

In the previous parts of this series, I showed how to Script all objects from SSMS and also getting specific objects scripted and stored in a VCS (version control system). Those are manual tasks and not a productive use of a developer's time. They may work well for limited capture of code, but for ongoing development, especially in a team, there are better ways to captuer you object code and store the evolutions in a VCS.
I mentioned that I would show a technique using PowerShell in the next article, and this is that article. I will show you a method for script code in a programmatic way and then commit that to git. I will also talk about a few ways in which you might enhance this solution to better meet your requirements. There are two main parts:the scripting in PoSh and then the usage in editing objects.
Scripting Objects in PowerShell
When I started working with SQL Server, there were SQL Server Management Objects (SMO) contained in a .DLL that you could reference and use to work with SQL Server. The problem early on is that to do this, you needed to write C++ code, which wasn't all that attractive to many DBAs, myself included. I could cobble together VBScript or muck with T-SQL in much less time.
With PowerShell, we got a better, scriptable interface to these same SMO libraries, which while still cumbersome, is much more amenable to DBAs. There are quite a few scripts that people have written to use the SMO libraries from PoSh and most of them work the same way. You load the DLL and then you manipulate the various objects to connect to SQL Server, iterate through objects, and generate a script. In this article, I'll borrow some code from Aaron Nelson (@sqlvariant) that is on The Scripting Guy blog.
I've modified Aaron's code slightly, and I won't explain all of it, but I will keep the general structure of the function. Here's basic flow of the code, which is attached. I have snippets of the code inline for explanations.
Parameters
To keep this as a general function, I kept Aaron's two parameters for the server instance and database name. I added a path parameter, since I want to be able to specify which git repository I want to use. Here's my function definition:
function global:Script-DBObjectsIntoFolders([string]$server, [string]$dbname, [string] $path) {
You could add other parameters if you need them. You could add in a switch for just certain objects, or switches for any type of object. You certainly could also include scripting options if you find you change them, but I wouldn't recommend that. You should have consistent options, so I'd leave them coded in the function.
Loading the Objects
The next part of the code is Aaron's, and this loads the objects into a variable. We load the SMO library, use it to create a handle to your instance, and then load tables, views, procedures, and functions into a single object list. This is the list to iterate through in order to script objects. If you wanted to limit the scripting to certain objects, you'd change this section, or use parameters to execute or skip particular lines.
[System.Reflection.Assembly]::LoadWithPartialName("Microsoft.SqlServer.SMO") | out-null
$SMOserver = New-Object ('Microsoft.SqlServer.Management.Smo.Server') -argumentlist $server
$db = $SMOserver.databases[$dbname]
$Objects = $db.Tables
$Objects += $db.Views
$Objects += $db.StoredProcedures
$Objects += $db.UserDefinedFunctions
Scripting
The rest of the code is really simple. An outer foreach loop is used to iterate through the $objects variable and check each object inside your database. There are a number of lines that set options, and you must build the directories for each object type if they don't exist. This could be optimized, but it's fine for our purposes. There are a few lines to point out in the code and a few changes.
One is that we need to load the scripter object with this line:
$scriptr = new-object ('Microsoft.SqlServer.Management.Smo.Scripter') ($SMOserver)
There are two options that need to be changed. First, we don't want headers, because each time we script, we don't want a new date/time stamp. We really want to just get the code. The second option is the AppendToFile option. False here. We want a new file each time.
$scriptr.Options.AppendToFile = $False $scriptr.Options.IncludeHeaders = $False
The other part is to call the Script() method to produce the script and save it in a file. An option is set and then the method is called with these two lines.
$scriptr.Options.FileName = "$SavePath\$TypeFolder\$ScriptFile.SQL" #This is where each object actually gets scripted one at a time. $scriptr.Script($ScriptThis)
That's it for the code, now let's see how this works.
Getting Object Code
Now that we have a function, how do we call it? Here's what works for me. First, I have an empty git repository. I removed the folders from the previous articles and committed those changes. That gave me this:
Next I I ran this code from a PowerShell command line. The first line loads the function into memory and the second executes it:
PS E:\Documents\powershell> .\scriptdatabase.ps1 PS E:\Documents\powershell> Script-DBObjectsIntoFolders "Plato\SQL2016" "WideWorldImporters" "e:\documents\Github"
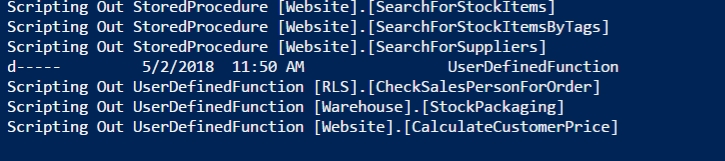
The results from this scroll through the screen, but here are the ending items. As you can see, I get a report of objects scripted.
