

Introduction
A client of mine — a mid-sized manufacturing company — had been using SQL Server for years to power their factory operations and dashboard. Over time, they upgraded from Access to SQL Server 2005 to 2012, then to 2016, and finally 2019.
But one thing never changed: the way their code was written.
They had migrated their old C++ and Microsoft Access logic straight into SQL Server stored procedures — WHILE loops, row-by-row updates, procedural thinking — without ever pausing to ask:
“Are we utilising SQL Server capabilities to fullest”
It was legacy code wrapped with a pure legacy thinking until everything worked.
But one morning this escalation email shouted in our mail box.
“Why is our entire factory dashboard freezing up every morning?”
That’s what they asked me during a particularly stressful week — and after digging in, the answer pointed to a WHILE loop in one stored procedure… a loop that had been quietly killing performance for years.
Note: Everything in this article is based on my own memory and practical experience. I’m simply recreating what I once diagnosed for a real-world client.
A Bit of Backstory
This client had grown steadily over the years. Back in the early 2000s, their factory-floor software was written in C or C++ — the go-to choice for interacting with barcode readers, counters, machine interfaces etc These languages offered the raw speed and memory control needed for real-time operations.
For data storage They used Microsoft Access as It was cheap, local, came with Office, and MS ACCESS MDB files were easy to copy and hand over to supervisors. C/C++ applications interacted with Access using ODBC — not common today, but very doable back then.It worked fine when things were small. But as the factory grew and the data kept growing, that old setup just couldn’t keep up anymore.
Fast forward a few years: they migrated from Access to SQL Server 2005 to 2012 to SQL Server 2016 and then finally at at 2019, and the desktop C/C++ app was replaced with a Java-based system. But the procedural logic — WHILE loops, row-by-row processing, legacy constructs — was ported 1-to-1 into SQL Server stored procedures. Nobody realized that loops at scale in SQL Server could grind performance into the dirt.
The real horror wasn’t the loop.
It was that nobody ever revisited the logic after moving from Access to SQL Server 2008… then 2012… then 2016… and even 2019.
They kept upgrading the engine, but never touched the old procedural code still running under the hood.
Even after SQL Server 2012 introduced advanced windows function SUM() OVER (ORDER BY ...) for doing cumulative sum in optimised way, this took us a long time to pause and find:
“Ohh we can ditch this WHILE loop and use SQL Server awesome windows functions for calculating cumulative calculations for inventory?”
So every factory, every shift, every product line — all of it was still suffering from that Access-era, loop-based, row-by-row thinking… in a platform that was capable of so much more.
The Culprit: A WHILE Loop Inside a Stored Procedure
Here’s a simplified version of what was happening every time they tried to calculate a “rolling total” of manufactured units:
This logic works fine for a few rows.
But they were calling this for each product, in every factory, multiple times per day.
Recreating the Issue — Straight from My Own Memory
Let’s simulate the same problem using SQL. First, we’ll create a table to represent production log data. It will hold 100 days of production information for 1,000 products — giving us 100,000 rows to work with.
Here’s what’s happening in simple words: This block of SQL clears out any existing ProductionLog table and creates a fresh one with three columns: ProductID, ProductionDate, and UnitsProduced. Then, using SQL Server’s system tables as a convenient number generator, it simulates 100 days of production data for 1,000 different products(P0000 to P0999). The number of units produced each day is randomly generated to mimic realistic variation in production activity.
Simulating Factory Production Data with 100,000 Rows
This script creates a table named ProductionLog to simulate factory output and populates it with 100,000 rows by generating production data for 1,000 products across 100 days. The ProductID values are formatted as strings like 'P0001' to 'P1000', generated using RIGHT('0000' + CAST(p AS VARCHAR), 4). The ProductionDate is calculated by adding an offset d to a fixed start date of January 1, 2023. The number of UnitsProduced per entry is randomized using ABS(CHECKSUM(NEWID()) % 100), creating values from 0 to 99. The row generation relies on two derived tables that pull 1,000 and 100 rows respectively using ROW_NUMBER() over sys.all_objects, and their Cartesian product yields the full 100,000-row dataset for insertion.
