

High availability or Always On is achieved in SQL Server using Cluster. Clustering is a logical collection of 2 or more physical servers (nodes) that individually host SQL instances and access the common shared storage. The applications will connect to a cluster instead of connecting to the individual SQL instances. The cluster will automatically failover if the primary is unavailable due to any issues. The users or applications will not notice any data loss or downtime.
There are a few objects, like logins, permissions, jobs etc., that are to be configured on each individual node in the cluster. In the cluster, while the primary node is in use, the secondary nodes are not accessible (read access can be enabled but no write access is granted). If you try to access a database, you will get an error like the one below.
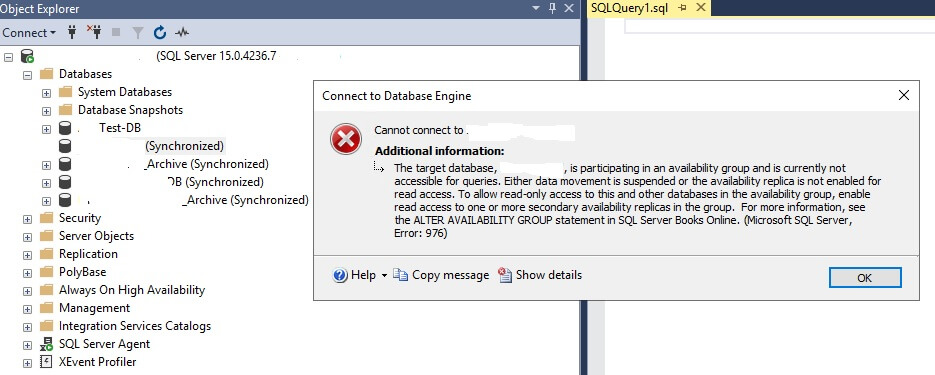 Error
Error
Problem: The jobs those are scheduled on the secondary node fail and send failure notification or support tickets (if configured). These jobs cannot be turned off on the secondary node because if the cluster falls back to secondary node, the jobs will not be available.
Solution: There are 2 ways to work around this issue.
- External scheduler: We can use external schedulers like BMC Control-M, UC4 Automic, or basic schedulers included in the OS. In the schedulers, we can execute a script against the cluster directly. This approach would be expensive as the external schedulers need additional licensing and maintenance.
- Explicit check on the node: The jobs should have the 2 additional steps added at first and last. The first step will check if the node on which this is being executed is the primary or not. If primary, continue to the next steps. If not raise an error (non-fatal, 11) and go to last step. In the last step, handle the exception and quit the job reporting success. This will ensure that there are no false alarms triggered in notifications.
The following are the details of implementation
First , create a job step and make this step as the 1st step of the job and the following script in the command window.
In the step, use this code:
IF
(
SELECT ars.role_desc
FROM sys.dm_hadr_availability_replica_states ars
INNER JOIN sys.availability_groups ag
ON ars.group_id = ag.group_id
WHERE ag.NAME = 'YOUR_CLUSTER_NAME'
AND ars.is_local = 1) != 'PRIMARY'
BEGIN
RAISERROR (N'This is Secondary DB', 11,1);
END
ELSE
BEGIN
PRINT 1
ENDAdd additional job steps required to perform your logic
At the end, add a new step and move it to the last step of the job. Configure it as shown here: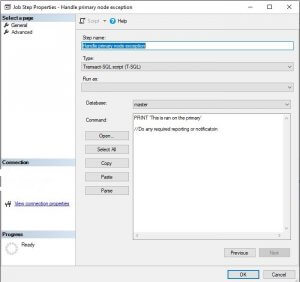
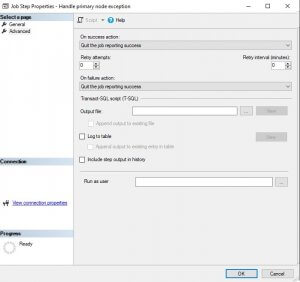
Go to step 1 and select the advanced page. Select "Go to Step : Handle primary node exception" from the On failure action dropdown. Select "Go to next step" from On success action dropdown.

Go to the last step and select the advanced page. Select "Quit the job reporting success" on both On success action and On failure action dropdowns.
Follow these same steps on both the primary and secondary nodes. This will make sure that the actual job scripts only run on primary server and no false alarms are reported.

