

In the era of data-driven decision-making, the ability to efficiently analyze and derive insights from time-series data is of paramount importance. Apache Druid, a cutting-edge open-source data store and analytics platform, has emerged as a compelling solution for organizations seeking to harness the power of time-series data. Apache Druid, often referred to simply as "Druid," is an innovative data warehousing and analytics tool designed to excel in the analysis of time-series and event-driven data. Unlike traditional databases and data warehouses, Druid was purpose-built from the ground up to tackle the unique challenges posed by time-series data.
What Makes Apache Druid Special?
What sets Druid apart is its ability to deliver real-time data analytics at scale. Whether you're dealing with IoT sensor data, website clickstreams, financial transactions, or log data, Druid's architecture empowers organizations to ingest, store, and query massive volumes of time-stamped data with astonishing speed and precision.
Apache Druid distinguishes itself from other time-series data warehouses through several key advantages:
- Real-Time Ingestion and Querying: Druid excels at handling real-time data streams, allowing you to make decisions based on the freshest information available.
- High Query Performance: Druid's columnar storage and indexing techniques enable lightning-fast query response times, even when dealing with vast data sets.
- Scalability: Druid's architecture is designed for horizontal scalability, ensuring it can grow with your data needs.
- Data Aggregation During Ingestion: Druid aggregates data during ingestion, reducing the workload on query execution and optimizing query performance.
- Versatile Query Language: Druid offers a SQL-like query language that simplifies data exploration and analysis.
- Open-Source Community: Being an open-source project, Druid benefits from a vibrant community of contributors and users, providing a wealth of resources and support.
In this document, we will delve deeper into time-series data analysis with Druid, exploring its capabilities with a simple example. Whether you're a data engineer, analyst, or decision-maker, Druid's potential to unlock real-time insights from your time-series data is a compelling proposition worth exploring.
Data Ingestion with Apache Druid
In Apache Druid, data ingestion is the pivotal first step in the journey of unlocking valuable insights from time-series data. Druid provides a wealth of options for ingesting data from various sources and formats, making it a versatile choice for handling diverse data sets. In this section, we'll explore the supported formats, data sources, and types of data ingestion available in Druid. Additionally, we'll provide a step-by-step process for data ingestion, complete with a CSV example.
A range of data formats is supported, including:
- JSON: Ideal for semi-structured or nested data.
- CSV: Suitable for structured data with tabular formats.
- Apache Avro: A compact, binary data format.
- Apache Parquet: A columnar storage format, well-suited for analytical queries.
- Apache ORC: Another columnar storage format is known for high performance.
- Thrift: A cross-language, binary protocol.
These formats cater to various data types and use cases, allowing flexibility in data preparation and ingestion.
Ingest data from diverse sources, including:
- Local Files: Data can be ingested from files stored on the local file system.
- Cloud Storage: You can ingest data from cloud storage solutions like Amazon S3, Google Cloud Storage, or Azure Blob Storage.
- Message Queues: Druid provides native integration with Apache Kafka, enabling real-time data streaming ingestion.
- Databases: Druid can ingest data from relational databases, NoSQL databases, and other data stores using custom connectors.
- HTTP Endpoints: Data can be ingested from HTTP endpoints by providing the data source URL.
