

SQL 2000 DBA Toolkit: Part Three - Phonetic Matching
"If everyone is thinking alike, then somebody isn't thinking." - Gen. George S. Patton
Introduction
In Part One of this series, we discussed the encryption tools in the DBA Toolkit. Part Two talked about regular expressions. In Part Three we will cover phonetic search tools in the Toolkit.
As always, feel free to use these tools as you see fit. If you find them useful, please drop me a line and let me know which ones you use, how you use them, and what you find most useful.
Enjoy.
Phonetic Matching
Phonetic matching is a key component to approximate name-based searching. In previous articles (Sound Matching and Phonetic Toolkit, Double Metaphone Phonetic Matching), I discussed some of the basics of phonetic matching and introduced various tools for SQL 2000 and 2005. In the DBA Toolkit I've redesigned a couple of these tools and added some new ones.
A database is only as good as what you can get out of it. Phonetic matching helps you get the most out of your database, by giving you the power to perform 'approximate' searches, as opposed to exact matches. Approximate searches allow users to find the data they want, as opposed to limiting them to exactly what they asked for. Specifically, phonetic matching attempts to break a word down into its component sounds. This helps retrieve not only the exact matches, but variations (i.e., Smith or Smythe is the classic example). Previously I introduced versions of the NYSIIS and Levenshtein Edit Distance algorithms in the Sound Matching and Phonetic Toolkit. This article discusses updates to these algorithms as well as some brand new tools for SQL 2000.
Installation
The installation instructions are in Part One of this series. As always, just copy the DLL's to your MSSQL\BINN directory and run the INSTALL.SQL script. Installation troubleshooting steps are covered in the README.RTF file included in the \DOCS directory.
Phonetic Matching Tools
In the Sound Matching and Phonetic Toolkit article, I discussed some of the theory and practice behind phonetic matching. I'll skim over the background information here, so we can get to the goodies.
Phonetic matching has a long history, going back to the invention of Soundex by Rusell and Odell in 1918. Soundex can properly be called the grand-daddy of all phonetic search algorithms. As mentioned in the Sound Matching and Phonetic Toolkit article, SQL Server has a SOUNDEX() function built in. Here's the bad news: Soundex is not very accurate. It tends to return a lot of false hits.
The good news? In 1970, Robert L. Taft introduced an improved Soundex system, referred to as the New York State Identification and Intelligence System (NYSIIS). NYSIIS improves on Soundex by handling letter combinations at the beginning of words (like 'MC' and 'PH'), handling certain letter combinations within the word and maintaining relative vowel positions within words, among other improvements. The Toolkit includes a re-written NYSIIS implementation:
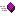 fn_phon_nysiis (@string) fn_phon_nysiis (@string) |
- @string is the string to phonetically encode. The result is 8 characters or less. Many implementations truncate the result to 6 characters, so you might wish to do the same with your results. The fn_phon_nysiis function is always case-insensitive and ignores non-alphabetic characters.
Specific details of the NYSIIS algorithm can be found at Wikipedia.
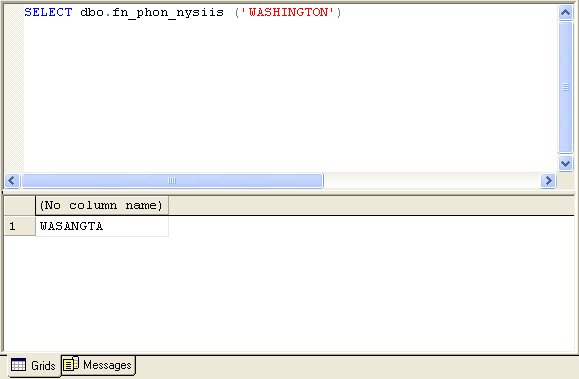
Fig. 1. Sample of fn_phon_nysiis
I've also added an implementation of Lawrence Philips' Double Metaphone algorithm, which was an improvement on his original Metaphone algorithm:
| fn_phon_dmeta (@string) |
- @string is the string to be encoded. The result is two phonetically encoded strings, up to six characters each.
Double Metaphone is a highly complex exception-based algorithm. It returns up to two possible encodings to account for irregularities, ambiguity and variations in the English language. It also handles some non-Latin alphabet characters. The fn_phon_dmeta function returns the encodings as a table with two columns:
- Num is the number of the match; 1 is the primary match, 2 is the secondary match.
