

Introduction
Foreign Keys (FKs) are one of the fundamental characteristics of relational databases. One FK has to refer to a set of columns that are guaranteed to be unique as a Primary Key (PK), Unique constraint or Unique index. It is a set that always has an index associated to it.
Note 1: The table that has the referenced key is usually called “parent table”, while the “child table” is the one that has the FK constraint.
FKs check data integrity at every insert or update operation in the child table. The following are the other situations where SQL Server uses FKs:
- when a transaction performs a delete or update of the unique part of a record in the parent table
- when joining tables
SQL Server does not automatically define an index as consequence of a FK definition. In this article, we will try to understand if it can be useful to put an index on the FK in the child table and in which cases it helps.
Suggested link: If you want to dig deeper in FKs, an interesting webcast by Kendra Little is available is available here.
Note 2: I have done all my tests with SQL Server 2014 Developer Edition 64 bit.
Delete or update operation in the parent table
When a transaction performs a delete or an update of the unique part in the parent table, SQL Server has to check if any related records exist in the child table. Moreover, if the FK has been defined with Update Cascade or Delete Cascade, SQL Server has to perform operations in the child table that could involve multiple records.
In particular, we will analyse what happens in a situation where the FK has been defined with Cascade Actions.
In this example, I am going to create a new test database called TestFk and two minimal tables in it: Headers and Details. As you can see in the following script, there is the FK_Details_Headers FK defined in the Details table with both “Update Cascade” and “Delete Cascade”. Each of these two tables has one row.
IF NOT EXISTS (select 1 from sys.databases WHERE name = 'TestFk')
BEGIN
CREATE DATABASE [TestFk]
ALTER DATABASE [TestFk] SET RECOVERY SIMPLE
END
GO
USE [TestFk]
GO
IF OBJECT_ID('Details') IS NOT NULL DROP TABLE Details
IF OBJECT_ID('Headers') IS NOT NULL DROP TABLE Headers
CREATE TABLE Headers (
HeaderId INT NOT NULL PRIMARY KEY)
CREATE TABLE Details (
DetailId INT NOT NULL PRIMARY KEY,
HeaderId INT NOT NULL)
ALTER TABLE Details ADD CONSTRAINT [FK_Details_Headers] FOREIGN KEY(HeaderId)
REFERENCES Headers (HeaderId)
ON UPDATE CASCADE
ON DELETE CASCADE
GO
INSERT INTO Headers VALUES (1)
INSERT INTO Details VALUES (1, 1)
GO
Script 1
Now it is time to look at how the “Delete Cascade” works. To do that select “Include Actual Execution Plan” in SSMS and carry out the following statement that opens a new transaction and deletes one record from the Headers table:
SET TRANSACTION ISOLATION LEVEL READ COMMITTED BEGIN TRAN DELETE FROM Headers WHERE HeaderId = 1
Script 2
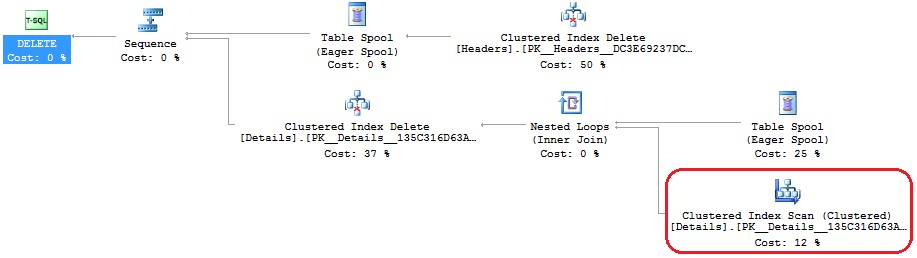
In the following picture, we can see the execution plan that has been used. You can notice that SQL Server does a “Clustered Index Scan” on the Details table in order to find all records that it has to delete.
The transaction is still open and it is interesting to look at how many locks and which type of locks SQL Server makes use of. Run the following statement to see this:
SELECT * FROM sys.dm_tran_locks GO
Script 3
The following picture shows the result of Script 3. The values of the request_mode column show that SQL Server uses a “range level lock” because it has to delete all the child rows in the Details table that are linked to the row of the Headers table that is going to be deleted. Even though the transaction has explicitly started with “READ COMMITTED” Isolation Level, SQL Server uses the “SERIALIZABLE” Isolation Level on the Details table. This escalation is called “Isolation Level Upgrade”

Note: You can obtain a very similar situation with a PK update on the Headers table; this would trigger the “Update Cascade”.
This escalation from Read Committed to the Serializable Isolation Level can cause deadlocks. An index on the FK can help to reduce the number of reads and the execution time.
