

Ever notice that there are so many bad things that can happen to a DBA? One
of the many errors that will make the blood of DBA run cold is 'insufficient
space'. In this article I'd like to talk about some basic strategies both for
avoiding it as well as dealing with it if...or when, it happens.
At least in SQL 2000 the default is for both data and log files to grow by 10
percent when needed with no limit to the max size. Let's start by looking at how
you configure these in Enterprise Manager:
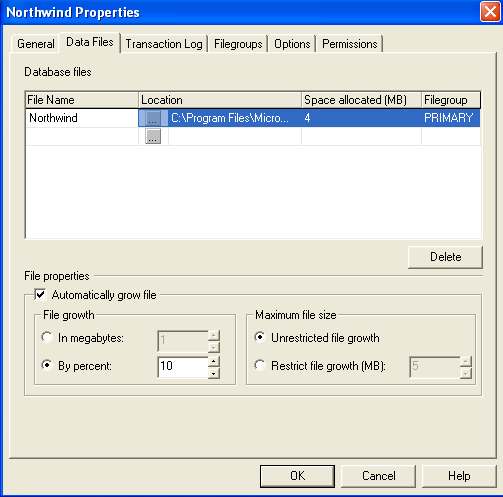
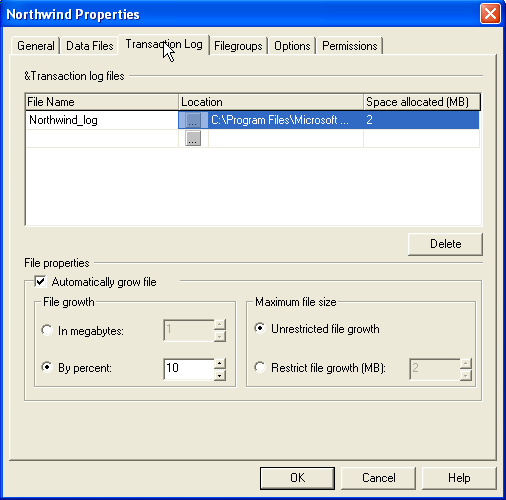
Whether you change these at all depends on both your environment and your
preferences. Leaving auto grow selected decreases the tedium of having to grow
the files manually - and to some extent of having to keep track which files are
about to need to be expanded. There are three down sides to leaving it set to
the default in my opinion. One is that it's possible to have it grow until it
consumes all available disk space. The second is that while 10 percent is
reasonable for smaller files, you don't always want to grow a 10g database by 1g
at a time. And finally, you do suffer a performance degradation when the file
grows - how much depends on how much you grow and how good your disks are. Even
with all those seemingly negative comments, for the most part I leave the
defaults in place, overriding the growth to a 100m or so at a time if the file
is over 1g.
It's important to note that whether you use the auto grow or not, set a max
file size or not, it's still possible to run out of space as far as SQL is
concerned. Running out of data or log space is equally bad.
There are a lot of gotcha's that are possible with regards to space, here are
some that are pretty common:
- You use the standard maintenance plan to rebuild indexes. Depending on
the options you select this can enlarge both db and log quite a bit.
Frequent log backups during the rebuild period are a good idea.
- Every time the database size grows by a meg, you need another meg free
to back it up. Say you've got a 100g drive with a 40g database and for
purposes of discussion the backup is also 40g, leaving you a cool 20g free.
Add 10% to the db driving the size up to 44g, you now only have 12g free
after backup - and that's not counting your log backups.
- Log backups fail. Could be because you're out of space to run the
backup, or the job hangs up, or other bad thing, the result is your log file
will grow and grow until you run a successful log backup.
- Old backups don't get deleted. This can happen if your maintenance plan
fails.
- Replication log reader fails, forcing growth of the log until the
transactions are read or the subscription expires.
- Replication distribution agent (or queue agent) fails, causing pending
data to accrue forcing growth of either the distribution db or the publisher
db.
- Someone loads a large amount of data. Remember it's not just the data,
it's the increase in space used by indexes as well.
Nothing like having a good set of rules to live by, so here are
mine when it comes to preventing out of space errors.
Rule #1 - monitor the free space available! Monitoring
doesn't have to be sophisticated, though most server monitoring utilities
include this as a core component. Dirt cheap is to set a reminder to check disk
space once a day manually. You can also set an alert to warn you when a file
grows, realizing that just because the file grew doesn't mean you're in the
danger zone automatically.
Rule #2 - assume you will run out of space. I keep
several 1g files as placeholders on each drive that might run out of space. If I
absolutely need space I can delete them while I try to shrink a log or take
other action to try to reclaim some space. Here are some additional
alternatives:
Add a new filegroup to the database or log file. It's common
to have a lot of extra space on C: these days, usually only the OS installed
there. It won't be fast, but it will give you a chance to work the problem
without stopping work.
Look for any file you may be able to move somewhere else.
You might be able to detach a non critical db and move to another drive, or
you might have backups from today that while important, are less important
than getting users back to work.
This may never happen to you. Or it might happen tomorrow. Be
proactive in trying to prevent it, and be schooled in the options just in case
it does.
Are there other strategies you use? Horror stories about running
out of space? If there is enough interest I'll do a follow up to talk about
other interesting options that readers may use.