DROP TABLE IF EXISTS ProductionLog;
CREATE TABLE ProductionLog (
ProductID VARCHAR(10),
ProductionDate DATE,
UnitsProduced INT
);
-- Insert 100 days of data for 1,000 products (100,000 rows)
INSERT INTO ProductionLog (ProductID, ProductionDate, UnitsProduced)
SELECT
'P' + RIGHT('0000' + CAST(p AS VARCHAR), 4),
DATEADD(DAY, d, '2023-01-01'),
ABS(CHECKSUM(NEWID()) % 100)
FROM
(SELECT TOP 1000 ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) - 1 AS p FROM sys.all_objects) AS Products,
(SELECT TOP 100 ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) - 1 AS d FROM sys.all_objects) AS Days;
Simulating the Legacy WHILE Loop Logic being used by Factory softwares
To simulate the same procedural logic that the factory had carried forward from their older system, we recreated the stored procedure pattern using a WHILE loop. First, we stored main table in a temporary table called #Sorted. This table included an identity column (RowNum) to represent row positions, so we could simulate a rolling window manually by looking at previous rows. Once that was in place, we counted how many rows we had for that product and stored it in @MaxRow.
The second temporary table, #Out, was created to store the final rolling 7-day sums. Then came the heart of the legacy logic — a WHILE loop that manually iterated over every row. For each row, we ran a nested SELECT query to calculate the sum of the current row and six rows before it, using the RowNum boundaries. We used a CASE check to ensure that we didn’t go below row 1 for the first few days. This computed sum, along with the corresponding production date, was inserted into the #Out table.
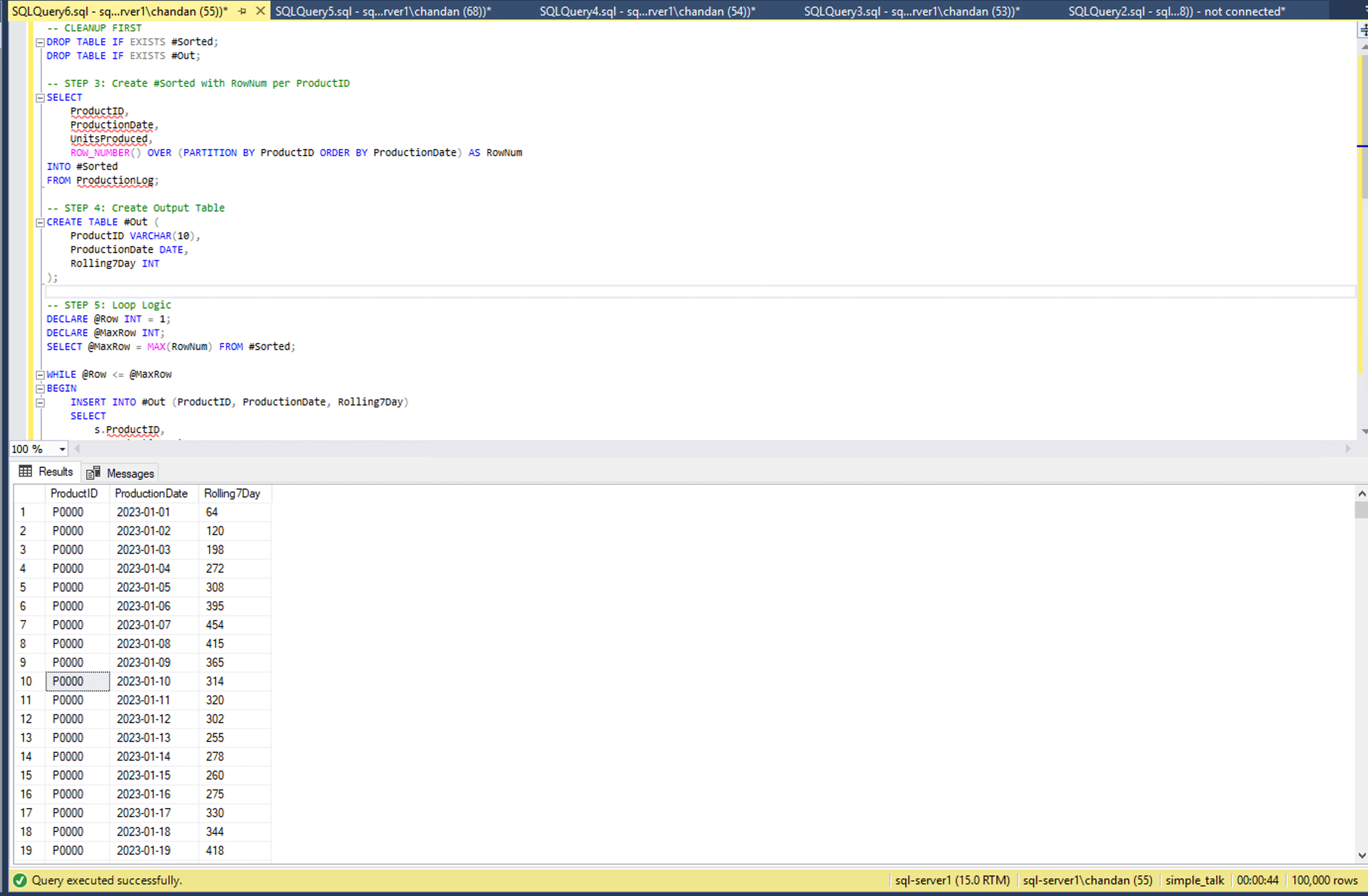
Finally, after the loop completed, we selected all the results. This approach was almost a line-for-line replica of how their procedural loop-based calculation worked. Even on a relatively small dataset with 30 days of data, this loop-based simulation took around 44 seconds to complete. That’s still quite slow — and imagine the impact when this same logic was executed across hundreds of products every shift in a live environment.
