

If one searches the Internet for the question "What is the Development Framework?”, answers similar to the one below will be found:
"Frameworks are basically the building blocks to an application. Frameworks operate with specific organization. Frameworks were built so that your application can easily be managed without having to sift through hundreds of lines of code just to debug issues. By utilizing a framework you can now separate all of your actions and you can organize your code the way you can easily find the issue and resolve it. This concept of framework organization and reusability will save you hours in applications development."
At the end, an application framework is a set of reusable designs and code that can assist in the development of software applications.
Obviously, this definition of framework is all about a software development framework. Even Wikipedia does not have an article or a definition of a database process framework (DPF). Let's see how we can adapt the application framework concept to the database world to make the lives of data developers and DBAs easier.
The concept of ETL control mechanisms will also be discussed because it is the organic part of the DPF. ETL is the common process for companies that work with different sources of data, using BI for the reporting, analysis and other needs, and transfer of data to data warehouses or data marts. In most cases the process runs without any automated control system or, if there is a control system, it implemented using an entry to a single user table.
When the DPF is mentioned in conversations with database developers and DBAs, it raises eyebrows. This is especially true if it is said that the framework allows the developer to concentrate mainly on the business part of the ETL process because the DPF helps automatically log historical information, process audit information, to enable automated failure notification, including creating different pools of recipients for different processes, and much more.
First let's define the minimal set of criteria before covering how a DPF is constructed.
- It must ensure that a second instance of a process cannot be started until the first instance is finished.
- It must automatically insert historical data for each process and for each step of a process.
- It must know the recipients for a process, including the CC and, BCC recipients.
- It must differentiate between an error and a warning and send a notification email to the proper recipients.
It must be aware of the environment it runs on for some processes: development, staging, UAT, production.Many other requirements can be added to the mix, for example, automated Excel (XLS) reporting file generation and distribution to internal business customers, validation of logical data partitioning between environments, the logical path for the jobs for both process success and failure, and so on.
To address all of the requirements above, a DPF and metadata support database can be created. Metadata support is the organic part of DPF and in reality DPF consists of metadata and set of reusable functions and stored procedures. The complete solution should be stored in a special operational database which is accessible by DBAs, database developers, and processes. To simplify the task, use only stored procedures to implement all database code. Direct data changes and/or data selection are prohibited. Even if SSIS or other tools are used for the processes, all of it should be called from the stored procedure(s). This allows the creation of a set of standard stored procedures to support the DPF.
Now let's review a simple approach to the metadata element of a DPF.
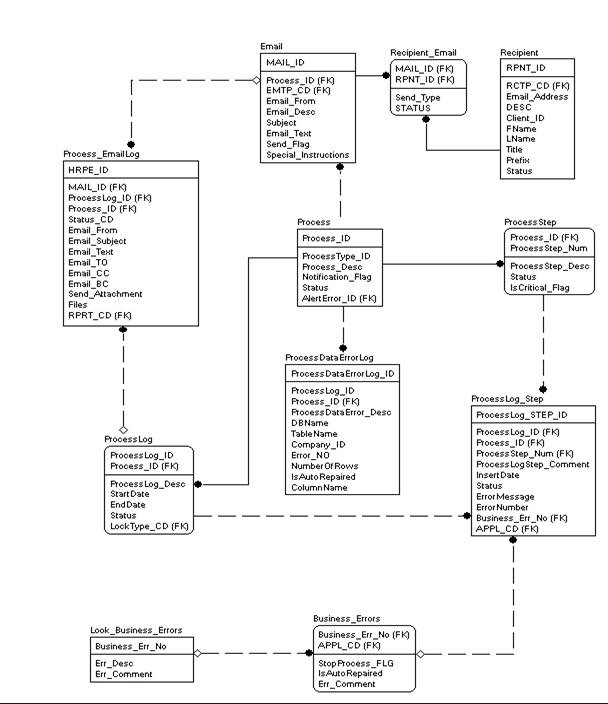
There are set of tables directly involved to describe the process:
Process – Stores processes. Each process has unique process_id. This process_id will be the key for the process framework stored procedures and will be used in all of the procedures as one of the input parameters.
ProcessStep - Includes a description of each process step and defines if this step is critical if case of failure.
Recipient - Stores the list of all recipients for the notifications.
Email - Email with predefined text messages for the process. There are different types of emails based on the email type code (EMTP_CD): success, error, warning, and so on.
