

Introduction
This article is the first in a series. There are links at the bottom of the article to the other parts.
SQL Server 2008 has come up with different compelling new features. One of them is T-SQL Enhancements which increase the productivity of developers by reducing overall development time. In this first article I will write about few of the T-SQL enhancements and in the second article I will write more about the new data types introduced in SQL Server 2008.
Intellisense Enhancements
We can keep our context, find the information we need, insert T-SQL language elements directly into our code, and even have IntelliSense complete our typing for us. This can speed up software development by reducing the amount of keyboard input required and minimize references to external documentation. Enhancements include expanded T-SQL language coverage and a new colorization system.
This feature works like the automatic syntax-checking in Visual Studio. As we type, it automatically fills out the syntax for Transact-SQL, and for database objects - even variables we’ve declared earlier (see the images below). The feature is configurable; we can turn it off or on.
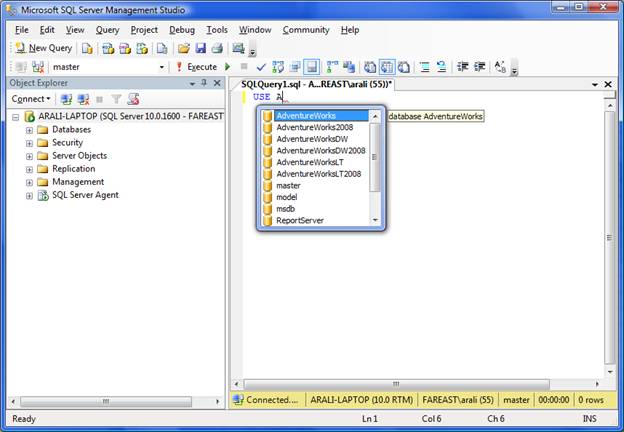
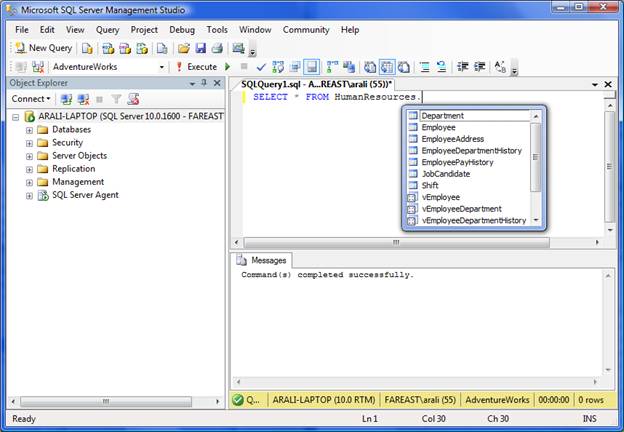
Syntax Enhancements
There are actually three syntax enhancements as follows:
· Initialization of variables at the same time of its declaration: Now we can initialize variables inline as part of the variable declaration statement instead of using separate DECLARE and SET statements. It works with most of the data types, including SQLCLR data types, but not TEXT, NTEXT, or IMAGE data types.
For Example:
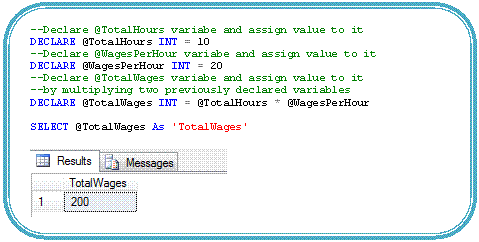 |
· Compound Operators: Compound operators are same as what we have in C++ and C#; they execute some operation and set an original value to the result of the operation. They help in writing cleaner and abbreviate code. (It also works in the SET clause of an UPDATE statement). These are list of supported compound operators in SQL Server 2008.