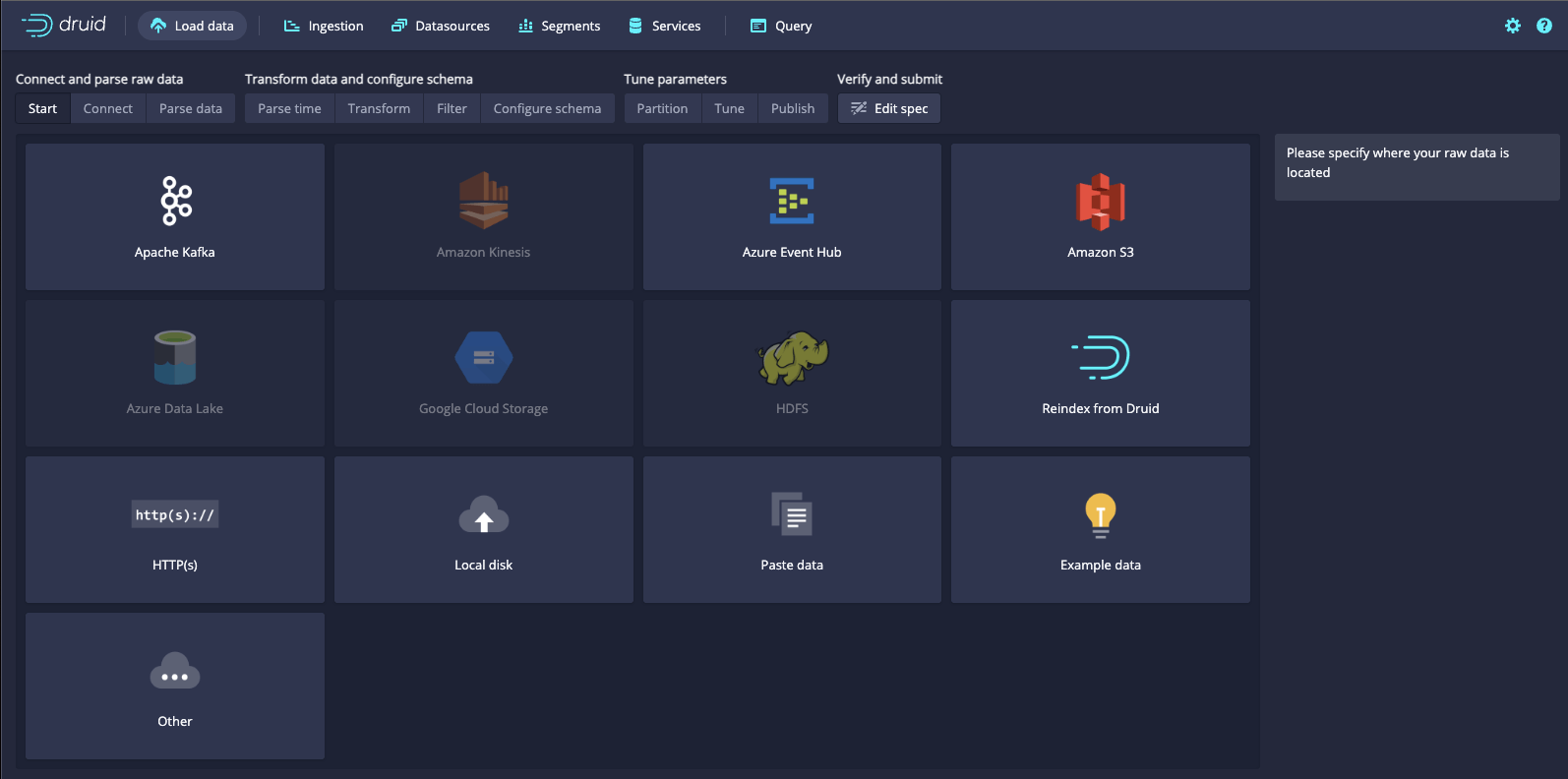
Apache Druid offers two primary types of data ingestion:
- Batch Ingestion: Batch ingestion is suitable for processing static or historical data. It involves ingesting data from fixed data sources and processing it in batches. This is an excellent choice when dealing with historical logs, archived data, or data that does not require real-time analysis.
- Real-Time Ingestion: Real-time ingestion is designed for handling dynamic, constantly evolving data streams. It allows you to ingest data as it arrives, making it ideal for use cases such as monitoring, event processing, and real-time analytics. Apache Kafka is commonly used as a source for real-time data streams in Druid.
