

Problem
Often while working with SQL Server Analysis Services, developers come across many errors that restrict them from deploying or processing the cube. In this article, I'm going to explain the reason that causes the Duplicate Key error in SSAS. This is one of the errors that occurs quite frequently and is usually caused by the incorrect configuration of the key properties of the dimension members. I'll try to replicate the error first and then explain how this error can be resolved.
Please note that this article focuses on how to resolve the error and doesn't explain how to create an Analysis Services project from scratch.
Reproducing the Error in SSAS
Let us first ready our environment by preparing test data that can be used for demonstration purposes. I'll insert two records into a simple table for the initial setup. You can execute the step below to replicate the same.
CREATE TABLE DupKeyDemo( [CustomerID]INT, [Customer]VARCHAR(50), [Amount]INT ) GO
Once the table is created, insert the records by executing the statement below.
INSERT INTO DupKeyDemo VALUES (1,'John',100), (2,'Greg',200)
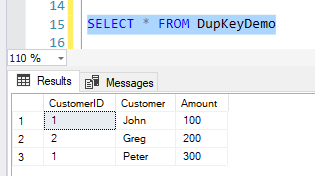
If we select data from the table, it appears as follows.
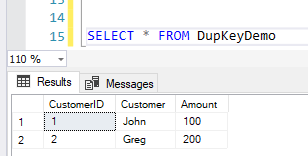
Now, that our base tables are ready, let's quickly build the SSAS project. Fetch this table in the data source view and create a cube from it.
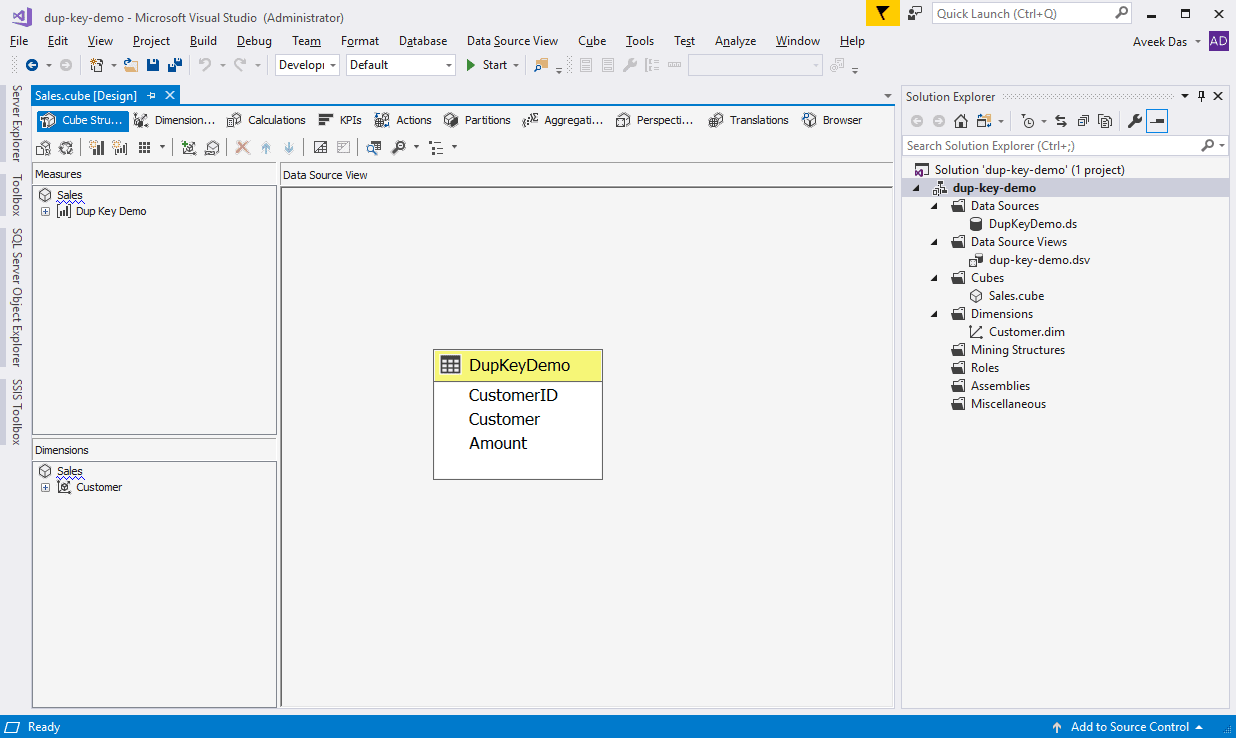
For creating the cube, select the Dimension as Customer. For the member, select the Key Column as "CustomerID" and the Name Column as "Customer".
