

Introduction
Shell Scripts are widely used in various systems, whether it be for system administration or performing ETL processing. Shell Scripts are mostly designed to perform specific capabilities that an administrator needs. For example, let's say we have a monitoring script that loops through 200 Unix servers and gathers CPU/memory utilization, available mount points, and their available storage. Assume this script runs for 5 hours. During this 5 hours of execution time, the script could abort due to an error caused by various reasons. If the script aborts after having looped through 100 servers, we need to be able to restart the script from the point of failure, with the 101st server, instead of repeating work of starting with the 1st server. It is imperative to design and develop shell scripts that have restart capability. In this article we would explain how to implement restart capability in shell scripts.
Implementing Restart Capability
Let’s say we have a shell script that takes a file containing list of filenames as input and is designed to archive all files listed. If there are large files that are supposed to be moved from one Unix mount point to a different one as part of archival, this process could run for hours and is is possible the script gets interrupted. On restarting this script, it would fail again because the script would try to move the files and some of them would have already been moved before the abort. Having restart capability in script would help restart the shell script from point of failure that would result reduction in manual effort and significant cost saving to support application.
A restart capability would be very helpful for scripts that apply patches on multiple servers or get information from multiple servers. If these kinds of scripts fail and can’t be restarted from the point of failure, they would require a large amount of reprocessing, wasting lot of time and system resources.
In order to understand, how to implement a restart capability in shell scripts, we would use below sample shell script that takes a file list, ArchiveFileList.txt, as an input file. ArchiveFileList.txt has a list of filenames that need to be archived. The script creates another file, ArchiveFileListComplete.txt, during its execution . As the shell script archives/process each file successfully, it creates an entry in ArchiveFileListComplete.txt. This ArchiveFileListComplete.txt is used to keep track of files that have already been archived.
In the case where we restart the shell script after a failure, ArchiveFileListComplete.txt is compared with ArchiveFileList.txt and file name entries that are present in ArchiveFileListComplete.txt would be ignored. Only files that exist in ArchiveFileList.txt and not in ArchiveFileListComplete.txt would be processed.
#!/bin/ksh
#------------------------------------------------------------------------------|
#| Archives Files from Landing Area to Archive
#|-----------------------------------------------------------------------------|
#| Program Name: restartable.ksh
#|-----------------------------------------------------------------------------|
#| Description: This process Archives File from Landing Area to Archive Area
#|-----------------------------------------------------------------------------|
#| Author : Imran Q Syed
#| Date: 03/26/2020
#|-----------------------------------------------------------------------------|
#| Change Log
#| Date By Description
#| ---- ------ -----------------------------------------------|
#| 03-26-2020 Imran Q. Syed Initial Creation
#|-----------------------------------------------------------------------------|
#*********************************************************************
# Function to Echo and Log to log file
#**********************************************************************
echoen() {
echo "$*" | tee -a ${LOGFILE}
}
#*********************************************************************
# Archive Files
#**********************************************************************
archive() {
#-----Start of Loop to Process Files Listed in ArchiveFileList.txt------#
for file in `cat ${TEMPDIR}/ArchiveFileList.txt`
do
#------------Check if the file was processed earlier-------------#
if grep -w ${file} ${TEMPDIR}/ArchiveFileListComplete.txt > /dev/null 2>&1; then
continue
fi
#———Moving Files from Input Directory to Archive Directory——#
echoen "Moving File ${INPUTDIR}/${file} to ${ARCHIVEDIR}/${file}"
mv ${INPUTDIR}/${file} ${ARCHIVEDIR}/${file}
#--------------Check if the move completed successfully or not -----#
if [[ $? == 0 ]]; then
echoen "Moved Successful ${INPUTDIR}/${file} to ${ARCHIVEDIR}/${file}”
echo "$file >> ${TEMPDIR}/ArchiveFileListComplete.txt
else
echoen "Could not move file ${INPUTDIR}/${file} to ${ARCHIVEDIR}/${file}"
echoen "Aborting with exit code -15"
exit -15
fi
done
#————Resetting the ArchiveFileListComplete After All Files are processed———#
>${TEMPDIR}/ArchiveFileListComplete.txt
}
######### MAIN ##################
#--------------------------------------------------------------------
#Assigning the Program name, checking for parameters
#--------------------------------------------------------------------
INPUTDIR=$1
TEMPDIR=$2
ARCHIVEDIR=$3
PROG=`basename $0`
CURR_TS=`date +"%Y-%m-%d-%H.%M.%S"`
LOGFILE=${TEMPDIR}/${PROG}_${CURR_TS}.log
USAGE="USAGE:${PROG} ${INPUTDIR} ${TEMPDIR} ${ARCHIVEDIR}"
if [[ ${#} != 3 ]]; then
echoen "ERROR: ${PROG}: Error due to wrong number of parameters passed to the script"
print "$USAGE"
echoen "Exiting with Status Code of 5"
