

Microsoft is introducing Regular Expression(regex) functions in its upcoming SQL Server 2025 to enable pattern-based searching and manipulation. This allows searching and manipulating data directly using T-SQL language and eliminates the need of programming languages such as Python.
In this article, we will learn about these new Regex T-SQL functions. We will see their usage for searching and manipulating data.
Note: SQL Server 2025 is currently in preview mode and some features may not give satisfactory results. The RTM (Release to Manufacturing) version is expected around October 2025, which will bring more stability and refinements.
Regex Functions
Let's understand the different functions one by one with practical examples.
Note: We will use an employees table with dummy data for examples to explain the different functions. Create the table and insert data using below script-
USE [SQL-2025] GO CREATE TABLE [dbo].[Employees]( [EmpID] [int] IDENTITY(1,1) NOT NULL, [FullName] [nvarchar](100) NULL, [Email] [nvarchar](100) NULL, [Phone] [nvarchar](20) NULL, [Skills] [nvarchar](100) NULL, ) GO SET IDENTITY_INSERT [dbo].[Employees] ON GO INSERT [dbo].[Employees] ([EmpID], [FullName], [Email], [Phone], [Skills]) VALUES (1, N'Amit Kumar', N'amit.kumar@gmail.com', N'987654e321', N'Database Developement, Web Design') GO INSERT [dbo].[Employees] ([EmpID], [FullName], [Email], [Phone], [Skills]) VALUES (2, N'Priya Sharma', N'priya_sharma@yahoo.org', N'9123456789', N'Application Development, Web Development') GO INSERT [dbo].[Employees] ([EmpID], [FullName], [Email], [Phone], [Skills]) VALUES (3, N'JohnDoe', N'john.doe@.com', N'9988776655', N'Application Testing') GO INSERT [dbo].[Employees] ([EmpID], [FullName], [Email], [Phone], [Skills]) VALUES (4, N'DeepakSingh', N'deepaksingh@@example.com', N'8001234567', N'System Administration, Networking') GO INSERT [dbo].[Employees] ([EmpID], [FullName], [Email], [Phone], [Skills]) VALUES (5, N'Sara Ali', N'sara123@gmail.com', N'9126780', N'Database Administration') GO INSERT [dbo].[Employees] ([EmpID], [FullName], [Email], [Phone], [Skills]) VALUES (6, N'Ram kumarSingh', N'ramkumar1223@outlook.com', N'9123456780', N'Graphic Desigining') GO SET IDENTITY_INSERT [dbo].[Employees] OFF GO
REGEXP_LIKE()
REGEXP_LIKE() validates if the regular expression pattern matches in a string. It takes a string expression and regex pattern as input arguments and returns a boolean value( 1 for a match and 0 for no match). The syntax is:
REGEXP_LIKE(expression, pattern [, match_type])
where the arguments are:
- expression - source string to evaluate
- pattern - regex pattern to match against
- match_type(optional) - for case sensitivity.(i - insensitive, c - sensitive)
You can use this function for validation purposes such emails or phone number validation.
The example below validates email id of the employees using a regex pattern - ^[A-Za-z0-9._+]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}$. The matching email addresses are only valid, while the non-matching ones are invalid. Here is a breakdown of this regex:
- ^ ensures start of the string
- [A-Za-z0-9._+]+ matches multiple lowercase and uppercase alphabets, digits, dot, underscore, plus signs before '@' in username
- @ ensure it is present after username and before domain name.
- [A-Za-z0-9.-]+matches multiple lowercase and uppercase alphabets, digits, dot, hyphen after @ in domain name part.(e.g. google, five9,etc.)
- \. matches literal (.) before the top-level domain(TLD).
- [A-Za-z]{2,} matches at least two alphabets in the TLD(e.g. .com, .in, etc.)