- Code is the phonetic encoding. It is up to six characters in length.
Specific implementation details for the Double Metaphone algorithm are available at Wikipedia - Double Metaphone.
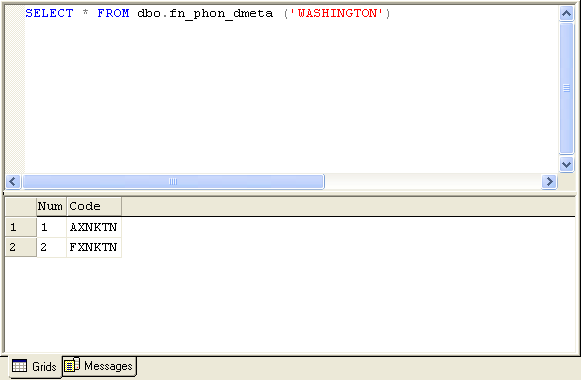
Fig. 2. Sample of fn_phon_dmeta
With this version I have added a couple of new algorithms. The first is an implementation of the Celko Improved Soundex algorithm, introduced by Joe Celko in his book SQL For Smarties: Advanced SQL Programming, now in its third edition. This Soundex variant handles various letter combinations better than the original Russell Soundex.
| fn_phon_celko (@string) |
- @string is the string to be encoded. The result is a phonetically encoded strings, up to eight characters. Many applications might use only the first four characters of the result, so you might want to truncate your results.
Fig. 3. Sample of fn_phon_celko
To round out the phonetic matching algorithms, I have also included an implementation of the Daitch-Mokotoff Soundex algorithm. While Russell Soundex and most of its variants focus primarily on Western European and names that were widespread in the U.S. as of the 19th century, Daitch-Mokotoff focuses on properly encoding Eastern European names. This algorithm is the sound-indexing standard for the Ellis Island Database project and the U.S. Holocaust Memorial Museum database:
| xp_phon_dm @string |
- @string is the string to be encoded. The result is up to 32 separate phonetic encodings. Since Daitch-Mokotoff returns all-numeric values between 100000 and 999999, the encodings are returned as INTEGERs.
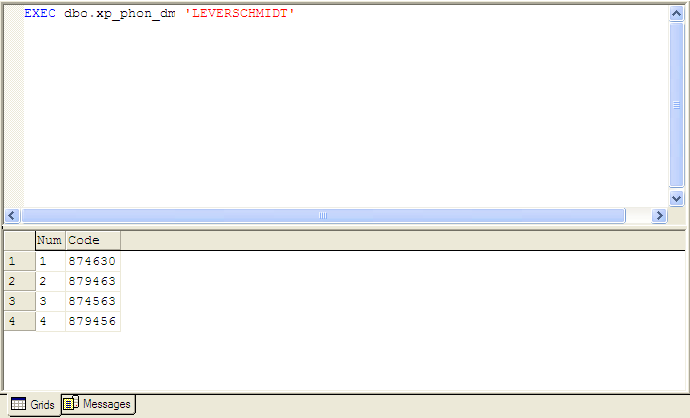
Fig. 4. Sample of xp_phon_dm
Edit Distance
With the original Sound Matching and Phonetic Toolkit article I introduced a SQL Server version of the Levenshtein Edit Distance algorithm. This algorithm compares two strings to determine how many changes (deletions, insertions, replacements) need to be made to the first string to turn it into the second string. This is known as the Edit Distance for that string. I have revisited Levenshtein Edit Distance in this toolkit as well:
| fn_dist_lev (@string1, @string2) |
- @string1 and @string2 are the two strings to compare.
The fn_dist_lev function compares two strings and returns a similarity rating, based on the edit distance. The edit distance is a calculation of how many steps it would take to transform one string to another. This function calculates that value, divides it by the length of the longer string and subtracts the result from 1.0. This results in a value between 0.0 and 1.0, with 1.0 being a best match.
Levenshtein Edit Distance calculation is an order O(mn) calculation. Because of the amount of calculation involved, normal practice is to narrow down the result set using some other method before refining the results with Edit Distance calculations.
