

Part 2- Real time data deployment and control mechanism
Part 1 of the article Data Distribution introduced one of the methods to replace data in the data mart by replacing the complete data mart nightly. This method is based on the fact that nightly traffic, e.g. number of calls to the database is very low. There are a few calls per minute and the size of the data mart is limited to 10-15GB. The only issue is that to be able to utilize this load type you have to have good judgment about data mart's current size and the data mart growth rate. In part 2 of the article I will describe how to develop real time data deployment and the control mechanism.
There are multiple problems that we have to overcome with real time data deployment. The main problem is maintaining the integrity of the data distribution while allowing for real time data changes. The main part of the solution is establishing a mechanism on the HUB side responsible for tracking real time data changes. The HUB in our example is a powerful SQL server and we will use it to centralize the data.
Data from various sources is consolidated into this hub by way of a set of ETL processes and will be distributed to the production database using the ETL process. I will describe such a mechanism using a single table as an example. Keep in mind that every table in the database that will be used for the real time data update should use the same control mechanism that will be described for one table below.
First, note that it is not always acceptable, for performance reasons, to identify a changed row by it's primary key because the key might be a combination of a collection of columns. A better way is to have a asynchronous mechanism set up on the source of data that will notify the HUB about any changes of its own data. We can use alerts to initiate a job on the HUB, or if for some external reasons starting a job remotely is prohibited, the HUB can start its jobs on a defined schedule.
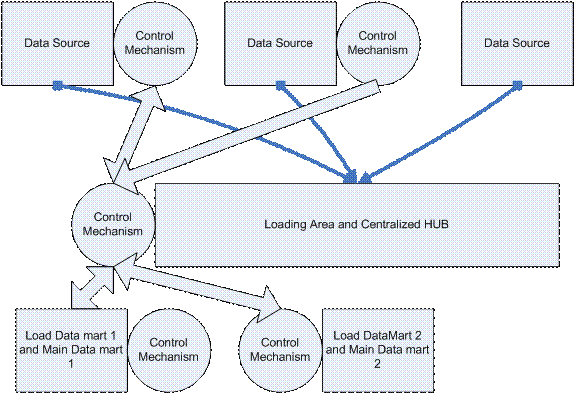
This diagram represents the core of the process. When record(s) are updated in the source table they will be transferred to the HUB and from the HUB to one or multiple destination SQL servers. The control mechanism on each level (source, HUB,destination) ensures that each record will be inserted/updated/deleted with the current iteration of data, or the next iteration in the case of a process failure.
Below is a sample implementation that shows you the real time data deployment to the local database/data mart. In this example the table Client stores all of the company's clients. When a record is updated in the source table, the change will be propagated to all target servers. As you can see, the table has a column row_id uniquely identifying the row. Column row_id will be a computed column with the same value as primary key column, if the primary key column is the identity.
However, if primary key column(s) are not an identity then column row_id will be defined as identity. See below how it is done in the tables Client and Client_Status.
create table client ( client_id int not null identity(1,1) primary key, last_nm varchar(50), first_nm varchar(50), status_cd char(2), row_id as client_id ); create table client_status ( status_cd char(2) not null primary key, descr varchar(100), row_id int identity ); ALTER TABLE client ADD CONSTRAINT [I_FK_client_2] FOREIGN KEY([Status_CD]) REFERENCES client_status ([Status_CD]);
The table below represents a simple control mechanism facilitating the gathering of data about changes in the source database table. All we need to know is which row in which table has been changed. I've added the mod_id column to indicate that multiple rows were changed in one statement. Mod_id may be helpful for the auditing or other purposes, but has no significance for the described process. The control table in the source database only sustains the inserts and never the updates.
CREATE TABLE [dbo].[CNTL_RowAudit](
[RowAudit_ID] [int] IDENTITY(1,1) NOT NULl primary key,
[MOD_ID] [uniqueidentifier] NOT NULL, [ROW_ID] [int] NOT NULL,
[Table_NM] [varchar](100) NOT NULL, [DBAction_CD] [char](1) NOT NULL,
[CreateDate] [datetime] NOT NULL
);
The next step is to create a trigger for each table that will be involved in the real time data movement. The trigger will be inserting one row into the table CNTL_RowAudit for each changed row in the source table. Then the trigger for insert on the table CNTL_RowAudit will raise an error to start the load job. All those events, including job steps, are done within a few seconds (e.g. real time)
Remember that business requirements may not dictate to support the full set of data in real time. For example, the business may need only demographic data changes in real time but not the client's credit history changes, which are distributed with nightly or even weekly loads. The code for the trigger TR_Client is below:
create trigger [dbo].[TR_Client]
on [dbo].[Client] FOR Insert,Update, Delete
as
begin
SET NOCOUNT ON
declare @cnti int, @cntd int, @action char(1), @table_nm varchar(100);
declare @dt datetime, @modid uniqueidentifier;
set @table_nm = 'client';
set @dt = getdate();
set @modid = newid();
set @cnti = -1;
set @cntd = -1;
BEGIN TRY
select @cnti = count(*) from inserted;
select @cntd = count(*) from deleted;
IF (@cnti = @cntd and @cnti > 0)
set @action = 'U';
IF (@cnti > @cntd)
set @action = 'I';
IF (@cnti 0)
ROLLBACK;
--
insert an error into error table or define your’s own logic
END
CATCH
SET NOCOUNT OFF
end
Let us insert some records into the Client_Status and Client tables and verify the trigger output.