Recipient_Email – Stores the list of recipients who will receive email for the process.
Below is the set of log tables that keeps historical information about each process run.
ProcessLog – Keeps a history of the process and process run status. The status is Running while it runs and then status become Success or Fail. (values are ‘R', ‘S', or ‘F')
ProcessLog_Step – Logs the history of every step and has statuses: Running, Success, or Error. It keeps 2 rows for each step, one row when the step started to run and the second row when the step is finished running with Success or Error. If the step has an error then second row will store the error message and error number. Two rows are stored for performance reasons. This table can have a lot of records and insert is much faster than status and end time update based on the fact that primary key column is an identity.
Process_EmailLog – Keeps a history of sent emails with complete email information.
ProcessDataErrorLog – Keeps the database name, table name, column name, company for which the error happened as well as error number, number of failed rows, and flag which shows if this error is automatically taking care of by the process in case of the business logical error.
There are 2 Business error tables: LOOK_Business_Errors and Business_Errors. The first one includes the business errors which are used by the development team. Those errors are registered on the server and will be used by the DPF to raise the proper error message and store it in the log tables in case of a known logical data error. The second table relates business logical errors with specific application(s). In ETL processes the errors are simply grouped into one data group. This table is used in the application framework and stored procedure template, as well to define business defined logical data errors.
The statement below illustrates how to setup a custom error in the SQL Server.
USE master;
go
EXEC sp_addmessage @msgnum = 51001, @severity = 10,
@msgtext = N'Place Error Text Here ',
@lang = 'us_english',
@with_log = 'TRUE',
@replace = 'replace' ;
go
Based on the Microsoft® definition:
sp_addmessage - Stores a new user-defined error message in an instance of the SQL Server Database Engine. Messages stored using sp_addmessage can be viewed using the sys.messages catalog view. You can even create user defined error message with replaceable text pattern.
Remember, a framework is basically the set of building blocks and so now the building blocks must be put together based on metadata.
This set of stored procedures was created, and each one representing a specific DPF method.
dbo.spOPER_Get_Email_Info - based on the process id and email type returns email recipients, base of email text and subject
dbo.spOPER_ProcessRunning – verifyes the process is running
dbo.spOPER_Send_Email – sending email based on the input data and email type. It using spOPER_Get_Email_Info to get the email information.
dbo.spOPER_Set_Process_Lock – setting status to lock the process
dbo.spOPER_Set_Process_Status – changing status of the process
dbo.spOPER_Start_Process – start the process. It verifies that the instance of the process is not running and start the process. It is not allowed to start the process if the process is already running. It uses the procedure spOPER_Verify_Process_Status to verify process status and spOPER_Set_Process_Status to set the process status to Run mode.
dbo.spOPER_Verify_Process_Status – verifying process status – running, failed, success for the last instance of process in history.
dbo.spOPER_Add_Process_Step – add process step. It is used in the process stored procedure template, which will be discussed in this article.
dbo.spOPER_ProcessDataErrorLog – add data to the error log table for the logical errors.
Each stored procedure has multiple input and/or output parameters and works in combination with the other procedures. Each stored procedure or function represent DPF method and each method can be independent or can use the other standard DPF stored procedures or functions. One of parameters for all of the DPF procedures is Process_ID. Below is a list of parameters for each stored procedure.