- $ ensures end of the string
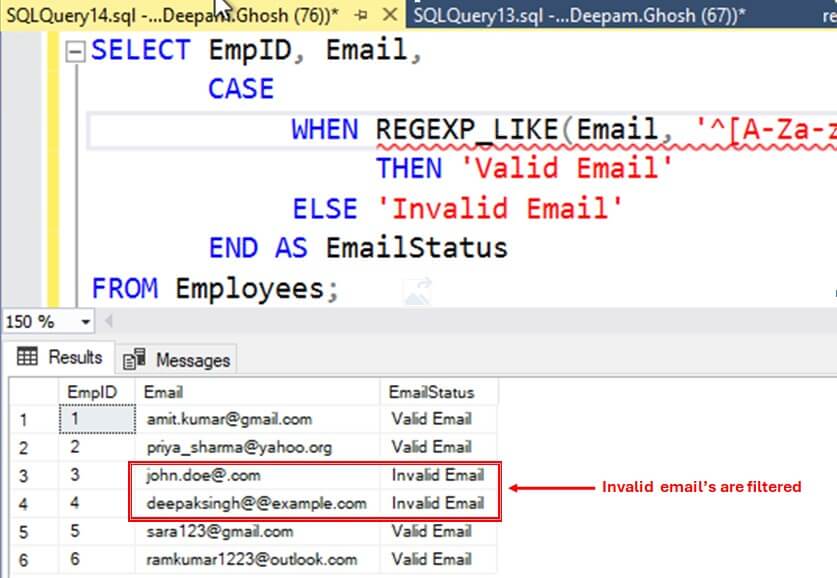
SELECT EmpID, Email,
CASE
WHEN REGEXP_LIKE(Email, '^[A-Za-z0-9._+]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}$')
THEN 'Valid Email'
ELSE 'Invalid Email'
END AS EmailStatus
FROM Employees;
Here are the results, which contain both valid and invalid emails.
Next example, validates phone numbers and filters out invalid numbers using another regex ^[0-9]{10}$. Here is a breakdown of this regex-
- ^ ensures start of the string
- [0-9] matches only digits from 0 to 9
- {10} matches only 10 digits
- $ ensures end of the string
Hence, the phone numbers containing alphabets, special character or less than ten digits are considered as invalid.
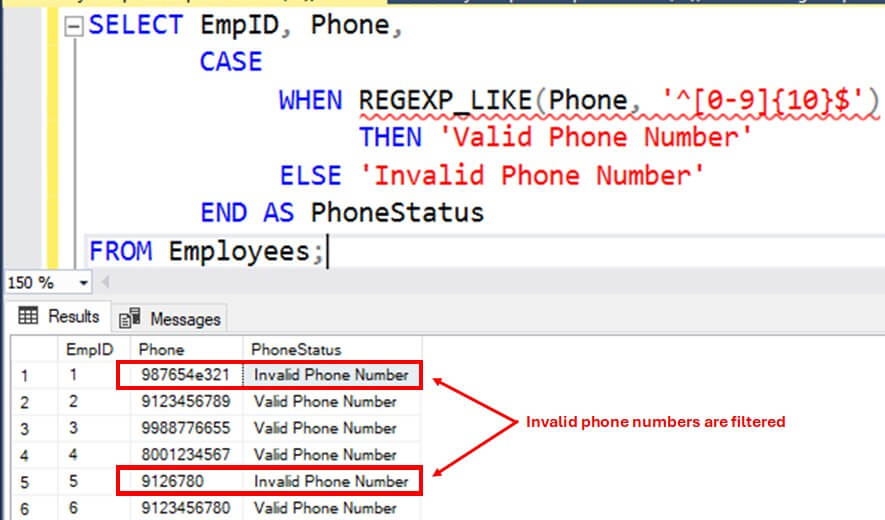
SELECT EmpID, Phone,
CASE
WHEN REGEXP_LIKE(Phone, '^[0-9]{10}$')
THEN 'Valid Phone Number'
ELSE 'Invalid Phone Number'
END AS PhoneStatus
FROM Employees;
You can see some invalid phone numbers in the results.
REGEXP_REPLACE()
REGEXP_REPLACE() replaces the part of the the string that matches the regex pattern. It takes a string expression, a regex pattern and a replacement string as input arguments. If the regex pattern matches the string expression, it replaces the matching part with replacement string. In case of no match, it returns the original string. The syntax is:
REGEXP_REPLACE(cast(cast(expression as nvarchar(max)) as nvarchar(max)),cast(cast( pattern as nvarchar(max)) as nvarchar(max)),cast(cast( replacement [, start [, occurrence]] as nvarchar(max as nvarchar(max)))))
where the arguments are:
- expression - source string to evaluate
- pattern - regex pattern to search
- replacement - string to replace the matches
- start(optional, default=1) - position to start search
- occurrence(optional, default=0=all) - match occurrence to replace
You can use this function for masking sensitive data such as phone numbers, credit card numbers etc. and replacing parts of a string.