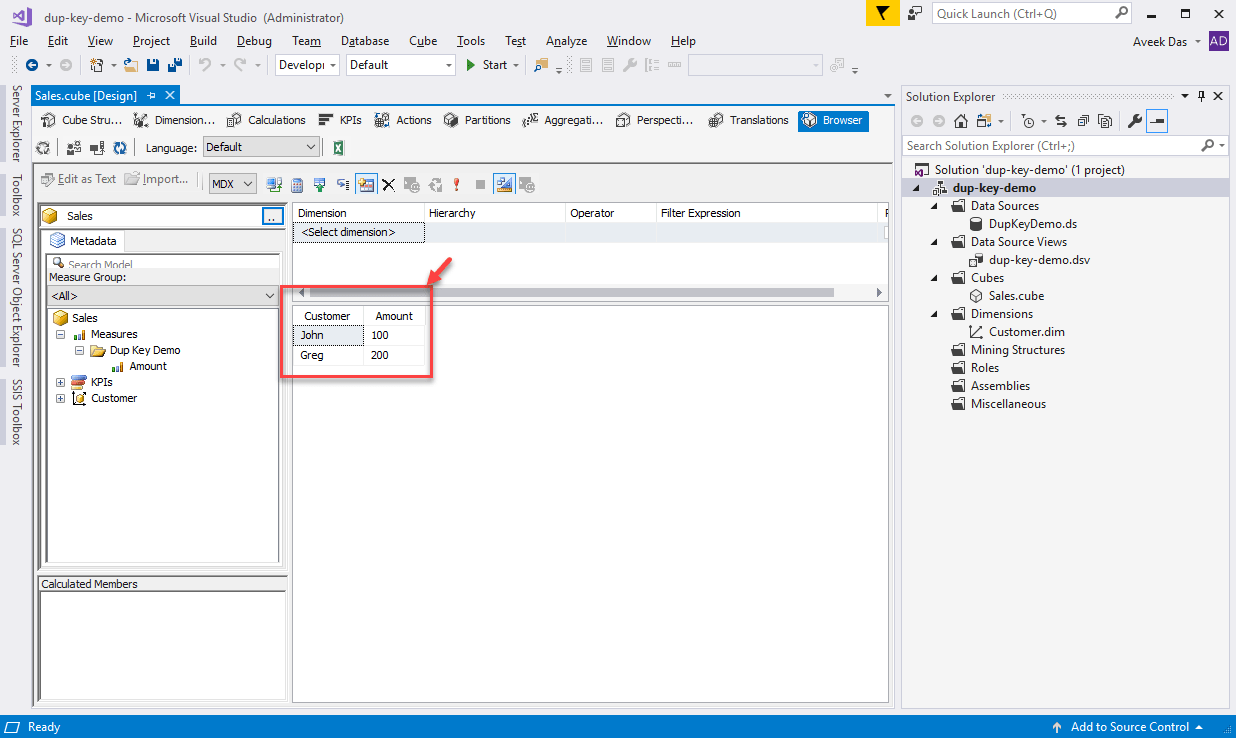
Now that the cube is created, we can deploy and process the cube. Once the cube is processed successfully, we can easily browse it.
Now that we can browse our cube, let us modify our data and try to reprocess the cube. We will now insert one more record into the base table, but with the same CustomerID.
INSERT INTO DupKeyDemo VALUES (1,'Peter',300)
However, now when we try to process the cube, there is an error stating that a duplicate key has been found and the cube cannot be processed further.