procedure[dbo].[spOPER_Get_Email_Info] @Process_ID int , @Message_Instructions varchar (255 ) = NULL, @Subject_Instructions varchar (50 ) = NULL, @SUBJECT varchar (255 ) OUTPUT , @TO_RECIPIENTS varchar (4000 ) OUTPUT , @CC_RECIPIENTS VARCHAR (1000 ) OUTPUT , @BCC_RECIPIENTS VARCHAR (1000 ) OUTPUT , @MESSAGE_TEXT varchar (8000 ) OUTPUT , @Email_From varchar (128 ) OUTPUT , @Special_Instructions varchar (255 ) OUTPUT , @Send_Email_FLG char (1 ) output , @Email_ID int output ,@EMTP_CD char (2 ); procedure [dbo] .[spOPER_ProcessRunning] @Process_ID int , @ProcessRun char (1 ) output; procedure [dbo] .[spOPER_Send_Email] @Process_ID int , @Message_Instructions varchar (255 ) = NULL, @Subject_Instructions varchar (50 ) = NULL, @Attachment_FILE_NM varchar (1000 ) = NULL, @Send_Attachments char (1 ) = 'N' , @Additional_Message varchar (4000 ) = NULL, @Additional_Subject varchar (50 ) = NULL, @ProcessLog_ID int = null, @EMTP_CD char (2 ) ; procedure [dbo] .[spOPER_Set_Process_Lock] @PROCESS_ID INT , @Lock CHAR (2 ) ; procedure [dbo] .[spOPER_Set_Process_Status] @PROCESS_ID INT , @STATUS CHAR (1 ) ; procedure [dbo] .[spOPER_Start_Process] @PROCESS_ID INT ; procedure [dbo] .[spOPER_Verify_Process_Status] @PROCESS_ID INT , @STATUS CHAR (1 ), @START_NEW_PROCESS CHAR (1 ) = 'Y' ; procedure [dbo] .[spOPER_Add_Process_Step] @PROCESS_ID INT , @STATUS CHAR (1 ), @PROCESSSTEP_NUM INT , @PROCESSLOGSTEP_COMMENT VARCHAR (255 ) = NULL, @ERRORMESSAGE VARCHAR (255 ) = NULL, @ERRORNUMBER INT = NULL;
How is the process built on this DPF and logically constructed? The drawing below explains.
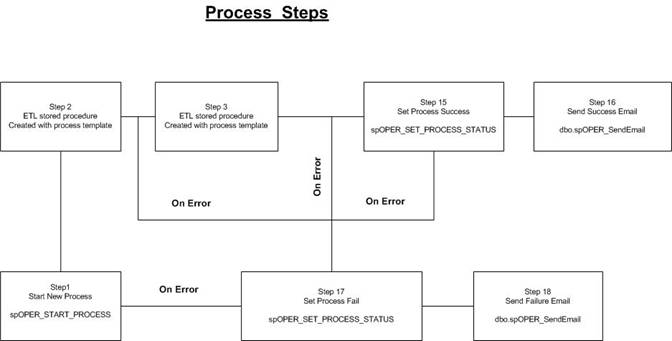
As can be seen from the drawing, there are standard DPF methods are used in some steps. Those standard steps are used for every process. Some DPF methods are used for custom steps as well. For example, DPF methods from steps 1, 15,16,17,18 (the numbers can vary) are standard for all processes. If necessary, nested processes can be built as well. Each one will be running in its own independent shell which looks exactly the same as simple process above. Each process step is created from the standard processing template. The template includes:
- a standard error handling piece which is used for all standard stored procedures
- automatic process step logging
- the ability to run a step outside the process
The last option is there for the DBA to test the step stored procedure without starting a process.
CREATE procedure dbo .TEMPLATE
@PROCESS_ID int , @PROCESSSTEP_NUM int , @PROCESSLOGSTEP_COMMENT varchar (255 ) = null,
@RUN_OUTSIDEOFPROCESS char (1 ) = 'N' ;
as
begin
SET NOCOUNT ON
declare @prog varchar (30 ), @errno int ,@errmsg varchar (1000 ), @proc_section_nm varchar (30 ),
@error_group_cd char (4 ), @row_cnt INT , @error_db_name varchar (50 ),@CreateUserName varchar (128 ) ,
@CreateMachineName varchar (128 ),@CreateSource varchar (128 ), @severitylevel int , -- error severity level.
@err int , -- define general number for logical error
@errline int , @errstate int , @errseverity int;
-- Initialize variables
set @CreateUserName = suser_sname ();
set @CreateMachineName = host_name ();
set @CreateSource = 'App=(' + rtrim (isnull (APP_NAME (), '' )) + ') Proc=(' + isnull (object_name (@@procid ), '' ) + ')';
select @errno = 0 , @errmsg = NULL, @proc_section_nm = NULL,
@prog = LEFT(object_name (@@procid ),30 ),
@row_cnt = NULL, @error_db_name = db_name (), @severitylevel = 16 ,@err = 100000;
-- User Declaration and initialization section
BEGIN TRY
-- Step Started - standard logic.