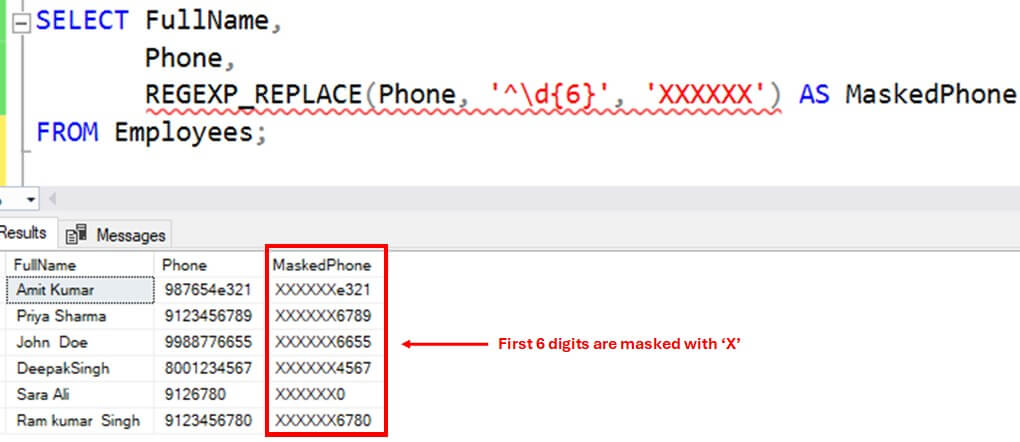
The example below masks first 6 digits of phone numbers using a regex pattern ^\d{6}. It matches exactly 6 digits from the start of the string and replaces it with 'XXXXXX'.
SELECT FullName,
Phone,
REGEXP_REPLACE(cast(cast(Phone as nvarchar(max)) as nvarchar(max)),cast(cast( '^\d{6}' as nvarchar(max)) as nvarchar(max)),cast(cast('XXXXXX' as nvarchar(max as nvarchar(max))))) AS MaskedPhone
FROM Employees;You can see all the digits masked below.
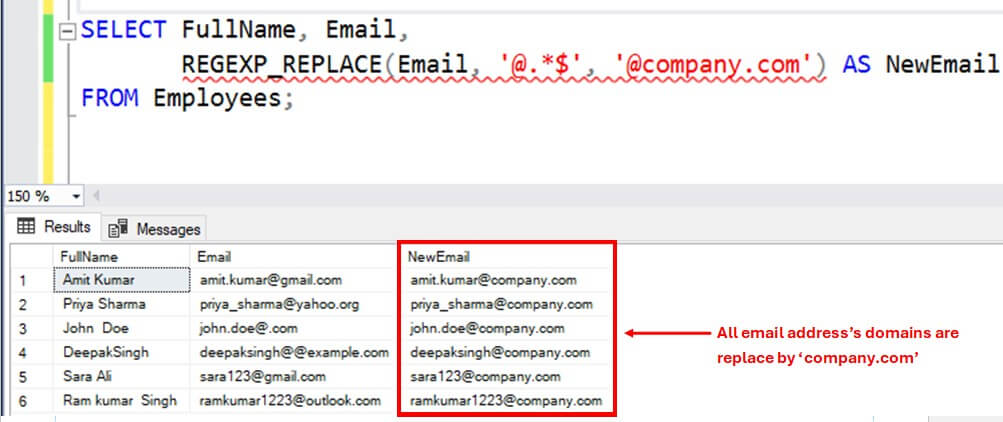
Next example uses a regex @.*$ to replace the domain name of all the email address with @company.com. The regex matches all the characters from @(inclusive) till end of the string and replaces it with @company.com.
SELECT FullName, Email,
REGEXP_REPLACE(cast(cast(Email as nvarchar(max)) as nvarchar(max)),cast(cast( '@.*$' as nvarchar(max)) as nvarchar(max)),cast(cast('@company.com' as nvarchar(max as nvarchar(max))))) AS NewEmail
FROM Employees;
You can see the domains masked below.