-- CLEANUP FIRST
DROP TABLE IF EXISTS #Sorted;
DROP TABLE IF EXISTS #Out;
-- STEP 3: Create #Sorted with RowNum per ProductID
SELECT
ProductID,
ProductionDate,
UnitsProduced,
ROW_NUMBER() OVER (PARTITION BY ProductID ORDER BY ProductionDate) AS RowNum
INTO #Sorted
FROM ProductionLog;
-- STEP 4: Create Output Table
CREATE TABLE #Out (
ProductID VARCHAR(10),
ProductionDate DATE,
Rolling7Day INT
);
-- STEP 5: Loop Logic
DECLARE @Row INT = 1;
DECLARE @MaxRow INT;
SELECT @MaxRow = MAX(RowNum) FROM #Sorted;
WHILE @Row <= @MaxRow
BEGIN
INSERT INTO #Out (ProductID, ProductionDate, Rolling7Day)
SELECT
s.ProductID,
s.ProductionDate,
(
SELECT SUM(s2.UnitsProduced)
FROM #Sorted s2
WHERE s2.ProductID = s.ProductID
AND s2.RowNum BETWEEN
CASE WHEN s.RowNum - 6 < 1 THEN 1 ELSE s.RowNum - 6 END
AND s.RowNum
)
FROM #Sorted s
WHERE s.RowNum = @Row;
SET @Row += 1;
END;
-- STEP 6: View Result
SELECT * FROM #Out ORDER BY ProductID, ProductionDate;
Find in below screenshot the procedural query with while loop logic took 44 seconds for fetching cumulative sum of 1000 products.
Rewriting the Same Logic Using a Window Function(optimised way)
Now let’s write the same logic, but this time using SQL Server’s built-in window functions — specifically the SUM() OVER clause. Instead of looping row by row, SQL Server can do the heavy lifting internally. You just define the window of rows you want to work with, and SQL takes care of the rest in one pass.
This single query does the same thing our WHILE loop was doing — but in a much faster and more efficient way. Instead of scanning and inserting row by row, it computes the rolling total using a sliding window across the partition of dates for each product.
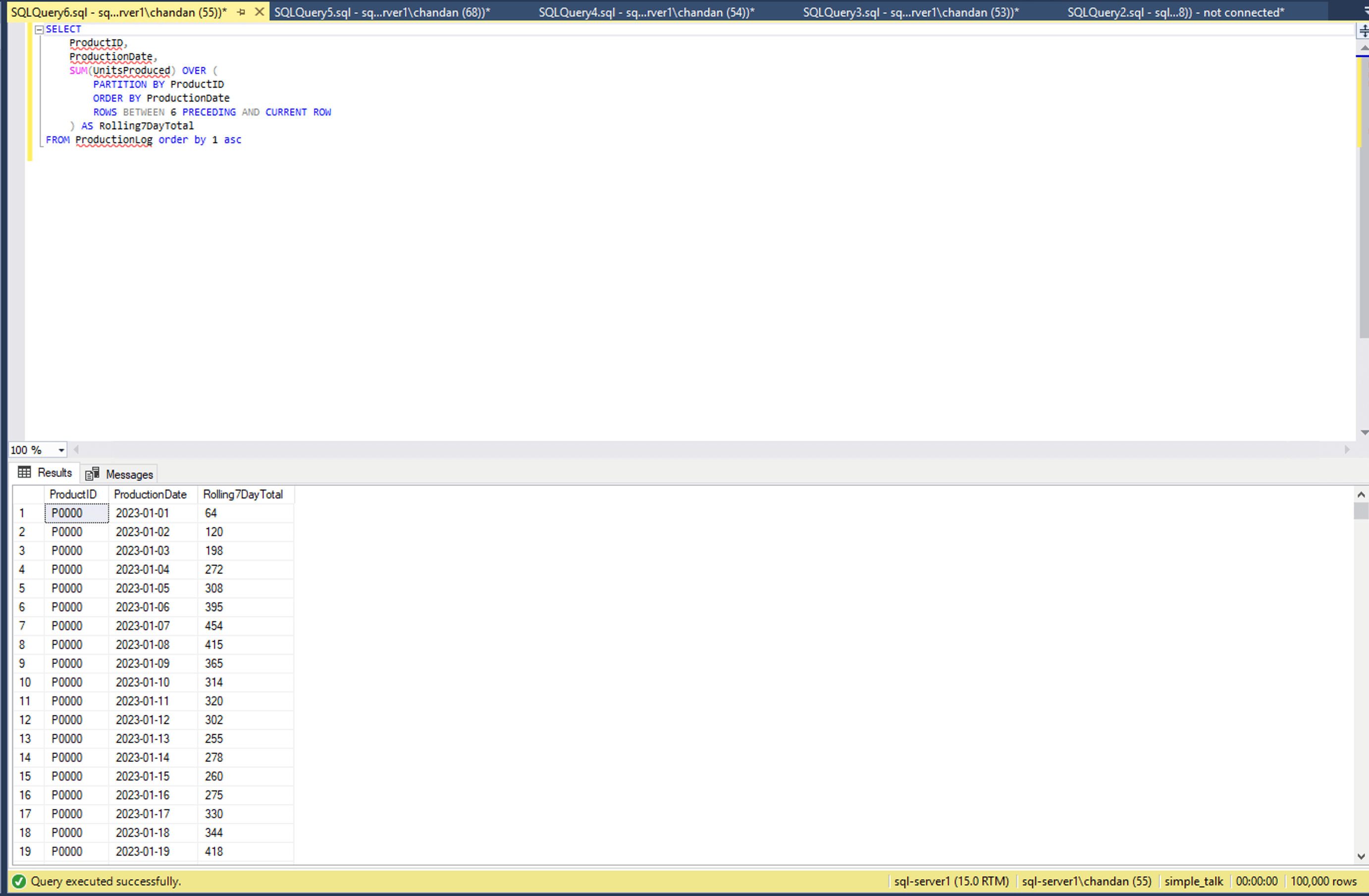
In our test, this query finished in under 1 second, compared to the WHILE loop which took around 25 seconds. And that’s on a relatively small 100000 -row dataset. Imagine the difference when you scale it to millions.
This is the kind of feature SQL Server introduced in version 2012 — but unless someone revisits the old logic, this kind of optimization often goes unused for years.
Here’s how we calculate the 7-day rolling total of units produced, grouped by product and ordered by date:
SELECT ProductID, ProductionDate, SUM(UnitsProduced) OVER ( PARTITION BY ProductID ORDER BY ProductionDate ROWS BETWEEN 6 PRECEDING AND CURRENT ROW ) AS Rolling7DayTotal FROM ProductionLog
By using above window function we were able to reduce time to less than 1 second. Please refer to below screenshot.
Summary
This issue came from a very common pattern: old logic being carried forward without change. The client had upgraded from Microsoft Access and C++ to SQL Server over the years, but the programming mindset never really changed. They simply translated their row-by-row calculations into T-SQL using WHILE loops — which worked fine when data volume was low.
But as the factory scaled — more products, more days, more rows — the same WHILE loop that once worked became a bottleneck. The dashboard froze, performance dropped, and nobody could figure out why, until we traced it down to this outdated logic.
To show how it behaved, we simulated the pattern using 100,000 rows. The WHILE loop version took over 40 seconds to process cumulative sums for all products. When we rewrote it using SQL Server's window functions — something available since 2012 — the same result came back in under a second.
This isn’t about showing off a fancy feature. It’s a reminder that SQL Server can do a lot more if we let it — but only if we occasionally revisit the logic that’s been running quietly for years. What once made sense for a small factory running Access might be holding back a much larger setup today.
Taking time to modernise small pieces of code like this can save a lot of time and pain — not just for performance, but for clarity and maintainability too.
Note: Everything shared here is recreated from my own memory and past experience. There might be slight variations from the original issue — for example, the real table had a large number of columns, and there were also many joins in the procedural logic, adding extra workload on the production SQL Server — while I focused just on a simple simulation which was sufficient to mimic slowness on legacy logic. But the goal was to highlight how these overlooked patterns can still exist in many systems today — especially in setups that have gone through multiple tech upgrades without a full application walkthrough or logic audit. If this reminds even one team to revisit their aging procedures, it’s worth it.