What's in my git repo? Let's see.
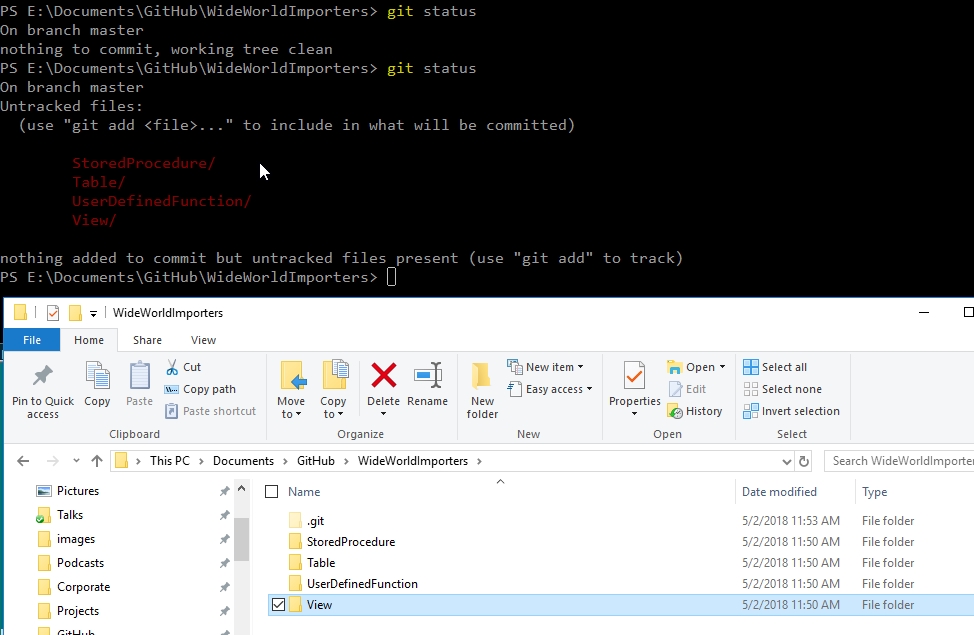
Above you can see that I have untracked files from the scripting. In the lower part, you can see that I have folders for the types of objects I scripted. If I open one of these, such as the UserDefinedFunction folder, I see this:

That's a better view of objects than I had in the other articles. Since this is scripted, I could easily change the format of the filenames if I choose. Looking at the code for the JustTwo.sql function, I see this:
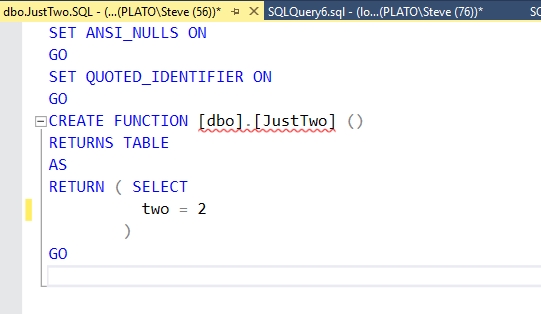
I'll also show the code for the VehicleTemperatures table. This is the file opened in SSMS.
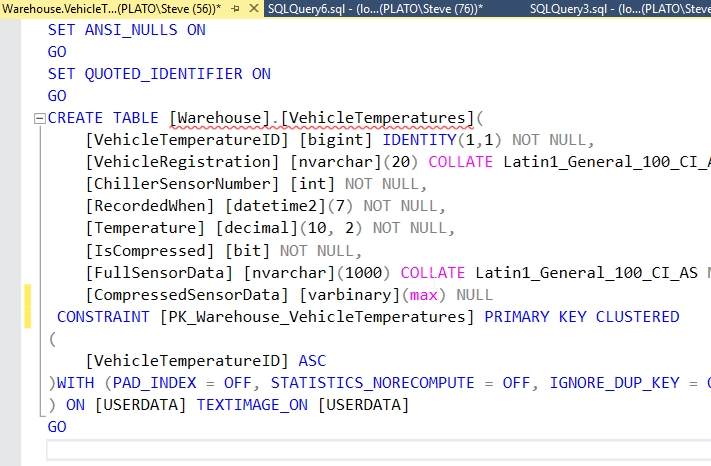
Let's commit all the objects. I'll do this from the CLI. While this isn't in SSMS, it's pretty close. Plenty of developers use separate clients to commit to a VCS, and while I like SQL Source Control integration and VS integration, using SourceTree, GitKrakken or a CLI doesn't faze me.