exit 5
fi
#--------------------------------------------------------------------
# echoen Parameters.
#--------------------------------------------------------------------
echoen "Starting ${PROG} at ${CURR_TS}"
echoen "TEMPDIR : " ${TEMPDIR}
echoen "INPUTDIR : " ${INPUTDIR}
echoen "ARCHIVEDIR : " ${ARCHIVEDIR}
echoen "LOGFILE : " ${LOGFILE}
echoen ""
echoen "-------------------------------------------------------------"
echoen "Archiving Files"
echoen "-------------------------------------------------------------"
archive
####### END ####################The restart capability is coded in the archive function in the shell script. We will concentrate more on following section of the code.
archive() {
#-----Start of Loop to Process Files Listed in ArchiveFileList.txt------#
for file in `cat ${TEMPDIR}/ArchiveFileList.txt`
do
#------------Check if the file was processed earlier-------------#
if grep -w ${file} ${TEMPDIR}/ArchiveFileListComplete.txt > /dev/null 2>&1; then
continue
fi
#———Moving Files from Input Directory to Archive Directory——#
echoen "Moving File ${INPUTDIR}/${file} to ${ARCHIVEDIR}/${file}"
mv ${INPUTDIR}/${file} ${ARCHIVEDIR}/${file}
#--------------Check if the move completed successfully or not -----#
if [[ $? == 0 ]]; then
echoen "Moved Successful ${INPUTDIR}/${file} to ${ARCHIVEDIR}/${file}”
echo "$file >> ${TEMPDIR}/ArchiveFileListComplete.txt
else
echoen "Could not move file ${INPUTDIR}/${file} to ${ARCHIVEDIR}/${file}"
echoen "Aborting with exit code -15"
exit -15
fi
done
#————Resetting the ArchiveFileListComplete After All Files are processed———#
>${TEMPDIR}/ArchiveFileListComplete.txt
}In the above code related to THE archive function, we are looping through the ArchiveFileList.txt file one file name at a time. In each loop, we try to grep that file name in “ArchiveFileListComplete.txt”. As described earlier, ArchiveFileListComplete.txt file is generated by shell script and maintains list of files that have been successfully archived. If the script is running for first time, then ArchiveFileListComplete.txt will be blank and as each file is archived successfully that file name would be added to ArchiveFileListComplete.txt
If the script aborts after archiving few files, then the ArchiveFileListComplete.txt would have file names that have already been archived. Upon restarting the failed script, the script would try to loop through all the files names in ArchiveFileList.txt and try to find the corresponding file names in ArchiveFileListComplete.txt using grep function, if the file name is found in ArchiveFileListComplete.txt, then it would skip that file else it would archive that file.
Script Executions in Multiple Scenarios
In this section we will walk through 2 scenarios. One scenarios where script completes successfully without any failure. Another scenario where script aborts during execution and is restarted from point of failure.
Scenario 1: Script Completes Successfully and Archives all files.
Below we see ArchiveFileList.txt containing File Names to be archived.