REGEXP_SUBSTR()
REGEXP_SUBSTR() takes a input string expression, a regex pattern as input arguments and returns a substring from the string expression which matches the regex pattern. In case of no matches, it returns NULL. The syntax is:
REGEXP_SUBSTR(expression, pattern [, start [, occurrence]])
where the arguments are:
- expression - source string to evaluate
- pattern - regex pattern to extract
- start(optional, default=1) - position to start search
- occurrence(optional, default=1) - which match to return
You can use this function to extract parts of string such as prefix or suffix , lastname and firstname. It handles multiple delimiters in strings like space, tab, digits or special characters.
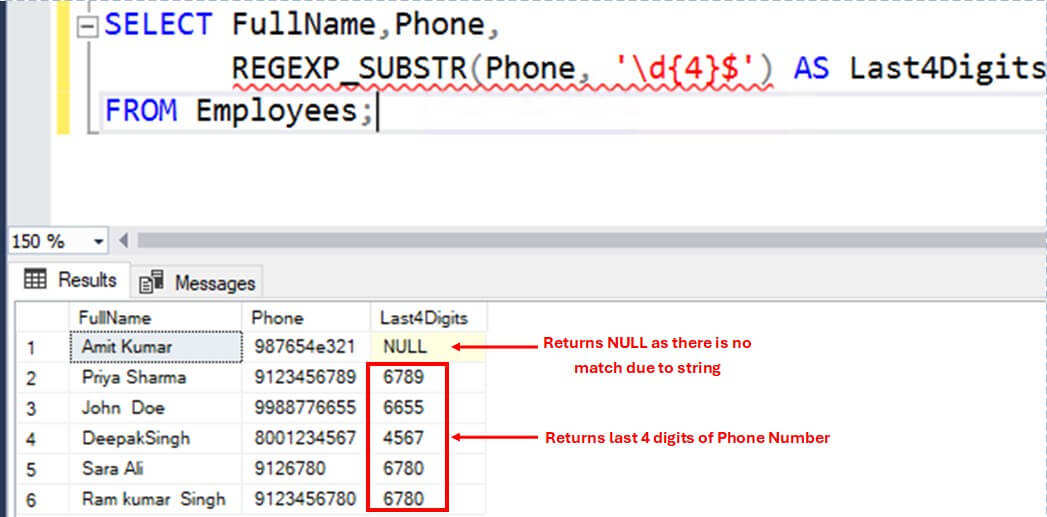
The example below extracts last 4 digits of a phone number using a regex pattern \d{4}$ :
SELECT FullName,Phone,
REGEXP_SUBSTR(Phone, '\d{4}$') AS Last4Digits
FROM Employees;Here are the results, note the first row is null.
The next example extracts the first name and last name of employees into separate columns:
SELECT FullName,
REGEXP_SUBSTR(FullName, '\w+',1,1) AS FirstName,
REGEXP_SUBSTR(FullName, '\w+',1,2) AS LastName
FROM Employees;Here you see the results, note the null in row 4.
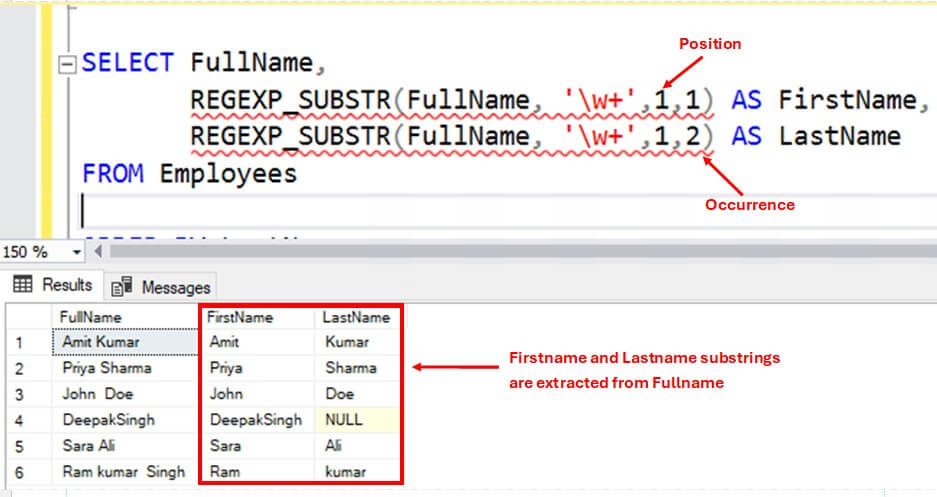
A few observations from the above example:
- Regex \w+ matches multiple word character sequence. For e.g., it matches Amit first, and then matches Kumar separately. It handles the space in between as it is not a word character.