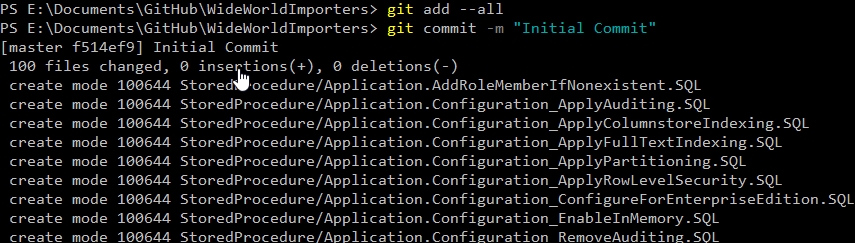
If I were to check the status, the working tree would be clean.
Changing Code
Let's change some code, after all, the point of a VCS is to track changes. I'll add a column to the table and also change my procedure slightly. Here are the changes:
ALTER TABLE [Warehouse].[VehicleTemperatures] ADD SensorLocation VARCHAR(200)
GO
ALTER FUNCTION [dbo].[JustTwo] ()
RETURNS TABLE
AS
RETURN ( SELECT
two = 'Two'
)
Now, let's run our scripting tool. Once the new scripting is complete, I'll see this in git.
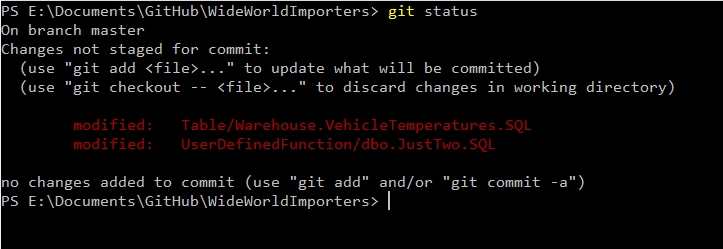
Only the two files changed were listed here.
The Development Flow
Essentially I can make any changes that I want in code, without keeping track of the changes. However, when I think I am done with my work, I'll want to commit the changes. This means my development flow is:
- Change code in SSMS
- Run scripter function
- Stage file(s) - As many as appropriate for the commit
- Commit the files
The third step is a git function and may not be needed in other systems, like SVN.
I can repeat this flow as needed. If I want to undo changes, I can undo them in code and re-script the database, saving the changes in my VCS. I could also restore a previous version of the file, but I'd want to be sure I use the proper SQL code to undo the change. For example, the state of a table a a point in time won't let me remoe a column that I added my mistake. I'd need an ALTER TABLE statement to remove the column, not the CREATE TABLE statement, which is what I'm scripting.
Summary and Enhancements
This article shows a basic way that I can capture the code from my objects and commit the code to a VCS. This solution uses PoSh to script the objects and then manual commits. The way this script is structured, only changed objects should be detected by your VCS system, but new files are generated, so you will want to be sure your VCS behaves the same way git does.
There are a number of ways that this process could be enhanced. First, the PoSh script could be set to run from a hotkey, a batch file, or even an Agent job. Each of those has advantages and disadvantages. The former two items allow a developer to easily run the scripting agent without knowing or opening a PoSh CLI. The latter would allow automatic commits to check if there are any changes developers have forgotten. I have actually use a scheduled task to script code and save it each night into a VCS, though with a generic commit message. The same thing could be done here to ensure no code is lost.
The second way this process could be enhanced would be by customizing the script that might separate the objects by schema first, then type, reverse that, or even change the naming to better conform with your own structures. If you have separate schemas for different purposes, you could even use different repositories to store portions of your database.
I do believe that capturing code is extremely important to producing better software, coordinating with others, and moving faster in today's DevOps style development. So far this series has focused on manual efforts that work outside of SSMS. In the next article, we will look at SQL Source Control and how this fits within your development flow.