Actual Files to be archived in the file system:
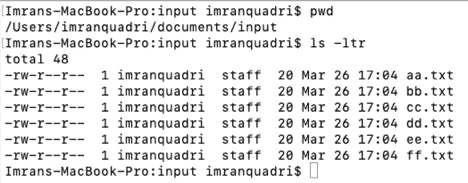
We execute the script with this command:
ksh restartable.ksh /Users/imranquadri/documents/input /Users/imranquadri/documents/temp /Users/imranquadri/documents/archive
The script executes and and moves files that were in the directory, /Users/imranquadri/document/input. Below we see they have been moved to the archive directory, /Users/imranquadri/documents/archive, as shown in below image.
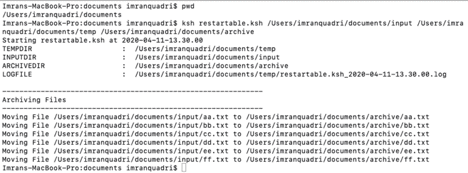
All files are now successfully moved to archive directory, /Users/imranquadri/documents/archive.

Scenario 2: Start Shell script, we will kill it while its running and then we will restart it to show shell script would start from point of failure.
Before starting the shell script, the File List “ArchiveFileList.txt” has name of all the files that need to be archived and “ArchiveFileListComplete.txt” is blank as no files have been moved.

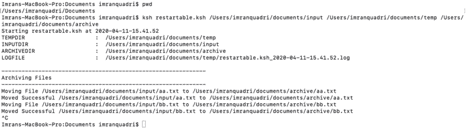
Now I will start the script and kill (Control+c) it after it processes first 2 files.
ksh restartable.ksh /Users/imranquadri/documents/input /Users/imranquadri/documents/temp /Users/imranquadri/documents/archive
Now let’s check the file ArchiveFileListComplete.txt to see if these 2 files that have been moved are logged in it.
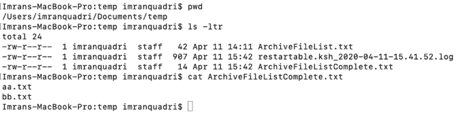
Both the “aa.txt” & “bb.txt” files are cataloged in “ArchiveFileListComplete.txt”
Now let’s restart failed script.
ksh restartable.ksh /Users/imranquadri/documents/input /Users/imranquadri/documents/temp /Users/imranquadri/documents/archive
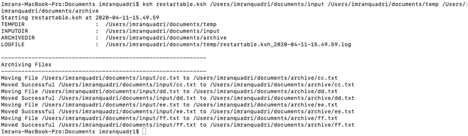
Looking at the above screen shot you will notice that on restarting, the script started processing from “cc.txt” and ignored “aa.txt and “bb.txt” files mentioned in “ArchiveFileList.txt” as these files were already processed. If we didn’t have this re-startability feature then the script would have failed upon restarting as it would have tried to move the “aa.txt” and “bb.txt” file and these files no longer exist in “/Users/imranquadri/documents/input” script would have failed.
For ease of understanding the above script was related to archiving/moving of files. In many other cases, we could be looping through a list of servers to apply patches to each server or to get number of users on each server and many other server details. In cases, where we have to connect to 200 servers and apply patch on each server and if the script let’s say, aborts at 100th server then without restart-ability feature, the script upon restart would start from beginning connecting from the very first server. This restart-ability feature will help skip the servers that have already been processed.
A Common Mistake
A common mistake that developers tend to make, irrespective of technology is to use an "or" condition instead of an "and" condition when there are two negative conditions being used together. We will use below sample file Invoice.txt for understanding.