Step-by-Step Data Ingestion with a CSV Example
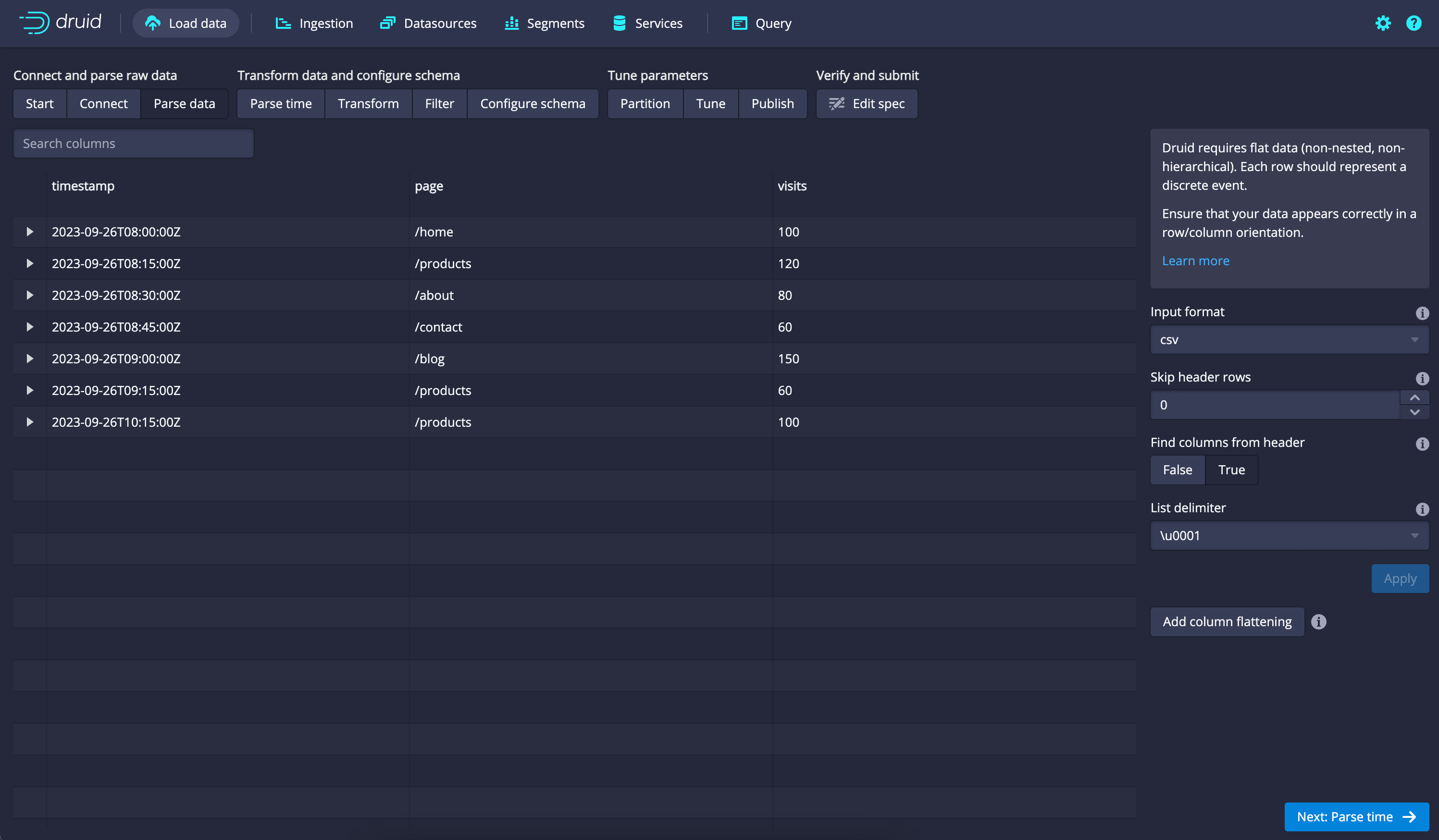
Let's walk through a simplified example of batch data ingestion using a CSV file containing website traffic data:
timestamp,page,visits 2023-09-26T08:00:00Z,/home,100 2023-09-26T08:15:00Z,/products,120 2023-09-26T08:30:00Z,/about,80 2023-09-26T08:45:00Z,/contact,60 2023-09-26T09:00:00Z,/blog,150 2023-09-26T09:15:00Z,/products,60 2023-09-26T10:15:00Z,/products,100
Here are the basic steps for ingesting this data into Apache Druid:
- Ingest Data:
- Select "Upload a file" or "Paste data" depending on your preference. For this example, we'll use "Paste data."
