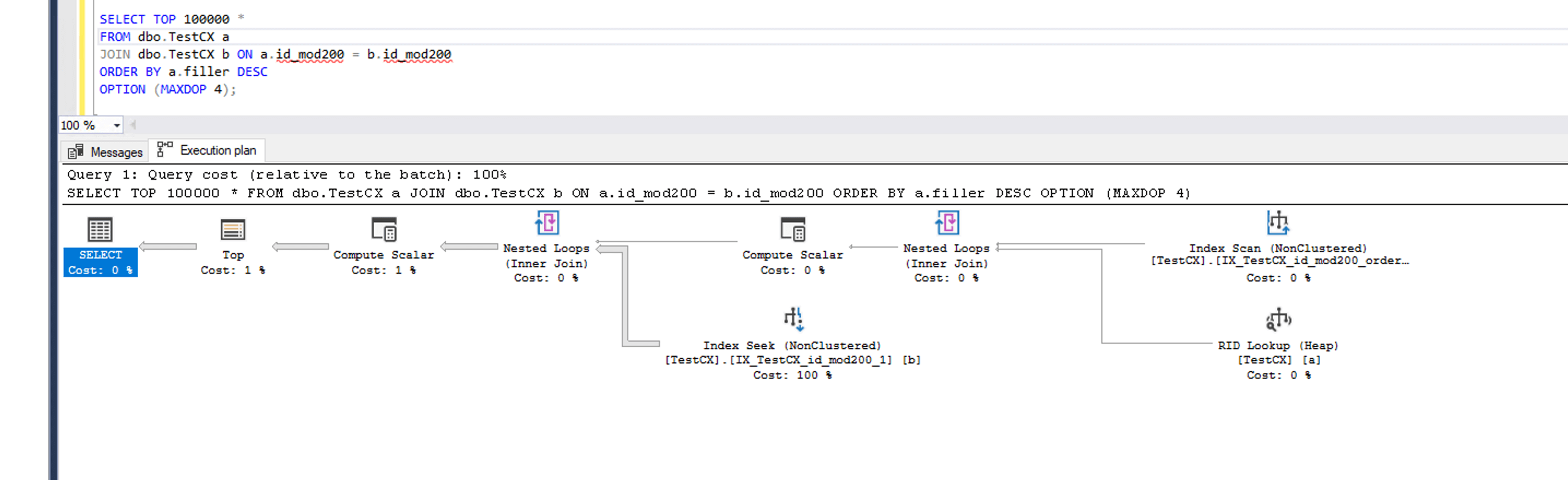 Query plan of query causing CXPACKET wait after optimisation
Query plan of query causing CXPACKET wait after optimisationAs a DBA working with production workloads on high-core servers, I’ve seen both CXPACKET and CXCONSUMER show up in query wait profiles—but in ways that don’t always tell the full story at first glance. In one case, a data warehouse workload had heavy reports that aggregated millions of rows. Parallelism kicked in as expected, but the query would randomly jump from a 10-second run to over a minute with no changes to the logic or input.
Looking at the waits, sometimes it was CXPACKET, other times just CXCONSUMER. At first, it seemed like a harmless coordination delay—just the gather thread waiting. But after digging into the execution context IDs, it became clear: when CXPACKET showed up, one or more worker threads had finished early and were waiting at a Repartition Streams or hash join. When only CXCONSUMER appeared, it was often the coordinator thread sitting idle—but still because one of the workers was slow or overloaded.
So, both waits told part of the truth. The presence of CXPACKET didn’t always mean a serious problem, and the absence of it didn’t mean everything was fine either. They surfaced based on where in the plan the query was waiting. Hash joins, sort operators, and parallel aggregations—especially on skewed data—were common culprits. One night I found a query that used id % 128 in a join condition. Looked innocent. But it led to thread imbalance and showed CXPACKET on one node, CXCONSUMER on another. The only way to spot the real delay was by checking actual execution stats per thread.
Conclusion
Parallelism in SQL Server isn’t bad. But unmanaged parallelism causes threads to wait—either to sync (CXPACKET) or to feed the coordinator (CXCONSUMER). Both are natural, but only one signals real trouble. Understanding how to provoke, detect, and fix them can turn your execution plan from a minefield into a well-oiled machine. Monitor worker threads, check repartition hotspots, and know that not all CXCONSUMER waits are innocent.
For more tutorials authored by me visit my sql server central profile page: https://www.sqlservercentral.com/forums/user/shuklachandan12
References