Rollback the previous transaction and carry out the following script that creates an index on the FK:
CREATE NONCLUSTERED INDEX [Idx_HeaderId] ON [dbo].[Details] ( [HeaderId] ASC )
Script 4
Carrying out the previous delete statement and looking at the execution plan, you can see that SQL Server takes advantage of the index:

Joins
In order to show some interesting patterns of behaviour of indexes defined on FKs, we are going to create an Orders table and a Customers table in the TestFk database. The Customers table has the “Percentage” field that represents the percentage of rows of the Orders table referred to a particular customer. The Orders table has the “Filler” field that I am going to use to modify the records dimension.
The following script creates the Orders table and the Customers table with a foreign key on CustomerId. Moreover, it inserts 10 rows in the Customers table with a different percentage value for each row; the sum of all the percentages is 15. No indexes other than the PK has been defined on the Orders table.
USE [TestFk]
GO
IF OBJECT_ID('Orders') IS NOT NULL DROP TABLE Orders
GO
IF OBJECT_ID('Customers') IS NOT NULL DROP TABLE Customers
GO
CREATE TABLE Customers (
CustomerId INT NOT NULL,
ContactName NVARCHAR(30) NOT NULL,
Percentage DECIMAL(5,2) NULL
CONSTRAINT pk_Customers PRIMARY KEY (CustomerId)
)
GO
CREATE TABLE Orders (
OrderId INT NOT NULL IDENTITY(1,1),
CustomerId INT NULL,
OrderDate Datetime,
ShippedDate Datetime,
RandomField FLOAT NOT NULL,
Filler CHAR(100),
CONSTRAINT pk_Orders PRIMARY KEY (OrderId),
CONSTRAINT fk_Customers FOREIGN KEY (CustomerId)
REFERENCES Customers(CustomerId) ON UPDATE NO ACTION
ON DELETE NO ACTION
)
GO
INSERT [dbo].[Customers] ([CustomerId], [ContactName], [Percentage]) VALUES (1, N'Cust n° 1', CAST(0.20 AS Decimal(5, 2)))
INSERT [dbo].[Customers] ([CustomerId], [ContactName], [Percentage]) VALUES (2, N'Cust n° 2', CAST(0.50 AS Decimal(5, 2)))
INSERT [dbo].[Customers] ([CustomerId], [ContactName], [Percentage]) VALUES (3, N'Cust n° 3', CAST(1.00 AS Decimal(5, 2)))
INSERT [dbo].[Customers] ([CustomerId], [ContactName], [Percentage]) VALUES (4, N'Cust n° 4', CAST(1.30 AS Decimal(5, 2)))
INSERT [dbo].[Customers] ([CustomerId], [ContactName], [Percentage]) VALUES (5, N'Cust n° 5', CAST(1.40 AS Decimal(5, 2)))
INSERT [dbo].[Customers] ([CustomerId], [ContactName], [Percentage]) VALUES (6, N'Cust n° 6', CAST(1.50 AS Decimal(5, 2)))
INSERT [dbo].[Customers] ([CustomerId], [ContactName], [Percentage]) VALUES (7, N'Cust n° 7', CAST(1.60 AS Decimal(5, 2)))
INSERT [dbo].[Customers] ([CustomerId], [ContactName], [Percentage]) VALUES (8, N'Cust n° 8', CAST(2.00 AS Decimal(5, 2)))
INSERT [dbo].[Customers] ([CustomerId], [ContactName], [Percentage]) VALUES (9, N'Cust n° 9', CAST(2.30 AS Decimal(5, 2)))
INSERT [dbo].[Customers] ([CustomerId], [ContactName], [Percentage]) VALUES (10, N'Cust n° 10', CAST(3.20 AS Decimal(5, 2)))
GO
ALTER INDEX [pk_Customers] ON Customers REBUILD
Script 5
This is the situation of the Customers table:

The following script modifies the dimension of the Filler column, setting it to 200 characters. It then truncates the Orders table, inserts 10,000, and finally rebuilds all indexes defined (at the moment only the one referring to the PK). The script uses variables for both “size of Filler field” (@FillerLength) and “number of Orders table rows” (@NumRec); you can see them at the top of the script. In this way, ithge script will be easier to modify in further examples.