- Copy and paste your sample CSV data into the text area.
- You can set additional configuration options such as specifying the delimiter and defining a parser if necessary.

- Define Schema:
- In the "Define your schema" section, Druid will automatically detect your CSV header and suggest a schema. Make sure the schema matches your data correctly. You can make adjustments if needed.
- Parse Timestamp:
- For Druid to recognize the timestamp field, ensure that the "Timestamp" dropdown menu is set to "timestamp" in the schema definition. Druid will attempt to parse the timestamp format based on your data.
- For Druid to recognize the timestamp field, ensure that the "Timestamp" dropdown menu is set to "timestamp" in the schema definition. Druid will attempt to parse the timestamp format based on your data.
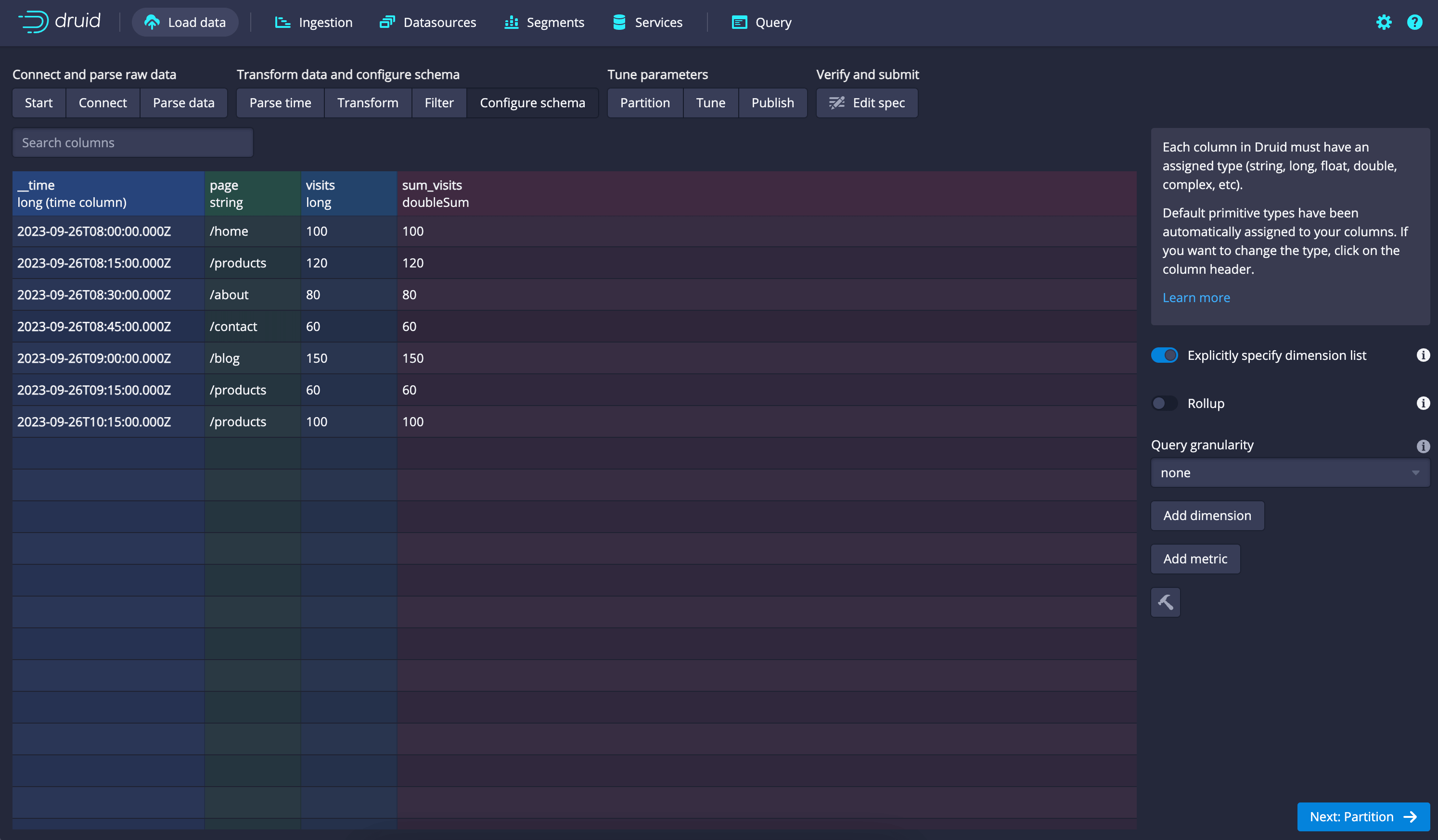
- Dimensions and Metrics:
- In the "Dimensions" section, add "page" as a dimension.
- In the "Aggregators" section, add "visits" as a metric. Set the aggregator type to "longSum" and select the "visits" column.
- Configure Ingestion Settings:
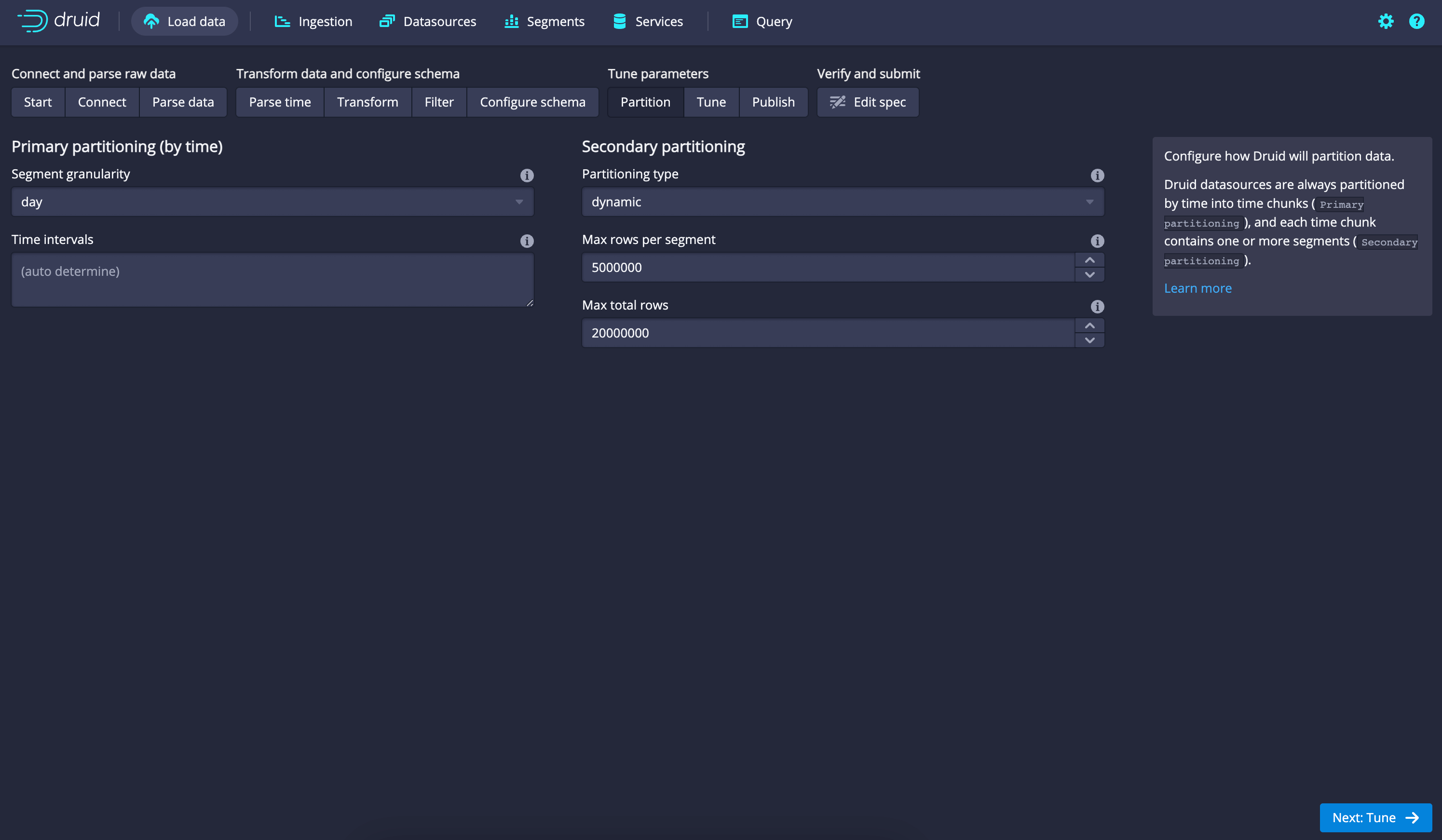
- Configure ingestion settings such as Segment granularity, the interval for data ingestion, and any additional properties as required for your use case.
- Configure ingestion settings such as Segment granularity, the interval for data ingestion, and any additional properties as required for your use case.
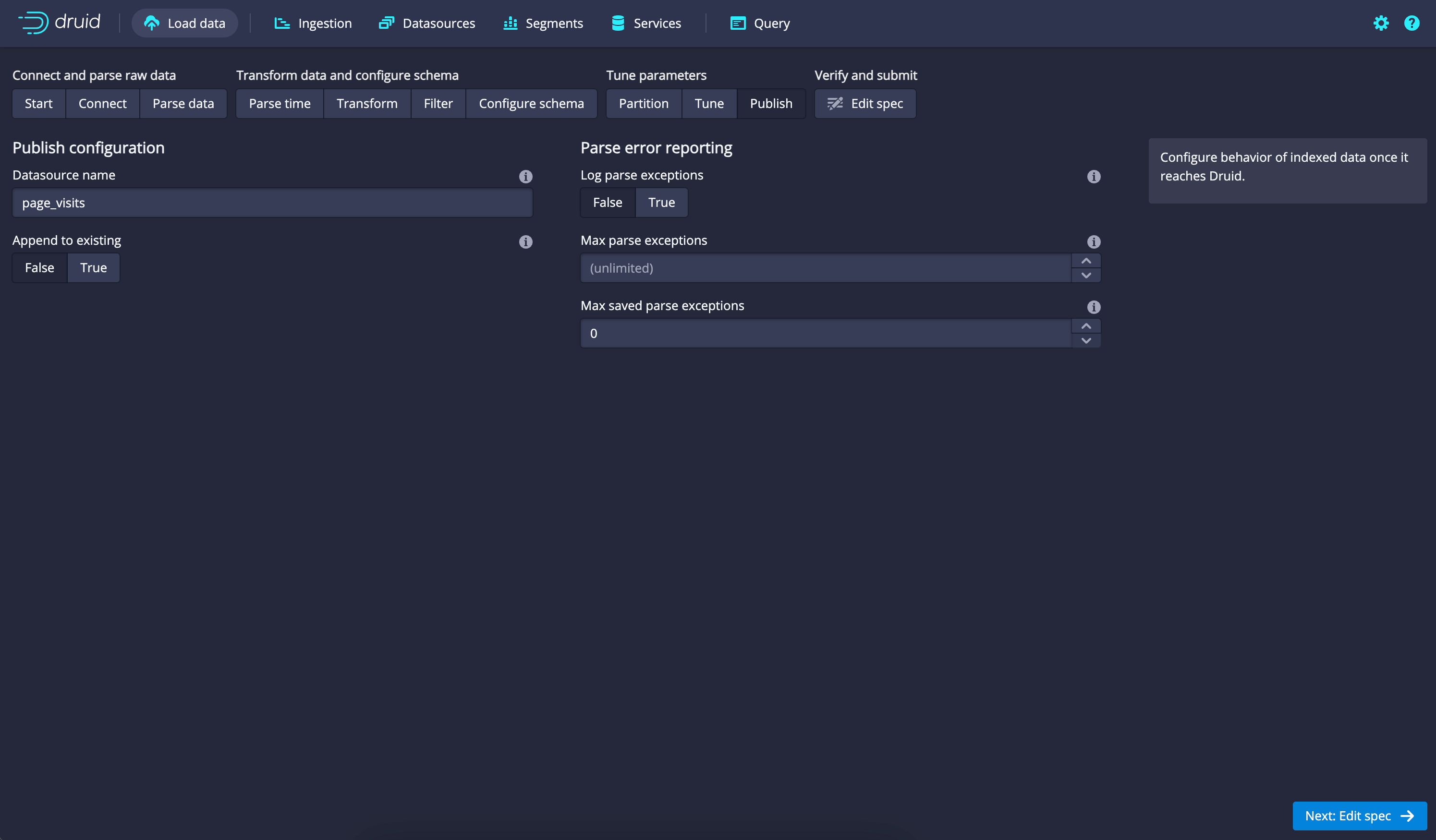
- Data Source name and Submit:
- After configuring all the necessary settings, click the "Submit" button to create the data source.
- After configuring all the necessary settings, click the "Submit" button to create the data source.
Data Querying with Apache Druid