o += Add and assign
o -= Subtract and assign
o *= Multiply and assign
o /= Divide and assign
o %= Modulo and assign
o &= Bitwise AND and assign
o ^= Bitwise XOR and assign
o |= Bitwise OR and assign
For Example:
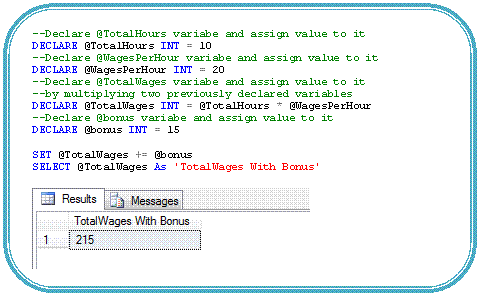
· Row Constructors (a.k.a. Table Value Constructors): Transact-SQL is enhanced to allow multiple value inserts within a single INSERT statement; it means multiple row predicates in the VALUES clause.
For Example:
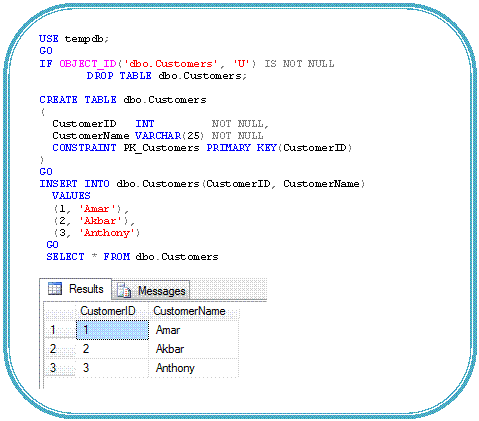 |
Object Dependencies Enhancements
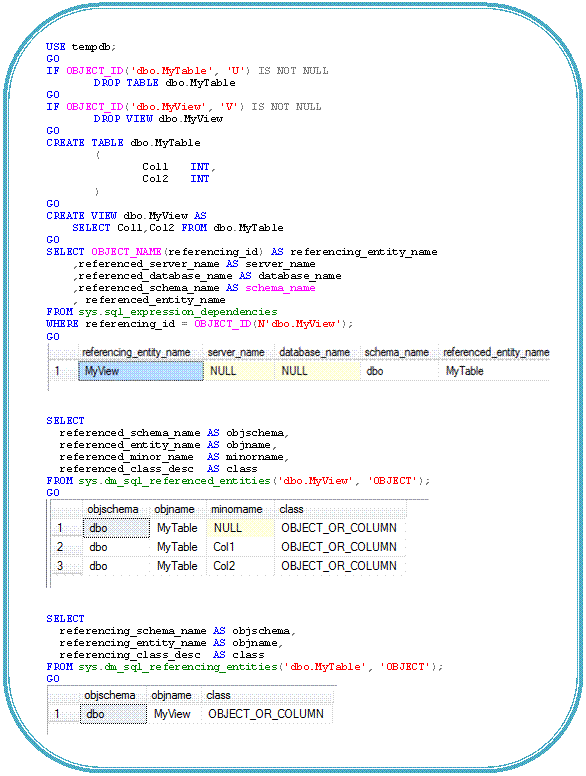
The object dependencies improvement provides reliable discovery of dependencies between objects through newly introduced catalog view and dynamic management functions. Dependency information is always up-to-date for both schema-bound (where the object A cannot be deleted because object B depends on it) and non-schema-bound (where Object A can be deleted or may not even have been created, however Object B still depends on it) objects. Dependencies are tracked for stored procedures, tables, views, functions, triggers, user-defined types, XML schema-collections, and more. SQL Server 2008 introduces three new objects that provide object dependency information:
· sys.sql_expression_dependenciescatalog view : It provides object dependencies by name, it holds one record for each dependency on a user-defined object in the current database.
· sys.dm_sql_referenced_entitiesDMF : It provides all entities that the input entity depends on, returns one row for each user defined object referenced by name in the definition of the specified referencing entity.
· sys.dm_sql_referencing_entitiesDMF: It provides all entities that depend on the input entity, it returns one record for each user defined object in the current database that references another user defined object by name.