- The optional argument occurrence is set to 1 and 2 respectively to extract firstname and lastname.
- The regex recognizes both tabs and space while splitting the strings(third row is tab-delimited, while others are space-delimited).
- The regex skips the third word(Singh) in sixth row as occurrence is set to only 1 and 2.
REGEXP_COUNT()
REGEXP_COUNT() takes a string expression and a regex pattern as input arguments and returns the number of times the regex pattern matches in the string. In case the pattern doesn't matches, it returns 0. The syntax is:
REGEXP_COUNT(expression, pattern)
where the arguments are:
- expression - source string to evaluate
- pattern - regex pattern to count
You can use this function to count the occurrence of certain expressions like digits counts in an string column or vowel counts in a sentence.
The example below counts the number of digits and special characters in email addresses of employees:
SELECT FullName,Email,
REGEXP_COUNT(Email, '\d') AS Digits,
REGEXP_COUNT(REGEXP_SUBSTR(Email,'^[^@]+'), '[^A-Za-z0-9]') AS SpecialCharacters
FROM Employees;The results are shown below.
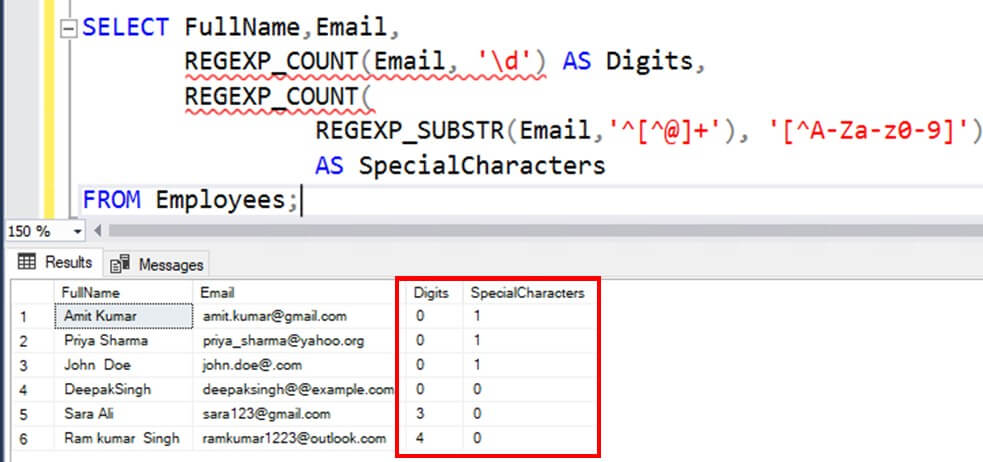
A few observations from the above example:
- Regex \d matches a single digit. REGEXP_COUNT() then sums up each match and returns the output.
- For finding special characters, the example first extracts the username part of the email id using REGEXP_SUBSTR() and ^[^@]+ regex. ^ ensures the match starts from the first character and [^@]+ matches one or more character that are not @.(^ inside [] is used for negation)
- Next using regex [^A-Za-z0-9], it matches all the characters that are not uppercase, lowercase alphabets and digits. REGEXP_COUNT() then sums up each count and returns the output.