Querying data in Apache Druid is where the true power of this time-series data analytics platform shines. Druid provides a variety of methods and tools to query your data, making it accessible for data analysts, engineers, and decision-makers. In this section, we will explore how to query data from Druid, the available query methods and libraries.
Methods to Query Druid:
- Druid SQL: Druid offers a SQL-like query language that allows you to write queries in a familiar SQL syntax. This language supports standard SQL operations like filtering, aggregations, grouping, and joins.
- Druid Query Language (DSL): For more advanced users, Druid provides a JSON-based query language known as the Druid Query Language (DSL). It offers fine-grained control over query execution and optimization.
- REST API: Druid exposes a RESTful API that allows you to send queries programmatically using HTTP requests. This method is ideal for integrating Druid into custom applications or scripts.
- Grafana: If you're using Grafana for monitoring and visualization, you can leverage its built-in support for Druid. Grafana provides a user-friendly interface to create and execute Druid queries.
Libraries to Query Druid:
- Druid SQL Libraries: Druid offers client libraries for various programming languages, including Python, Java, and JavaScript. These libraries enable you to send SQL queries to Druid from your preferred programming environment.
- Grafana Plugins: If you're using Grafana as your dashboarding tool, you can install Druid data source plugins to visualize and interact with Druid data directly within Grafana.
- Custom Integrations: For more specialized use cases, you can create custom integrations with Druid using its REST API. This allows you to query Druid from any programming language that supports HTTP requests.