DECLARE @FillerLength INT = 200
DECLARE @NumRec INT = 10000
--Modify FILLER column
DECLARE @AlterSql NVARCHAR(100) = N'ALTER TABLE Orders ALTER COLUMN Filler CHAR(' + CAST(@FillerLength AS nvarchar(5)) + ')'
EXEC sp_executesql @AlterSql
--Truncate table Orders
TRUNCATE TABLE Orders
--Insert Orders
DECLARE @DateFrom DATETIME = '20100101'
DECLARE @DateTo DATETIME = '20150101'
;WITH Cte (n)
AS (SELECT 1
UNION ALL
SELECT n + 1
FROM Cte
WHERE n < @NumRec)
INSERT INTO Orders (OrderDate, RandomField, Filler)
SELECT
(SELECT(@DateFrom +(ABS(BINARY_CHECKSUM(NEWID())) % CAST((@DateTo - @DateFrom)AS INT)))),
CHECKSUM(NEWID()), 'X'
FROM Cte
OPTION (MAXRECURSION 0)
--Update Orders
;WITH
ReorderedOrders AS (SELECT OrderId, RandomField, ROW_NUMBER() OVER (ORDER BY RandomField) AS Num
FROM Orders),
WorkingPerc AS (SELECT c.CustomerId as CustomerId, c.Percentage,
PrevPerc = SUM(c.Percentage) OVER (ORDER BY c.Percentage ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING)
FROM Customers c)
UPDATE Orders
SET CustomerId = ca.CustId, ShippedDate = OrderDate + 10
FROM Orders o
INNER JOIN ReorderedOrders ro ON o.OrderId = ro.OrderId
OUTER APPLY (SELECT TOP 1 c.CustomerId as CustId
FROM WorkingPerc c
WHERE (c.Percentage * @NumRec / 100) + (ISNULL(c.PrevPerc,0) * @NumRec / 100) >= ro.Num
ORDER BY c.Percentage) ca
GO
ALTER INDEX ALL ON Orders REBUILD
Script 6
Let’s start to analyse the behaviour of a query without indexes defined on the FK. The following query performs two clustered index scans, followed by a Hash Match and it does 306 logical reads on the Orders table (and 2 on the Customers table, but this is not relevant).
SELECT o.OrderId, o.CustomerId, o.OrderDate, c.ContactName FROM Orders o INNER JOIN Customers c ON o.CustomerId = c.CustomerId WHERE c.ContactName = 'Cust n° 1' OPTION (RECOMPILE)
Script 7

Note
From now on, I will refer to the above query (Script 7) as the “test-query”
Now let’s create an index on the FK using the following script:
CREATE NONCLUSTERED INDEX IX_Orders_CustomerId ON dbo.Orders ( CustomerId ) GO
Script 8
Someone could think that if we run the test-query again, the execution plan would take advantage of the new index. Not in this case. Run the test-query again and check it. The execution plan is identical to the previous one. Strange, isn’t it?
Let’s consider Script 6 again and change the initialization of the variable @FillerLength, setting it at 320 in order to increase the dimension of the Orders table. After that, run the modified Script 6, run the test-query again and look at the execution plan and the logical reads. This time the index has been used and the logical reads on the Orders table are now 50.
Obviously, the Query Processor considers many elements in order to decide the best strategy to obtain the records and one of these seems to be the dimension of the records. In this case, the threshold is 312 for the length of Filler field: below this value, the Query Processor chooses not to use the index and performs a table scan.
But there is another important thing to point out: if you carry out the test-query filtering for “Cust n° 10” there will be another surprise. In fact, this customer has many more orders than the “Cust n° 1” (320 vs 20); the Query Processor still uses the index, but this time the logical reads done on the Orders table are many more than a table scan would have carried out: 673 vs 306!
Someone may think that a Filtered Index would help to avoid situations where a table scan is better than an index usage. You can try this by modifying the IX_Orders_CustomerId index definition:
CREATE NONCLUSTERED INDEX [IX_Orders_CustomerId] ON [dbo].[Orders] ( [CustomerId] ASC ) WHERE CustomerId < 10 WITH (DROP_EXISTING = ON)
Script 9
Execute the test-query and filter for any customer you like. The index will not be used, no matter what your choice. It seems that Filtered Indexes do not help in this situation. Re-create the index again in its original form, without the “WHERE” clause.
Up till now, we have seen three scenarios:
- An index exists, but it is not used
- An index exists, it is used and it works better than a table scan
- An index exists, it is used and it works worse than a table scan
For the next test, consider Script 6 again, leaving the variable @FillerLength set to 320, increasing @NumRec up to 20,000 and executing it (remember that in the above example, with @FillerLength set to 320 and @NumRec set to 10,000, the Query Processor chose to use the index).
If you carry out the test-query, you will see that this time the Query Processor ignores the index and performs a table scan. The reason of this is that, in this case, we have many more records than before and the threshold is higher: if you want to see the index working again, set the variable @FillerLength to a number bigger or equal to 328.
