

Data Scrubbing with Realistic Randomized Data
Those of us who have to comply with HIPAA and PCI-DSS are used to the notion of data scrubbing certain values for lower-environment databases. Now, GDPR is bringing every single company with data on EU customers a whole new set of nightmares. We no longer only need to consider scrubbing Sensitive Personal Identifying Information (“SPII”), which has traditionally been looked at as credit card numbers and expirations, health identification numbers such as SSN or NIN, Drivers License or state ID number, and date of birth. GDPR requires us to maintain confidentiality and protect all personal information.
Be prepared to reliably scrub names, physical addresses and email addresses from your lower environment data. And it looks like scrambling names won’t be sufficient. “NJHO MHSIT” can rapidly be unscrambled to JOHN SMITH. You will need to do random replacement. For identifying numbers, there are concerns about random numbers actually matching the number of another actual person. GDPR carries gigantic penalties for noncompliance, which for small and medium businesses could easily be enough to destroy the entire company. Therefore, careful planning is critical.
There are tools that do some of this work for you, including some awesome ones from RedGate. If, however, you have something extraordinarily complex, or a stingy boss, you can homebrew something quite wonderful.
Random replacement: Security vs. Usability
While it may be easy to generate a random string, replacing “JOHN SMITH” with “HhDElagsCU QL4xHnKau,” may impede testing. It may be hard for developers and testers to remember a name like this. One solution is random word replacement. What if “JOHN J. SMITH” transmogrifies into “BOOKMAKER E. LEVIATHAN?” It may seem hilarious, but the idea is serious. Make the test data somewhat useable for both code testing and performance testing. Actual words, when compared to random character strings, will likely distribute in an index more like names, giving a better barometer of performance. Actual words are also easier for people to remember, and that will reduce testing time.
These premises gave rise to a case study at our company. We have millions of people in our production databases, and we carry the entire gamut of HIPAA- and GDPR-regulated data. We also have half a dozen lower environments that need to be scrubbed. We’ve elected to go the random-word route for names, and randomization for dates of birth.
Randomizing with the “Words” Database
To that end, I’ve developed a tiny database called “Words,” which can be deployed to any SQL Server 2008+ machine in the company. It contains one table populated with words grabbed from an open-source dictionary, a few UDFs, and a warning not to laugh uncontrollably when one evaluates its results. You will see why as this article continues. I’m going to share the randomization code with everyone. I freely admit that I grabbed the UDF from other places and tuned it up.
Here is the table declaration:
CREATE TABLE [dbo].[wordsEn]( [TheWord] [varchar](50) NOT NULL, [WordID] [int] IDENTITY(1,1) NOT NULL, CONSTRAINT [PK_wordsEn] PRIMARY KEY CLUSTERED ( [TheWord] ASC ) WITH ( PAD_INDEX = OFF , STATISTICS_NORECOMPUTE = OFF , IGNORE_DUP_KEY = OFF , ALLOW_ROW_LOCKS = ON , ALLOW_PAGE_LOCKS = ON ) ON [PRIMARY] ) ON [PRIMARY] GO CREATE NONCLUSTERED INDEX [IX_WORDS_WORDID] ON [dbo].[wordsEn] ( [WordID] ASC ) INCLUDE ( [TheWord] ) WITH ( PAD_INDEX = OFF , STATISTICS_NORECOMPUTE = OFF , SORT_IN_TEMPDB = OFF , DROP_EXISTING = OFF , ONLINE = OFF , ALLOW_ROW_LOCKS = ON , ALLOW_PAGE_LOCKS = ON ) ON [PRIMARY] GO
Very simple. A word and an integer identity PK column on which the table is clustered. There is also a nonclustered index on this column with an include of the keyword, which seems redundant but improves performance. Since the database is tiny, you can live with it. I attach a CSV filled with the words from the open-source dictionary, and you can import it directly into the table or use Excel to morph it into a stack of INSERTs.