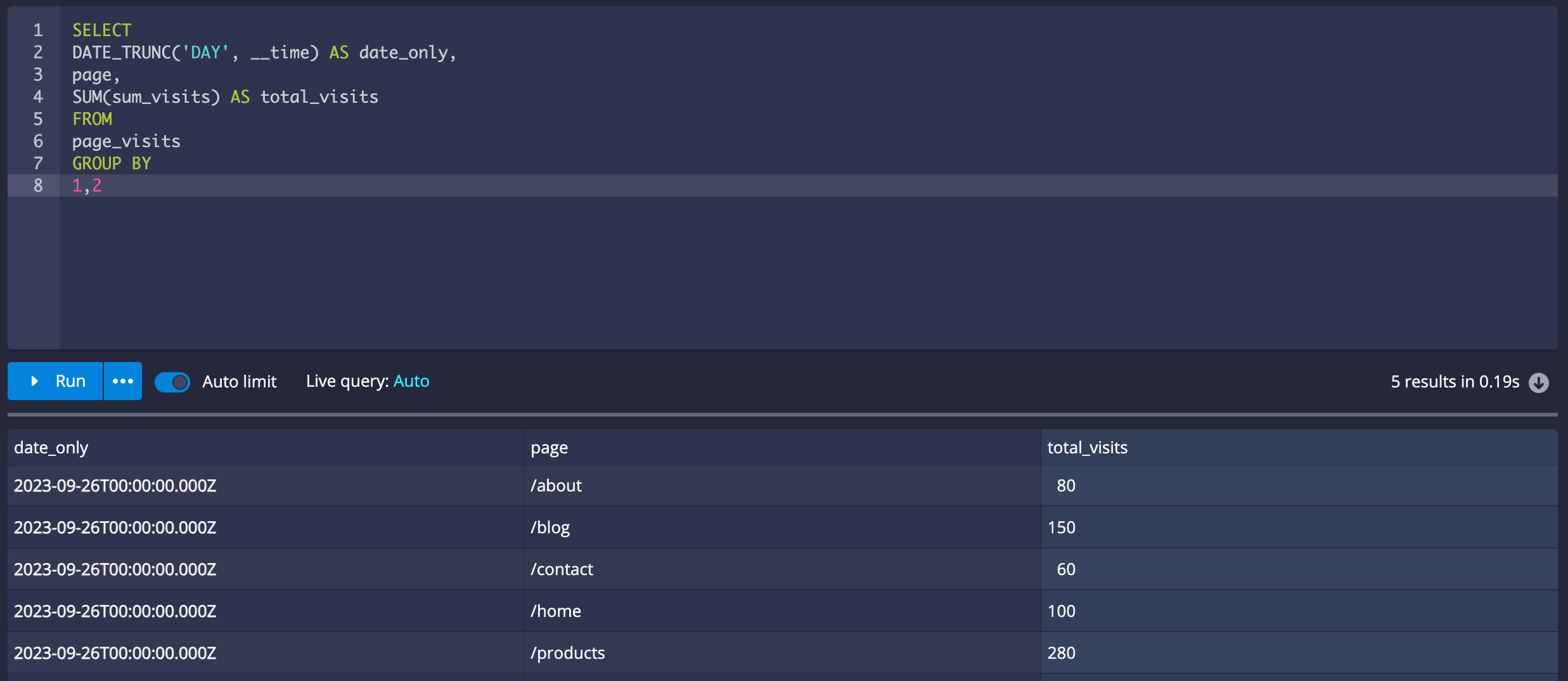
After successful ingestion, you can use Druid's SQL-like query language to extract insights from your time-series data.
SELECT
DATE_TRUNC('DAY', __time) AS date_only,
page,
SUM(sum_visits) AS total_visits
FROM
page_visits
GROUP BY
1,2This query calculates the total visits per page per day from the ingested data.
Summary
In summary, Apache Druid offers multiple methods for querying data, including SQL, DSL, REST API, and Grafana integration. You can leverage client libraries and custom integrations to query Druid from your preferred programming environment, and exporting query results to various formats, including CSV, is a straightforward process that enhances the usability and accessibility of your time-series data.
Reference - https://druid.apache.org/docs/latest/design/