It seems that the Query Processor considers both the number of records and their dimension linked in some way in order to find the best plan.
During all the tests, I noticed that other elements that can influence the Query Processor strategy are:
- The number of records of the parent table
- The percentage of records of the child table that have a NOT NULL value in the FK
- Different percentages of usage for each record of the parent table
Until now, we have used the whole Script 6 for every test; it truncates the Orders table, inserts new records and rebuilds all the defined indexes. However, in realistic situations things are different. Let’s see how the behaviour changes performing some operations, without any truncation, except for the one used during the initialization. Keep in mind the results we obtained before.
The first step is to initialize the Orders table: run Script 6 with @FillerLength = 200 and @NumRec = 10,000. As we saw before, our test-query performs a table scan.
Now suppose that we have been told to increase the Filler field size up to 210 characters:
ALTER TABLE Orders ALTER COLUMN Filler CHAR(210) GO
Script 10
We are still below the threshold of 312 that we saw before and if we run the test-query we would expect a table scan again. If you try it, you will see that… the index is now used! It seems that a little change of the record dimension is enough to make the Query Processor consider the index.
Now suppose that day-by-day new orders are inserted. Run the following script that inserts 250 rows keeping the right percentage for each customer:
CREATE TABLE #Orders (
OrderId INT NOT NULL,
CustomerId INT NULL,
OrderDate Datetime,
ShippedDate Datetime,
RandomField FLOAT NOT NULL,
Filler CHAR(100)
)
GO
--Insert Orders
DECLARE @NumRec INT = 250
DECLARE @DateFrom DATETIME = '20100101'
DECLARE @DateTo DATETIME = '20150101'
;WITH Cte (n)
AS (SELECT 1
UNION ALL
SELECT n + 1
FROM Cte
WHERE n < @NumRec)
INSERT INTO #Orders (OrderId, OrderDate, RandomField, Filler)
SELECT
n as OrderId,
(SELECT(@DateFrom +(ABS(BINARY_CHECKSUM(NEWID())) % CAST((@DateTo - @DateFrom)AS INT)))) OrderDate,
CHECKSUM(NEWID()) RandomField, 'X' Filler
FROM Cte
OPTION (MAXRECURSION 0)
--Update #Orders
;WITH
ReorderedOrders AS (SELECT OrderId, RandomField, ROW_NUMBER() OVER (ORDER BY RandomField) AS Num
FROM #Orders),
WorkingPerc AS (SELECT c.CustomerId as CustomerId, c.Percentage,
PrevPerc = SUM(c.Percentage) OVER (ORDER BY c.Percentage ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING)
FROM Customers c)
UPDATE #Orders
SET CustomerId = ca.CustId
FROM #Orders o
INNER JOIN ReorderedOrders ro ON o.OrderId = ro.OrderId
OUTER APPLY (SELECT TOP 1 c.CustomerId as CustId
FROM WorkingPerc c
WHERE (c.Percentage * @NumRec / 100) + (ISNULL(c.PrevPerc,0) * @NumRec / 100) >= ro.Num
ORDER BY c.Percentage) ca
INSERT INTO Orders
SELECT CustomerId, OrderDate, OrderDate + 10, RandomField, Filler
FROM #Orders
GO
DROP TABLE #Orders
Script 11
If you carry out the test-query, you will see that the index is still used. No surprises at all this time!
However, every production database should have its index maintenance plan, so we can suppose that a rebuild could be performed on the Orders table. Try to carry out the following statement:
ALTER INDEX [pk_Orders] ON Orders REBUILD GO
Script 12
This “rebuild” takes the table structurally back to the original point, when we created and initialized it, and the test-query performed a table scan. Now we are in the same condition! Carry out the test-query: the index is not used and the Query Processor chooses a table scan.
Neither the rebuild of the FK index nor the REORGANIZE causes the same effect.
The consequence is that you can have an index that from one day to the next could stop working!
Conclusion
Foreign Keys are one of the fundamental characteristics of relational databases; they make sure that integrity rules are respected and the check is carried out at database level. They can be defined with “Update Cascade” and/or “Delete Cascade” and in this case, an index on the FK can help to avoid deadlocks and to reduce the execution time.
An index can also help in queries with a join between two tables linked by a relationship of parent / child through a FK; there are cases in which an index exists and it is useful, other cases in which it is not used or it is used but a table scan would have been better.
Be careful because a rebuild of the clustered index of the child table could influence the Query Processor that could choose a table scan instead of using the index.
Sometimes defining an extended index with more fields than the FK could help, but it depends on the situation.