Then to get a random set of words, we have a couple of UDF. First, however, we need a view that throws a randomized number back at us in a way that it changes, even if you execute it multiple times in the same row of data. Here is the DDL for the view Get_RAND:
CREATE VIEW [dbo].[Get_RAND] AS SELECT RAND() AS MyRAND GO
Once we have that, we need a bounded-integer random number generator. This is where the UDF RANDBETWEEN comes in. RANDBETWEEN is a simple UDF that throws out an integer within the range specified in the parameters. And here is the RANDBETWEEN DDL:
CREATE FUNCTION [dbo].[RANDBETWEEN](@LowerBound INT, @UpperBound INT)
RETURNS INT
AS
BEGIN
DECLARE @TMP FLOAT;
SELECT @TMP = (SELECT MyRAND FROM Get_RAND);
RETURN CAST(@TMP* (@UpperBound - @LowerBound) + @LowerBound AS INT);
END
GO
And finally, here comes the Random word thrower. Each execution, it will return a different randomized word. Again, it is an extraordinarily simple function. Here is the DDL:
CREATE Function [dbo].[RANDWORD]()
returns VARCHAR(255)
as
BEGIN
return
(
select
top 1
UPPER(LEFT(TheWord,1)) +
LOWER(SUBSTRING(TheWord,2,LEN(TheWord))) as TheWord
from [wordsEn]
where WordId = dbo.RANDBETWEEN(1,(select max(wordid) from WordsEn))
)
END;
GO
Yes, each column of each row filled with random words using this method will require two nested UDF, with the inner function selecting from a view that hits a system function. However, these are fast memory operations after the WordsEn table makes it into memory – which should happen rapidly. Beware that RANDWORD as written expects that the identities of the WordsEn table start at 1 and increment by 1 to the end of the table. It is possible to evade that requirement by writing a nested select to use ROW_NUMBER(), but performance degrades -- at least when I try it here.
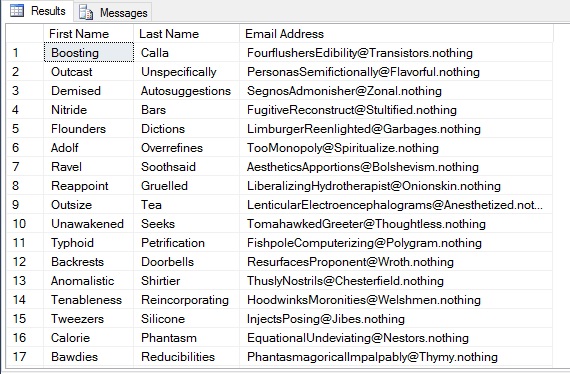
Here is a query to demonstrate what you might get:
select
dbo.RANDWORD() as [First Name]
,dbo.RANDWORD() as [Last Name]
,dbo.RANDWORD() + dbo.RANDWORD() + '@' + dbo.RANDWORD() + '.nothing' as [Email Address]
from master..sysobjectsThis query should produce a couple thousand random names in less than a second. After you stop laughing uncontrollably as you repeatedly press F5 to execute it just to see what comes up, you will see that this method is completely effective at anonymizing your data. The chance that anyone in the world will be named “Razored Writeoff” are pretty much nil – until someone reads this article and decides to prove me wrong. So here is your list of baby names and sample email addresses:
Randomizing Dates
Randomizing dates is quite easy with T-SQL. If you want a nicely-randomized day, try this:
DATEADD(DAY, ABS(CHECKSUM(NEWID()) % 21440), '1949-01-01')The result will be a datetime field that contains a random date between January 1, 1949 and 21,440 days after that day, which is September 14, 2007. You can set the date and day count to produce randomized but realistic birth dates, effective dates, treatment dates or the like, all within the specified range.
Conclusion
You now have the basis of how to anonymize the personally-identifying information of individuals in lower environments. It’s as simple as:
Update CUSTOMER
SET
[First Name] = Words.dbo.RANDWORD()
,[Last Name] = Words.dbo.RANDWORD()
, [Email Address] = Words.dbo.RANDWORD() + Words.dbo.RANDWORD() + '@' + Words.dbo.RANDWORD() + '.nothing';Just don’t run that in production!
----
John F. Tamburo is the Chief Database Administrator for Landauer, Inc., the world's leading authority on radiation measurement, physics and education. John can be found at @SQLBlimp on Twitter. John also blogs at www.sqlblimp.com.