IF ( @RUN_OUTSIDEOFPROCESS = 'N' )
BEGIN
declare @STATUS CHAR (1 );
set @STATUS = 'R' ; -- step started;
exec Operational .dbo .spOPER_ADD_Process_Step
@PROCESS_ID = @PROCESS_ID , @STATUS = @STATUS ,@PROCESSSTEP_NUM = @PROCESSSTEP_NUM ,
@PROCESSLOGSTEP_COMMENT = @PROCESSLOGSTEP_COMMENT ,@ERRORMESSAGE = @errmsg , @ERRORNUMBER = @errno;
END;
-- User Source code placed below
-- add step successfully ended
IF ( @RUN_OUTSIDEOFPROCESS = 'N' )
BEGIN
set @STATUS = 'S' ; -- step ended successfully
exec Operational .dbo .spOPER_ADD_Process_Step
@PROCESS_ID = @PROCESS_ID , @STATUS = @STATUS ,
@PROCESSSTEP_NUM = @PROCESSSTEP_NUM , @PROCESSLOGSTEP_COMMENT = @PROCESSLOGSTEP_COMMENT ,
@ERRORMESSAGE = @errmsg , @ERRORNUMBER = @errno;
END;
END TRY
BEGIN CATCH
IF @errno = 0
set @errno = ISNULL ( NULLIF ( ERROR_NUMBER (), 0 ) ,@err );
set @errseverity = ERROR_SEVERITY ();
set @errstate = ERROR_STATE ();
set @prog = ISNULL (@prog , ERROR_PROCEDURE () );
set @errline = ERROR_LINE ();
set @errmsg = ltrim (IsNull (@errmsg ,'' ))+'; Sys Msg: ' + ERROR_MESSAGE ();
set @errmsg = 'Error inproc ' + @prog + ' ' + isnull (@errmsg ,' ' );
raiserror (@errmsg , @severitylevel , 1 );
-- set step failed
IF ( @RUN_OUTSIDEOFPROCESS = 'N' )
BEGIN
set @STATUS = 'E' ; -- step has an error
exec Operational .dbo .spOPER_ADD_Process_Step
@PROCESS_ID = @PROCESS_ID , @STATUS = @STATUS ,
@PROCESSSTEP_NUM = @PROCESSSTEP_NUM , @PROCESSLOGSTEP_COMMENT = @PROCESSLOGSTEP_COMMENT ,
@ERRORMESSAGE = @errmsg ,@ERRORNUMBER = @errno;
END;
-- insert an error
EXEC dbo .spERROR_LOG
@CreateUserName = @CreateUserName ,@CreateMachineName = @CreateMachineName ,
@CreateSource = @CreateSource , @ERROR_LOG_PROGRAM_NM = @prog ,
@ERROR_LOG_PROGRAM_SECTION_NM = @proc_section_nm ,@ERROR_LOG_ERROR_NO = @errno ,
@ERROR_LOG_ERROR_DSC = @errmsg ,@error_group_cd = @error_group_cd ,
@error_db_name = @error_db_name ,@ERROR_LINE_NO = @errline ,
@ERROR_SEVERITY_NO = @errseverity ,@ERROR_STATE_NO = @errstate;
END CATCH
SET NOCOUNT OFF
return @errno ;
endIf a logical error is to be plugged into a stored procedure, it can be done by adding the following code:
IF <logical condition> begin set @errno = @err; set @errmsg = '<MESSAGE> '; set @proc_section_nm = 'Section: <section##>'; raiserror (@errmsg, @severitylevel, 1); end
More detailed explanations about the SQL Server stored procedure template can be found in the articles:
- http://www.sqlservercentral.com/articles/Development/anerrorhandlingtemplatefor2005/2295/
- http://www.sqlservercentral.com/articles/T-SQL/63353/
The next drawing illustrates how the DPF can be easily expanded with metadata elements and with the creation of a standard set of new additional stored procedures. For example, a simple automated reporting part can be added. An additional set of framework methods can include, but is not limited to, these next stored procedures:
spRPRT_DeleteOldReports – deleting old report based on report code and number of days or months it has to be kept.
spRPRT_Get_Email_Info – getting email information based on the report code.
spRPRT_RenameReportFile – renames old report file and adding date/time stamp at the end of report file name when the old report is archived and new one is produced.
spRPRT_Send_Report – sending the report to the users based on the report code.
As can be seen from the diagram below, one process can group multiple reports and may require some independent actions based on the report code.