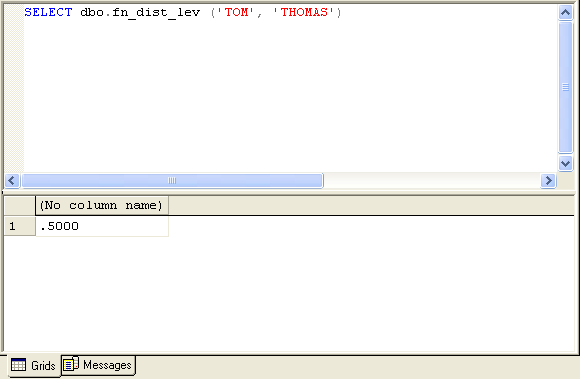
Fig. 5. Sample of fn_dist_lev
| fn_dist_jaro (@string1, @string2, @options) |
- @string1 and @string2 are the strings to compare.
- @options are the available user options. For the fn_dist_jaro function, the only option currently supported are 'I+' and 'T+'. 'I+' turns case-insensitivity on. By default, Jaro-Winkler string comparisons are case-sensitive. 'T+' compensates for some common typographical errors in longer strings (i.e., transposition of the letter 'O' with the number '0'). This option does not affect short strings, as longer strings tend to have more chance of containing typos.
This extended procedure uses the Jaro-Winkler string distance algorithm to compare two strings. It is a more complex algorithm than the Levenshtein Edit Distance, but also more efficient. Jaro-Winkler considers several factors, including the largest common prefix, and approximate positioning of characters that both strings have "in common".
Like fn_dist_lev, this function returns a number between 0.0 and 1.0, with 1.0 representing a perfect match.
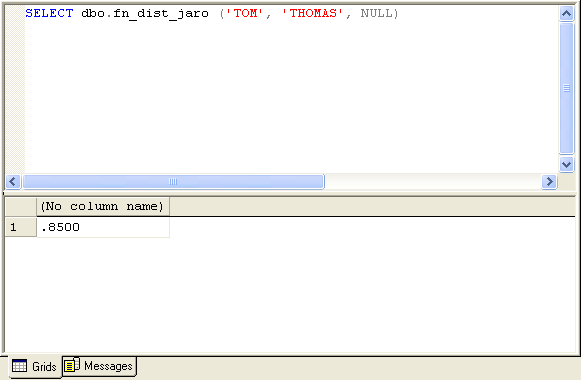
Fig. 6. Sample of fn_dist_jaro
DBA Toolkit (Phonetic Matching) Quick Reference
| User-Defined Functions | Description |
| fn_phon_nysiis (@string) | Phonetically encodes @string using the NYSIIS algorithm, and returns the result. |
| fn_phon_dmeta (@string) | Phonetically encodes @string using the Double Metaphone algorithm, and returns two results. |
| fn_phon_celko (@string) | Phonetically encodes @string using the Celko Improved Soundex algorithm, and returns the result. |
| fn_dist_lev (@string1, @string2) | Calculates the Levenshtein Edit Distance between two strings and returns the result as a decimal value between 0.0 (no match) and 1.0 (exact match). |
| fn_dist_jaro (@string1, @string2, @options) | Calculates the Jaro-Winkler Distance between two strings and returns the result as a decimal value between 0.0 (no match) and 1.0 (exact match). |
| Extended Procedures | Description |
| xp_phon_nysiis @string, @ret OUTPUT | Returns the NYSIIS encoding for a string. |
| xp_phon_dmeta @string, @ret1 OUTPUT, @ret2 OUTPUT | Returns two Double Metaphone encodings for a string. |
| xp_phon_celko @string, @ret OUTPUT | Returns the Celko Improved Soundex for a string. |
| xp_phon_dm @string1 | Returns the Daitch-Mokotoff Soundex encodings for a string, in the form of a table of INTEGERS. Can return as many as 32 possible encodings for one string. |
| xp_dist_lev @string1, @string2, @ret OUTPUT | Returns the Levenshtein Edit Distance between two strings as an integer. Divide result by 10,000 to get value between 0.0 and 1.0. |
| xp_dist_jaro @string1, @string2, @ret OUTPUT, @options | Returns the Jaro-Winkler Distance between two strings as an integer. Divide result by 10,000 to get value between 0.0 and 1.0. |
Summary
This is the end of Part Three of this DBA Toolkit series. In this article we talked about phonetic matching tools included in the toolkit. In Part Four we will discuss other tools in the toolkit that didn't fit into these other categories.