REGEXP_INSTR()
REGEXP_INSTR() is used to determine the starting or ending position of a matching substring in a string expression. It takes a string expression and a regex pattern as input arguments and returns the position of the matching substring depending upon the value of return_option argument. The Syntax is:
REGEXP_INSTR(expression, pattern [, start [, occurrence [, return_option]]])
where the arguments are:
- expression - source string to evaluate
- pattern - regex pattern to match
- start(optional, default=1) - position to start search
- occurrence(optional, default=1) - which occurrence to return
- return_option(optional, default=0) - which position to return. 0=start position, 1 =end position
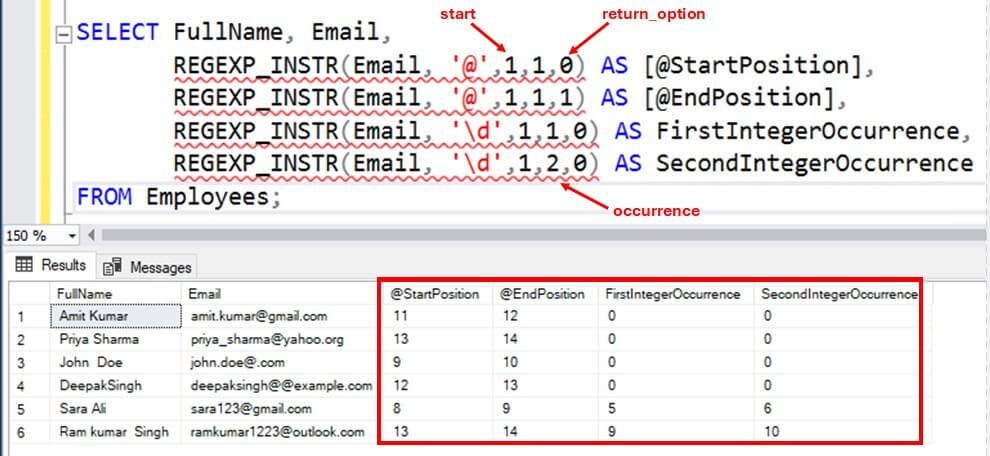
The example below extracts start and end position of @ and first and second occurrence of integer in email addresses of employees:
- The return_option is set to 0 and 1 respectively for '@' to determine it's start and end position in email column.
- The start is set to 1 to begin the search from first character of the string.
- The occurrence is set to 1 and 2 respectively for integer searches to determine only the first and second occurrence.
SELECT FullName, Email,
REGEXP_INSTR(Email, '@',1,1,0) AS [@StartPosition],
REGEXP_INSTR(Email, '@',1,1,1) AS [@EndPosition],
REGEXP_INSTR(Email, '\d',1,1,0) AS FirstIntegerOccurrence,
REGEXP_INSTR(Email, '\d',1,2,0) AS SecondIntegerOccurrence
FROM Employees;Here are the results of the various function calls.
REGEXP_MATCHES()
REGEXP_MATCHES() takes a string expression and a regex pattern as input arguments and returns a table of substrings that matches the regex pattern. The returned table contains additional information about each matched substring, including:
- match_id - order of occurrence of the matching substring
- start_position - first index of the matching substring
- end_position - last index of the matching substring
- match_value -matched substring
- substring_matches - a json column with some additional match details
The Syntax is:
REGEXP_MATCHES(expression, pattern)
where the arguments are:
- expression - source string to evaluate
- pattern - regex pattern to match
You can use this function to split matched strings into separate rows and it handles multiple spaces, underscores, and numbers, in regex pattern.
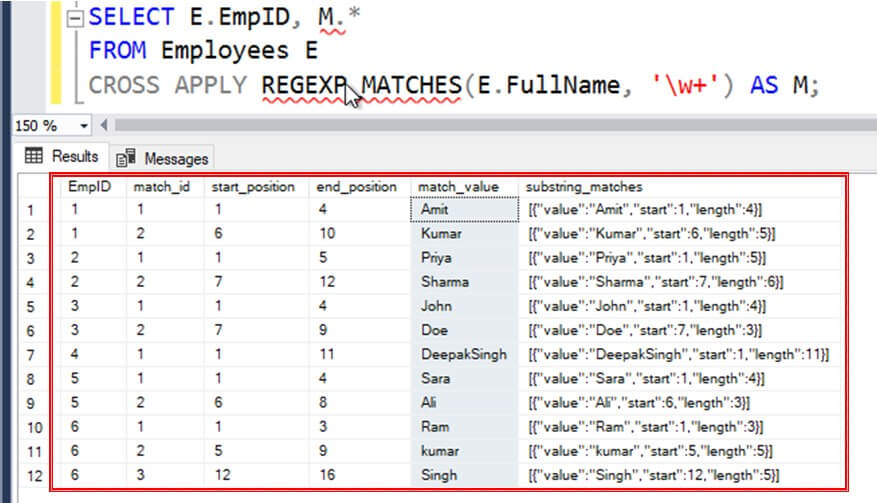
The example below splits the name of employees into separate rows:
SELECT E.EmpID, M.Match_Value FROM Employees1 E CROSS APPLY REGEXP_MATCHES(E.FullName, '\w+') AS M;
The code works as follows:
- The regex \w+ matches multiple word character sequence and used to split the first and last name separated by a space delimiter.