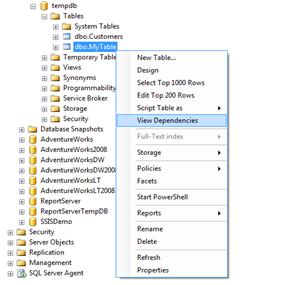
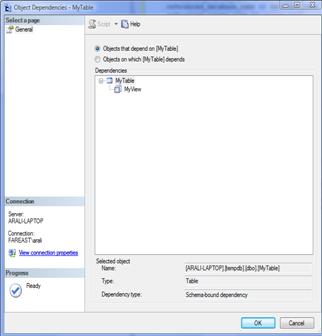
There are two ways we can see the object dependencies by using SSMS(Right click on the object and then click on View Dependencies) or by writing queries against above mentioned view and DMFs as given below:
 |  |
 |
Using the FORCESEEK Table Hint
The FORCESEEK table hint may be useful when the query plan uses a table or index scan operator on a table or view, but an index seek operator may be more efficient (for example, in case of high selectivity). The FORCESEEK table hint forces the query optimizer to use only an index seek operation as the access path to the data in the table or view referenced in the query. We can use this table hint to override the default plan chosen by the query optimizer to avoid performance issues caused by an inefficient query plan. For example, if a plan contains table or index scan operators, and the corresponding tables cause a high number of reads during the execution of the query, forcing an index seek operation may yield better query performance. This is especially true when inaccurate cardinality or cost estimations cause the optimizer to favor scan operations at plan compilation time.
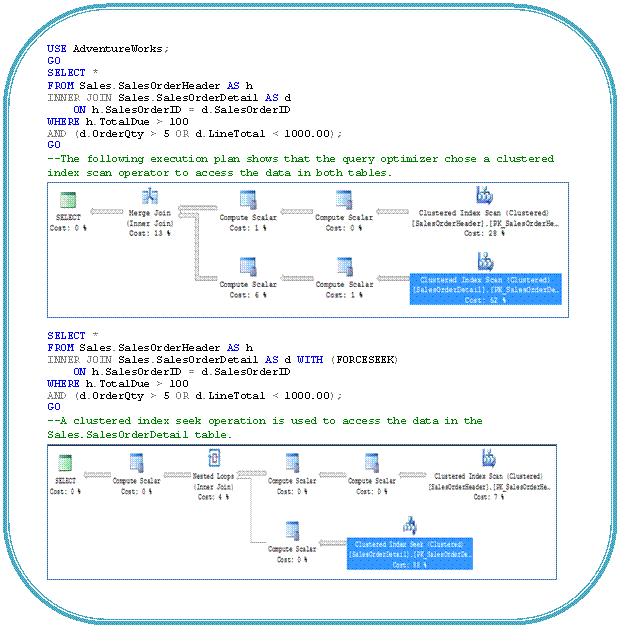
One of the scenarios where this hint can be useful is working around with Parameter Sniffing (It is a technique by which the SQL Server query optimizer to sniff the parameter value from the query during first invocation and generates an optimized execution plan based on that value). Let see this in action by running below queries against AdventureWorks database and analyzing different scenarios.
Scenario 1: The first query returns 450 rows and has low selectivity compared to the second query which return just 16 records, hence first query uses Index Scan rather than the Index Seek and Lookup of second query.