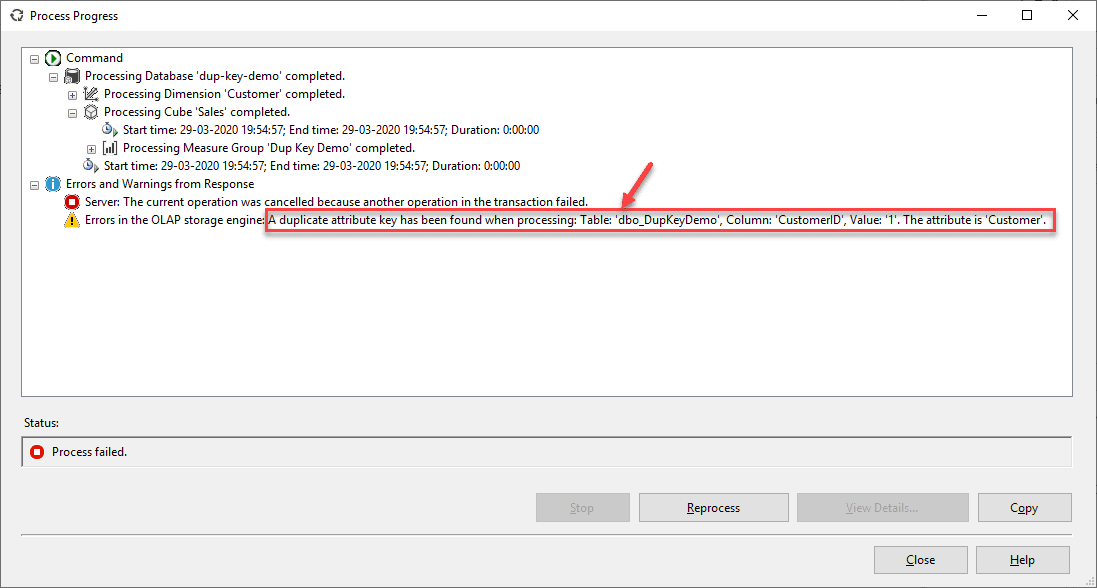
As you might have already guessed, this error is due to the fact that we have two records in the Customer dimension but with the same CustomerIDs.
Solution
Now that we have reproduced the error, let us try to resolve it.
Well, when I think of a solution for this error, the first thing that comes to my mind is to look into the source data and see if the ID column has correct values or not. If not, we can simply modify the records and then try to re-process the cube again. However, there might be cases where the underlying data is correct, or