- The match_id column tells the order of occurrence of each substring relative to the input string. For e.g. Amit is the first match and Kumar is the second match in the string 'Amit Kumar'. Hence Amit and Kumar has match_id of 1 and 2 respectively.
- The start_position and end_position tells the starting and ending position of the matched substring. For e.g. in the substring Amit, the first character 'A' is in first position and the last character 't' is in fourth position. Hence the columns have value of 1 and 4 respectively.
- The match_value column contains the matched substring.
- The substring_matches column tells additional information about matched substring in a json format. For e.g. start position and length of substring 'Amit'.
See the results below.
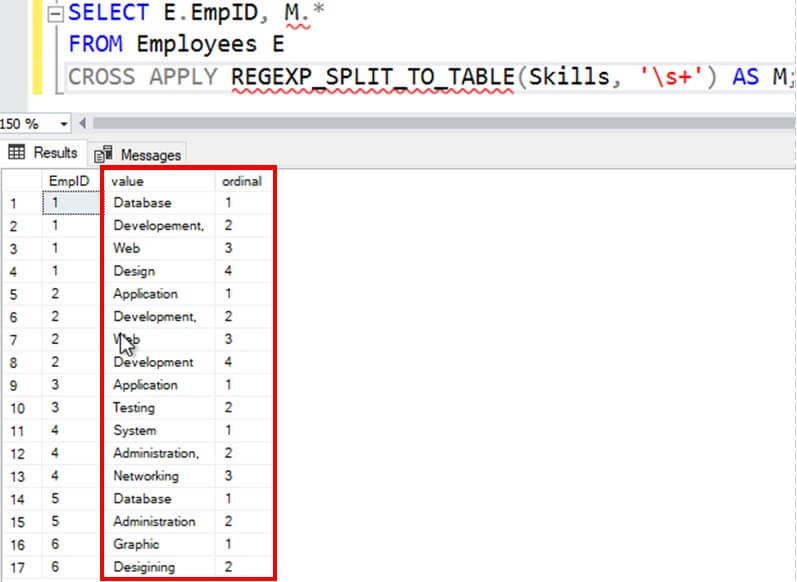
REGEXP_SPLIT_TO_TABLE()
REGEXP_SPLIT_TO_TABLE() is another function which return a substring from input string. It takes a string expression and a regex pattern as input arguments, splits the input string based on the regex pattern and returns a table with substrings. The returned tables includes two columns:
- value - substring split by regex
- ordinal - substring's position in the original string
The Syntax is:
REGEXP_SPLIT_TO_TABLE(expression, pattern)
where the arguments are:
- expression - source string to evaluate
- pattern - regex delimiter
You can use this function to split a string into separate rows based on the specified regex delimiter.
The example below splits the skills of employees into separate rows:
- The regex \s+ matches multiple white space character including space, tab, new line, etc.
- The value column contains the substrings after split.
- The ordinal column tell the relative position of the substring in the original string. For e.g., employee 1 has Database Development and Web Design skills, all separated by a space. Hence it split the skills into four separate words with ordinal values of 1,2,3 and 4 respectively.
Conclusion
Regular Expression in SQL Server is a powerful addition in SQL Server. It enables advance searching and string manipulation directly in T-SQL and reduces the dependency on programming languages. With Regex, pattern matching, data validation(like emails, phone numbers), tokenization, etc. has become more easier and flexible. However regex are difficult to read and excessive use of them on large queries may impact performance. So, be careful if you are implementing it in production environment. It is always recommended to properly analyze and validate the query plans before such implementation.