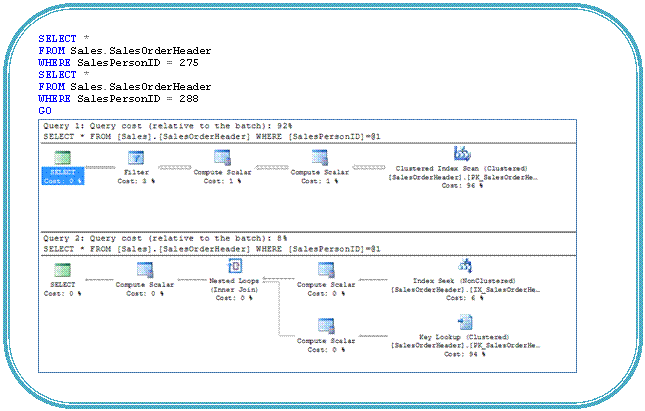
Scenario 2: In this scenario, I am running the same queries as above but this time I am using variables to pass values to queries instead of hard-coding the value. If we look at the execution plan generated, we see both the queries are using the same Index Scan even though the parameter values are different, and as we saw in scenario 1 the second query has high selectivity and should have used Index Seek and Lookup. This is happening because on execution of first query the SQL Query optimizer does not know the parameter value until runtime as I have used variables and makes a hard coded guess on selectivity and creates the execution plan on the basis of it and cache it, the second query uses the same cached execution plan. (Look at the query cost of both the queries and compare it with the scenario 1).
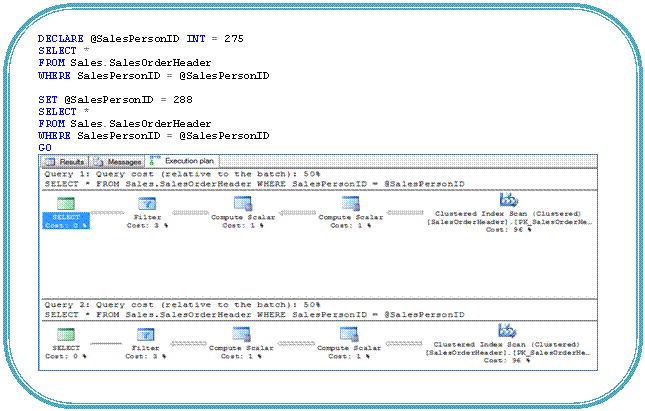
Scenario 3: So what to do if the queries use parameter and most of the time these variable values result in high selectivity, how can be force Query Optimizer to do Index Seek instead of Index Scan. We have two options here; either to use FORCESEEK hint or use RECOMPILE option as given.
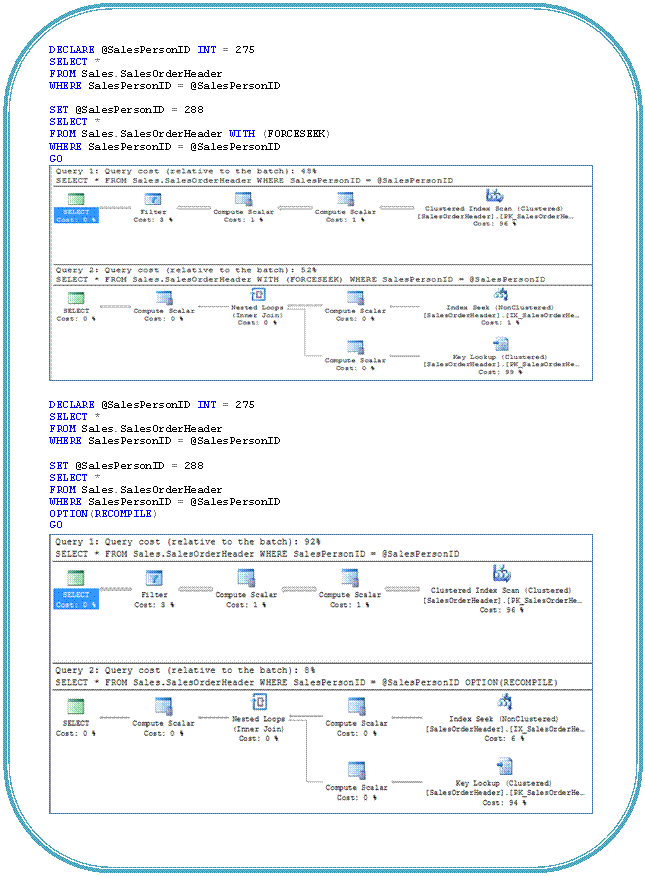
FORCESEEK applies to both clustered and non-clustered index seek operations. It can be specified for any table or view in the FROM clause of a SELECT statement and in the FROM <table_source> clause of an UPDATE or DELETE statement.