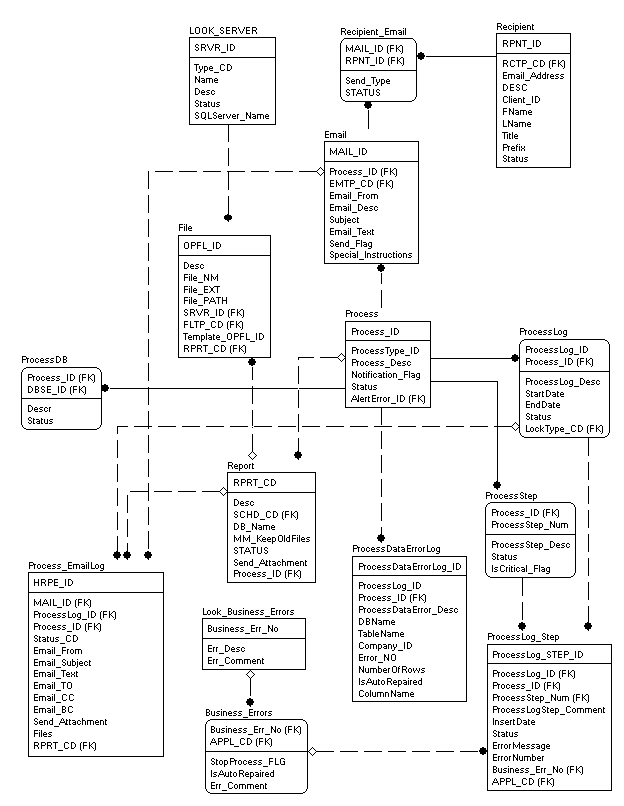
This type of framework has been used by my employer for about 5 years and has grown into a serious set of related and standardized stored procedures with various functional capabilities. It allows our DBA group to do the following:
- Run ETL processes
- Control the history of process output
- Run sets of user and system reports after ETL is complete
- Distribute output to the specified users
- Control the process when multiple jobs run sequentially and/or in parallel
- Define if the current process depends on other processes and if the current process can be run based on the fact whether the other processes already successfully prepared data or failed to do so
Many other standardized functionalities are also built in DPF. A DPF allows for the creation of special logical errors in the process and defines the outcome for every case in which the logical condition is met. In most cases changes to the DPF are made by data architects who analyze how to build generic functionalities into the framework. The data development and DBA groups utilize it to build processes and are able to focus on the business and process specific logic. In our case the DPF and its metadata element were expanded beyond the ETL process. Database server jobs were added as well as a data partitioning control element, data mart and data warehouse standardized load control, and some other functionality.
As previously stated, all metadata tables and framework related stored procedures and user defined functions are kept in the special operational database.
Below is the real process flow of the data mart load with DPF.
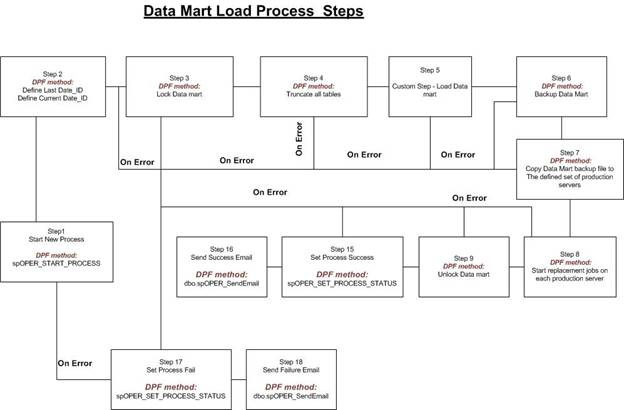
All steps with "DPF method" on the drawing above indicate the standard methods that are used in this particular process and in many other processes across the board in our company. For example, DPF methods from steps 1, 2, 3, 8, 9, 15, 16, 17, 18 are used in processes such as data warehouse differential load, and many different data mart loads. DPF methods from steps 1, 4, 6, 8, 15, 16, 17, 18 are used to load RAW data from external sources. And DPF methods from steps 1, 2, 4, 7, 8, 15, 16, 17, 18 are used to create files for the search engine and copy it to the specified location. These processes are not only using the specified DPF methods, but many other reusable and custom methods as well.
Conclusion
In this short article my goal was to explain that a framework (set of reusable objects and functions) is not exclusively for application development, but one can also be constructed on the back end for the database processes. The article shows the basic concepts of a simple implementation of a database framework, metadata and functions. In reality, implementation will vary and each data architect must decide how robust and complex the framework must be in order to meet the demands of their particular situation.