you do not have sufficient permissions to update the data. In such cases, the solution has to be implemented in SSAS solution only.
Let us now dive into the Customer dimension and alter the properties to support this error. Right-click on the Customer dimension and select Properties.
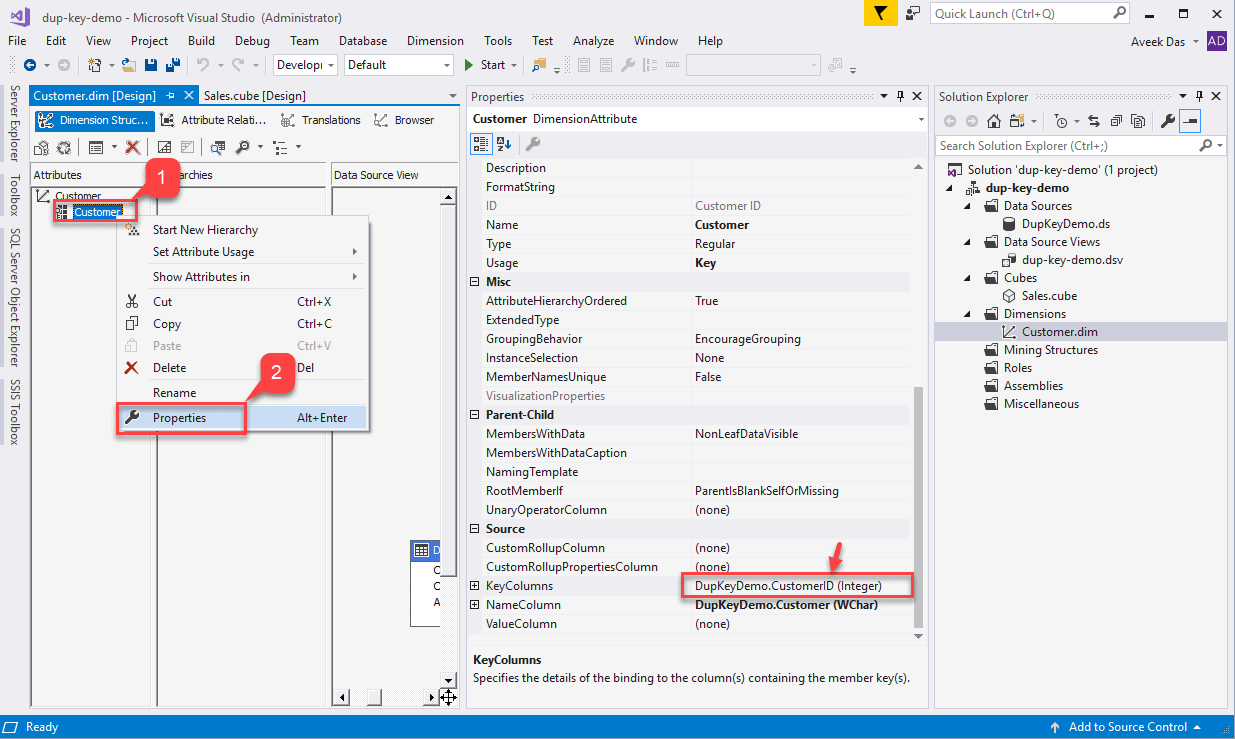
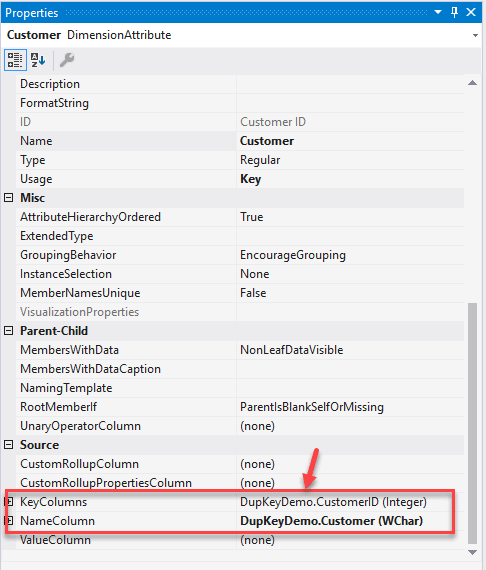
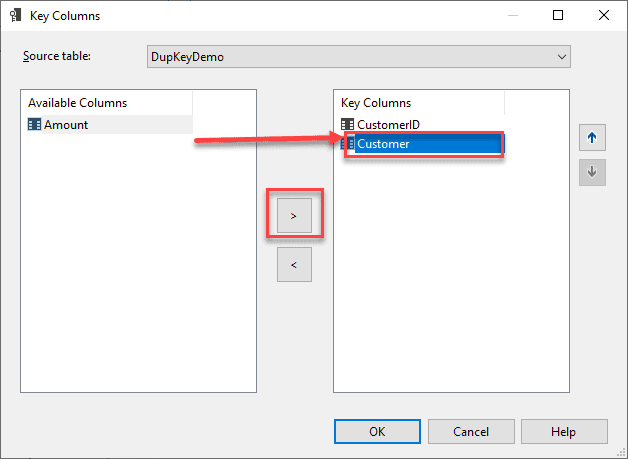
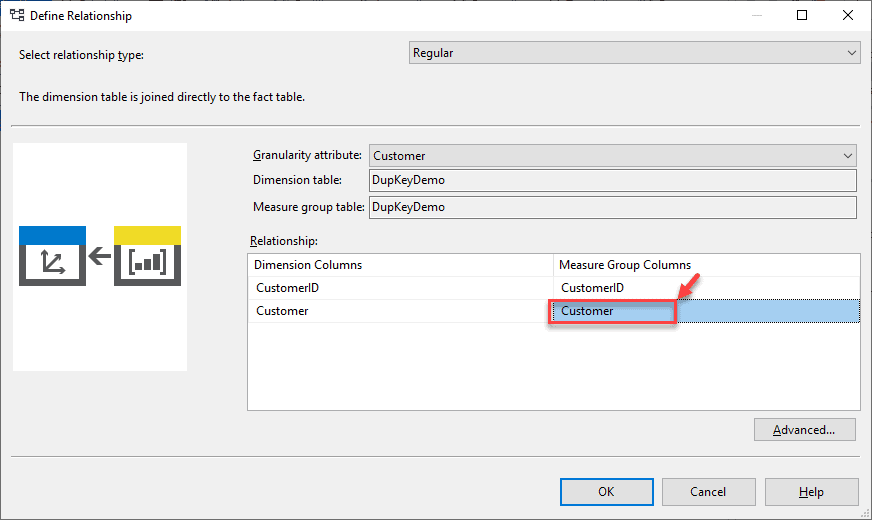
Click on the browse button just on the right on the KeyColumns. Select the Customer from the Available Columns and click the ">" button.