insert into client_status (status_cd ,descr)
values ('AC', 'Active');
insert into client_status (status_cd ,descr)
values ('NA', 'Not Active');
insert into client (last_nm , first_nm , status_cd )
select 'Test', 'Test', 'AC';
insert into client (last_nm , first_nm , status_cd )
select 'Test1', 'Test1', 'AC';
Now we can look up the changes made by the trigger:
select * from CNTL_RowAudit; RowAudit_ID MOD_ID ROW_ID Table_NM DBAction_CD CreateDate ----------- ------------------------------------ ----------- --------------- ----------- ---------------- 1 BBF4397F-E3EA-4CAE-AFB9-EDE3A25ABE13 1 client I 2010-04-23 14:07:53.037 2 69A5F7AC-02CA-4D8A-B665-7FD061E61772 2 client I 2010-04-23 14:08:15.343
The next step is to create a trigger on the control table CNTL_RowAudit. The trigger on the control table is fired only on insert because there are no updates or deletes against control table. The code for the control table trigger below:
create trigger [dbo].[TR_CNTL_RowAudit] on [dbo].[CNTL_RowAudit] FOR Insert as begin SET NOCOUNT ON BEGIN TRY raiserror (51080, 10, 1); -- Alert that will start job END TRY BEGIN CATCH IF (@@trancount > 0) ROLLBACK; --====================================================== -- Code to insert an error into error table. Place the custom code here --====================================================== END CATCH SET NOCOUNT OFF End
The trigger is raising an error that is tied to the alert. When the alert is raised, it starts a job. The job may push data to the destination server or send a message to the destination server to start pulling data from the source server. I prefer the second scenario because the source server doesn’t know anything about jobs and processes that are running on the destination server. I would like the destination server to make the decision about when to start pulling data from the HUB. It is possible to build a smart decision making mechanism as the first step of the job on the destination server to be able control when to start the data changes.
To be able hold the transferred data on the target server we should create a permanent load table with the same structure as the transferred data. For performance reasons, I am creating tables with the same data structure as on the HUB (source). However, it can differ in your specific situations.
create table tmp_client ( client_id int not null, last_nm varchar(50), first_nm varchar(50), status_cd char(2),row_id );
The destination server has the same control table as on the HUB (source) server but with a few additional columns. The column Processed_FLG indicates wether a record is processed or not and, if it is processed then if it was succesfully processed. The column Processed_Dt indicates when the record was processed last time. You can create a more sophisticated control mechanism to keep history of processed records in case the record was reprocessed multiple times, unsucessfully processed initially and then reprocessed and so on. The basic idea however, is still the same: at the end all we need to know is if the record has or has not been sucessfully processed.
CREATE TABLE [dbo].[CNTL_RowAudit]( [RowAudit_ID] [int] IDENTITY(1,1) NOT NULl primary key, [MOD_ID] [uniqueidentifier] NOT NULL, [ROW_ID] [int] NOT NULL, [Table_NM] [varchar](100) NOT NULL, [DBAction_CD] [char](1) NOT NULL, [CreateDate] [datetime] NOT NULL, Processed_FLG char(1) not null default 'N', Processed_DT datetime );
With each data change, all the additional records from the source server should be inserted into the control table on the target server. It can be done by SSIS package or by using a linked server, or any other way. Initially, all the records in the control table are marked as not-processed. In the case of successful changes on the destination server all the rows will be marked with Processed_FLG = ‘Y’. In the case of failure, the same rows will be processed a second time because the process will be updating all unprocessed rows.
Remember that each time the process runs, it needs to know which rows and from which table it is required to insert, update, or delete. It is irrelevant how many times the same row_id will be in the control table with an unprocessed status. The process should modify the same row once during run time and then mark all unprocessed rows in the control table with the same row_id as successfully processed. After the control table is loaded on the target server, we can grab the set of changed rows from the source server and store them in table Tmp_Client. It can be done for all tables that are changed in the source server.
Usually, I create a set of stored procedures on the source server: one per each individual table. It allows me quickly to run all of them by using a stored procedure wrapper. It executes each table’s individual procedure from the source server. One of the parameters passed to the procedure is the list of row_ids that were changed. The list can be passed as a collection of comma delimited records, a XML variable, or any other way. Let’s see how a XML can be used:
declare @xmlvar1 xml; declare @emp table (emp_id int primary key); set @xmlvar1 = '1 ' insert into @emp(emp_id) select T1.lst.value('.','int') as emp_id FROM @xmlvar1.nodes('/emp/id') T1(lst); select * from @emp; create procedure changed_client @clientlist XML as begin declare @emp table (emp_id int primary key); insert into @emp(emp_id) select T1.lst.value('.','int') as emp_id FROM @clientlist.nodes('/emp/id') T1(lst); select client_id , last_nm , first_nm , status_cd , row_id from client e inner join @emp te on te.emp_id = e.client_id; end 2
This procedure selects data from the source table and then the wrapper inserts it into the Tmp_Client table on the
destination server. When all temporary tables are inserted, the next step is to insert, update, or delete data in the corresponding tables on the destination server. We tested this methodology to make a real time changes by changing up to 1000 rows of data per second in 10+ tables in parallel. It did not affect applications, users, or server resources.
Since it is unknown when the next batch with changes will arrive, you may have a special mechanism that will run every 1-5 minutes to analyze the unsuccessfully processed records and rerun them again. Needless to say that any control mechanism should be equipped with its own logging and notification facilities.
Conclusion
This article provided a general description of how to reliably synchronize data between different servers in real time or nightly processes while maintaining data integrity. Some additional steps to the process may be required based on the specific implementation of
data calls from the applications or BI tools. The only issue is that to be able to utilize this load type, you have to have a good judgment about the number of changes, the frequency of changes and the data growth rate.
