

There are already search functions available to help one find matches for nearly identical strings, such as Soundex and Levenstein. These existing functions seem like they would be useful, but in real-world situations I've never found them beneficial. After 30 years of frustration importing customer data and dealing with finding and merging possibly duplicate accounts, I decided to solve this fuzzy search problem.
What should a fuzzy search function be able to do? My wish list is that it will handle these equally well:
- transpositions
- dropped letters
- extra letters
- missing prefix or suffix on names
- nicknames
- last name comma first name or vice-versa
Also, I would like the fuzzy search function to be able to match on any strings such as VIN numbers, car make and model and year, or an addressline1 which may have misspelled or missing parts or extra parts or abbreviations. As a bonus, I'd like the function to be powerful enough to return valid matches ranked in the top 20 from a table of a million rows.
How hard would it be to write a fuzzy search function to do all of that? How would you begin to write it? In the past, I've written some custom "slightly" fuzzy searches to parse addresses and normalize them and try to match. I've written some name parsers that implement nickname matching and allowed for missing suffix and prefix parts. These were hefty and functional but still never handled most of my wishlist items. There's got to be an easier way!
The first thing I needed to do was to generate a million names. The U.S. Census Bureau keeps statistics on last names, and first names for both males and females. With their frequency data, I generated a million random names in the proper distribution. Since William, my name, is the fifth most common male name, it shows up very often in the million name file. And even worse, Williams is the third most popular last name so a search on my name will be difficult. The most common name, James or Mary Smith will likely occur many times in the table. The census reports on 1200 common male names, 4300 common female names, and 89000 common last names which I multiplied to one million.
After pondering for days on how to write a function that implements my wish list, I gave up and redefined the problem. What if I just match parts of the search string to parts of the target string and return a higher score for more parts matching? There are 26 letters, 10 digits, and maybe 10 punctuation symbols to deal with. Unfortunately, many of the more common letters may be in thousands of names.
Then I had an insight; what if I search for letter pairs? Wouldn't the chances of letter combinations be much more selective, something like 30 x 30 for every single pair in a name? So that is what I did. It took me about five minutes to write basically a one line function to count letter pair matches.
CREATE FUNCTION dbo.FuzzyMatchString (@s1 varchar(100), @s2 varchar(100))
RETURNS int
AS
BEGIN
-- written by William Talada for SqlServerCentral
DECLARE @i int, @j int;
SET @i = 1;
SET @j = 0;
WHILE @i < LEN(@s1)
BEGIN
IF CHARINDEX(SUBSTRING(@s1,@i,2), @s2) > 0 SET @j=@j+1;
SET @i=@i+1;
END
RETURN @j;
END
GOSimply create the function above in a database where you have names or addresses. Then call it as in the example below:
DECLARE @s1 varchar(100) = 'Billy William Lee Talada Jr.'; SELECT DISTINCT top (50) name, fms.score, SOUNDEX(Name) AS SoundexCode from Names CROSS APPLY (select dbo.FuzzyMatchString(@s1, Name) AS score) AS fms ORDER by fms.score desc ;
Here are the results from searching on my name in a one million name table with comments added in Excel:
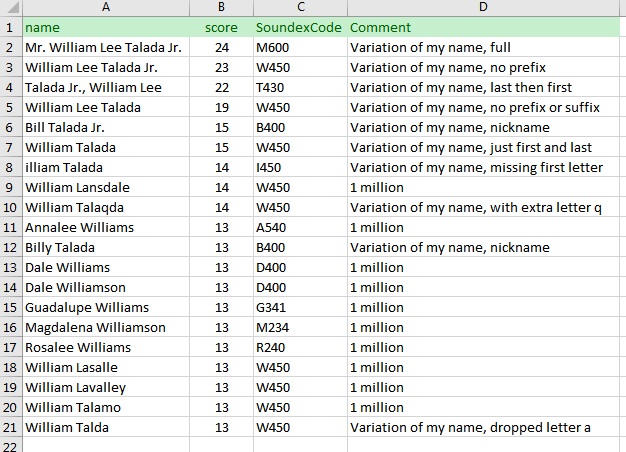
What is most impressive is that this very simple search function handles all my wishlist items and brings my desired rows to the top. Notice that the Soundex function was useless in finding the rows I wanted. It is important to note that the match string you type in is critical to the quality of results you get back. In my case, typing in both my given name and nickname and all other parts, such as Mr. or Jr., really allowed the function to find all variations of how I write my name.
For the past few weeks I've been pondering why such a simple function outperforms commercial functions designed on studies and theories and mathematical models. Then, I realized this function works like our brains. It is basically performing neural network-like matching without entraining any neurons. It has me wondering how many more opportunities there are to be discovered based on this strategy.
My function takes nine seconds to run on my laptop on the one million row table. In reality, you will likely be working with a much smaller data set or can filter the rows by city or something else beforehand to cut down on the processing time. I tried several different optimizations such as unrolling the loop which brought it down to five seconds. Maybe someone can optimize it further.