The Customer is added to the list of Key Columns now. Essentially, what this does is now, it will consider a combination of both CustomerID and Customer as a unique combination and then process the cube. Since the dataset also contains a unique combination of both these columns, the SSAS engine can easily process the cube without any errors.
The next change here we need to make is to instruct the above change in the cube as well. Open the cube that we created and click on the Dimension Usage tab.
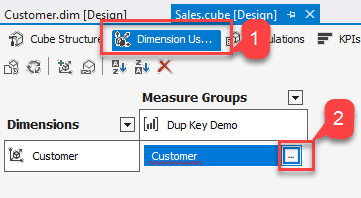
In the window that opens, add the Customer to the Measure Group Columns as highlighted in the figure below and click OK.
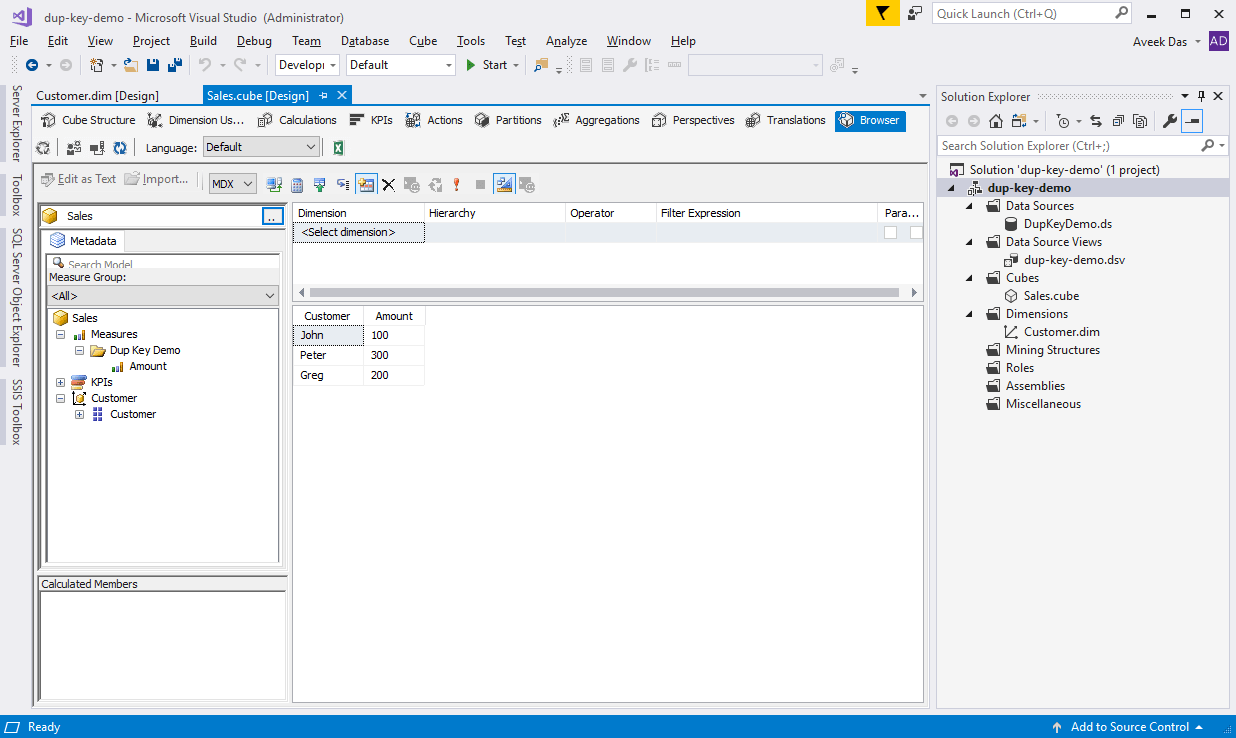
Once the above change has been implemented, you can try to process and browse the cube as follows. Notice that now the error has been resolved and all the customers are displayed with the cube is browsed.
Conclusion
In this article, I have explained how to resolve the duplicate key error in SQL Server Analysis Services. I have also tried to reproduce the error in this article and then provide a solution for the same. To learn more about this error you can follow this post.