Invoice.txt file
InvoiceId|CustomerId|InvoiceDate|BillingAddress|BillingCity|BillingState|BillingCountry|BillingPostalCode|Total|StoreID 1|2|2007-01-0100:00:00|Theodor-Heuss-Straße34|Stuttgart||Germany|70174|1.98|1|aa 2|4|2007-01-0200:00:00|Ullevålsveien14|Oslo||Norway|0171|3.96|2|bb 3|8|2007-01-0300:00:00|Grétrystraat63|Brussels||Belgium|1000|5.94|3 6|37|2007-01-1900:00:00|BergerStraße10|Frankfurt||Germany|60316|0.99|6 7|38|2007-02-0100:00:00|Barbarossastraße19|Berlin||Germany|10779|1.98|7 8|40|2007-02-0100:00:00|8,RueHanovre|Paris||France|75002|1.98|8 9|42|2007-02-0200:00:00|9,PlaceLouisBarthou|Bordeaux||France|33000|3.96|9 10|46|2007-02-0300:00:00|3ChathamStreet|Dublin|Dublin|Ireland||5.94|1 11|52|2007-02-0600:00:00|202HoxtonStreet|London||UnitedKingdom|N15LH|8.91|2 12|2|2007-02-1100:00:00|Theodor-Heuss-Straße34|Stuttgart||Germany|70174|13.86|3 13|16|2007-02-1900:00:00|1600AmphitheatreParkway|MountainView|CA|USA|94043-1351|0.99|4 14|17|2007-03-0400:00:00|1MicrosoftWay|Redmond|WA|USA|98052-8300|1.98|5 15|19|2007-03-0400:00:00|1InfiniteLoop|Cupertino|CA|USA|95014|1.98|6 16|21|2007-03-0500:00:00|801W4thStreet|Reno|NV|USA|89503|3.96|7 17|25|2007-03-0600:00:00|319N.FrancesStreet|Madison|WI|USA|53703|5.94|8 18|31|2007-03-0900:00:00|194AChainLakeDrive|Halifax|NS|Canada|B3S1C5|8.91|9
Now say, we have a requirement to NOT display records with InvoiceId of 1 or 2. Here is the Awk Command with the "OR" (||) condition.
awk -F"|" '$1!=1||$1!=2{print $0}' Invoice.txtIf you see below both the records with InvoiceId of “1” and InvoiceId of “2” are displayed. The reason being when the first record with InvoiceId of “1” is being processed, it fails condition of InvoiceId!=1 but it passes the condition of InvoiceId!=2, overall filter condition passes as both the negative conditions (InvoiceId!=1, InvoiceId!=2) are separated by an “OR” (||) condition. An “OR” condition needs only one of the 2 conditions to pass. Similarly, when the record with InvoiceId of “2” is being processed, condition of Invoice!=1 passes but the condition of InvoiceId!=2 fails. For “OR” condition one condition needs to be met for the statement to become true and in this case condition of InvoiceId!=1 is being met so, record with InvoiceId of “2” pass the filter and is displayed.

The correct condition to use when 2 negative statements are together is to use an “AND” boolean instead of “OR” boolean. The correct statement would look like this.
awk -F"|" '$1!=1&&$1!=2{print $0}' Invoice.txt1!=1&&$1!=2 double ampersand “&&” means “AND” condition.
If you see below both the records with InvoiceId of “1” and InvoiceId “2” are NOT displayed. The reason being when the record with InvoiceID of “1” is being processed the awk commands check if the InvoiceId does not equal to 1 and invoice Id not equal to 2. In this case the InvoiceId not equal to 1 fails and InvoiceId not equal to 2 passes but as the “AND” boolean is being used, both the conditions need to be met for the statement to evaluate to TRUE and pass the filter. Similarly, when the record of InvoiceId of “2” is being processed at that time the first condition InvoiceId does NOT equal to 1 passes but the other condition InvoiceId does NOT equal to 2 fails. For “AND” Boolean to work both the condition should be true that’s the reason both the records are filtered out.

Conclusion
By implementing the restart ability feature showed in above article shell scripts or any other programming scripts would be have capability to restart on failure reducing significant amount of support hours. Also, by avoiding the common mistake explained in above article it would reduce retesting effort by QA, reduce overall time to production and project cost.
Biographical notes: Imran Quadri Syed is a Lead System Developer at Prime Therapeutics and has 12 plus years of professional experience in Data Warehousing and Client-Server application packages. Imran’s main area of work involves implementing complex technical solutions to support Business Intelligence Reporting Systems. Imran vast experience varies from legacy technologies like mainframes, Data warehousing technologies (DataStage/Informatica) and latest big data technologies. Imran has completed Bachelor’s in Electronics and Communication Engineering from Jawaharlal Nehru Technology University in 2004. He has completed his Masters in Electrical Engineering from City University of New York in 2006.