Note: Because the SQL Server query optimizer typically selects the best execution plan for a query, Microsoft recommends using hints only as a last resort by experienced developers and database administrators. In other words, use hints as a last resort for performance tuning (the optimizer does a good job most of the times).
GROUPING SETS
GROUPING SETS allow us to write one query that produces multiple groupings and returns a single result set. The result set is equivalent to a UNION ALL of differently grouped rows. By using GROUPING SETS, we can focus on the different levels of information (groupings) our business needs, rather than the mechanics of how to combine several query results. GROUPING SETS enables us to write reports with multiple groupings easily, with improved query performance. As the number of possible groupings increases, the simplicity and performance benefits provided by GROUPING SETS become even greater.
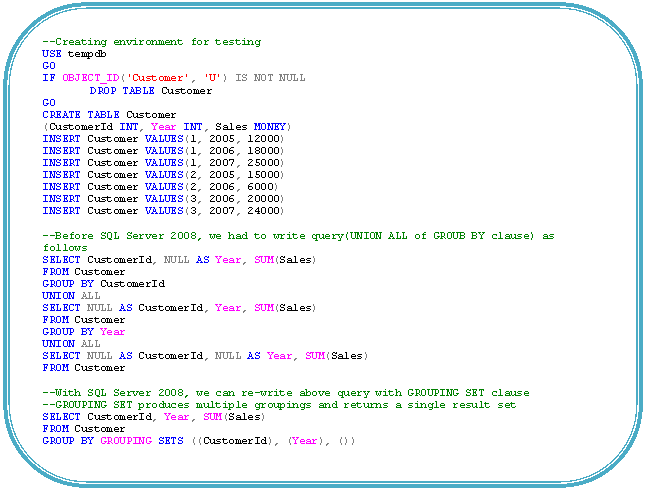
In other words, a GROUP BY clause that uses GROUPING SETS can generate a result set equivalent to that generated by a UNION ALL of multiple simple GROUP BY clauses because the GROUP BY clauses are invalid in combination.
Conclusion
In this first article I discussed about few of the T-SQL enhancements which increase the productivity of developers by reducing overall development time and allow them to write more efficient T-SQL code. In the second article on this series, I will write more about the new data types introduced in SQL Server 2008.
References
Using IntelliSense
http://msdn.microsoft.com/en-us/library/ms174184(SQL.100).aspx
INSERT Statements
http://msdn.microsoft.com/en-us/library/ms174335(SQL.100).aspx
How to: Upgrade to SQL Server 2008 (Setup)
http://msdn.microsoft.com/en-us/library/ms144267(SQL.100).aspx
How to: View SQL Dependencies (SQL Server Management Studio)
http://msdn.microsoft.com/en-us/library/bb630261(SQL.100).aspx
http://msdn.microsoft.com/en-us/library/bb677168(SQL.100).aspx
Using the FORCESEEK Table Hint
http://msdn.microsoft.com/en-us/library/bb510478(SQL.100).aspx
GROUPING SETS
http://msdn.microsoft.com/en-us/library/bb522495(SQL.100).aspx
This article is the fourth in a series. The other articles in the series are:
- SQL Server 2008 T-SQL Enhancements Part - I (Intellisense)
- SQL Server 2008 T-SQL Enhancements Part - II (UDTs and TVPs)
- SQL Server 2008 T-SQL Enhancements Part - III (HierarchyID and Large UDTs)
- SQL Server 2008 T-SQL Enhancements Part - IV (Filestream)
- SQL Server 2008 T-SQL Enhancements Part - V (Spatial)

