

One common question I see from many people new to T-SQL is how to find data in a string and extract it. This is a very common request, as our databases contain many strings. We often find that people using applications embed information in a string, with the expectation that the program will be able to easily remove that information later. In this article, I'll look at how to extract this data using SUBSTRING, CHARINDEX, and PATINDEX.
This is a back to the basics article that I hope will be useful for those developers and DBAs that are new to SQL Server and looking to improve their skills. Feel free to pass this along.
Find the Consistent PO
One example is an invoice number or PO number. I have often seen this data embedded in text fields, with a requirement later to extract this number from the field. This is a common type of data that gets added to a field in a table somewhere, such as in a Customer table. We might have users, or an application, decide to add this data to denormalize our data.
Suppose we have a table that contains information such as this:
CREATE TABLE Customers
( CustomerID INT
, CustomerName VARCHAR(500)
, CustomerNotes VARCHAR(MAX)
, Active TINYINT
);
GO
INSERT dbo.Customers
( CustomerID
, CustomerName
, CustomerNotes
, Active
)
VALUES
( 1, 'Acme Inc', 'Last PO:20154402', 1)
, ( 2, 'Roadrunner Enterprises', 'Last PO:20140322', 1 )
, ( 3, 'Wile E. Coyote and Sons', 'Unreliable payments', 0)If I look at the data, we see that someone has decided to include important information in the notes field. I'm sure that many experienced people will cringe at this use of fields in a table, but this happens more often than many of us would like.
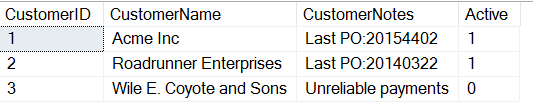
If I now want to get the PO out of this field, perhaps for a report that's needed, or perhaps because I'm going to ETL this data to a more appropriate place, I can use the SUBSTRING function in T-SQL. I use this function when I know where inside of a string I am looking to get data.
In this case, I can see that the first 8 characters of the CustomerNotes field are often "Last PO:". With this, I can start at the 9th character and then get the next 8 characters (length of the PO). I'll use this query.
SELECT CustomerID
, 'PO' = SUBSTRING(CustomerNotes, 9, 8)
FROM dbo.CustomersThis will return the POs, but I get some other data.
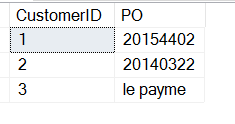
No worries, I can easily filter this out (a discussion for another article).
SELECT CustomerID
, 'PO' = SUBSTRING(CustomerNotes, 9, 8)
FROM dbo.Customers
WHERE customerNotes LIKE '%PO%'
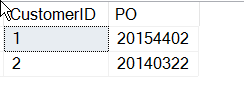
Now, I'm done, right? Well, maybe not.
A Inconsistent PO
In the data I've looked at so far, the PO number is aways in the correct place. However let's suppose that not all of our data entry people work with customers the same way. Here a bit more data to show what I mean:
INSERT dbo.Customers
( CustomerID
, CustomerName
, CustomerNotes
, Active
)
VALUES
( 4, 'Beep Beep Enterprises', 'Remember their slogan: We go fast. Last PO:20154402', 1)
, ( 5, 'Goldberg Supplies', 'Preferred. Last PO:20140322', 1 )
, ( 6, 'Bugs Deliveries', 'Fast Last PO:20145554', 0)Now let's run our script from above. We get this data:
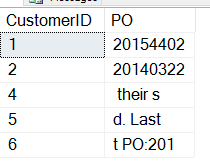
Not quite what we want. The problem here is that the start of the SUBSTRING isn't what we want. We need to start with the location of the PO number, perhaps with the location of "PO:". How can we get that?
We have a couple choices, but enter CHARINDEX and PATINDEX. Both of these allow us to search a string and find another string inside of it. Either can work here, but let me show you how these work on our test data. I'll run this query:
SELECT CustomerID
, CustomerNotes
, 'Charindex_StartPO' = CHARINDEX('PO:', CustomerNotes)
, 'Patindex_StartPO' = PATINDEX('%PO:%', CustomerNotes)
, 'PO' = SUBSTRING(CustomerNotes, 9, 8)
FROM dbo.CustomersAnd get these results:
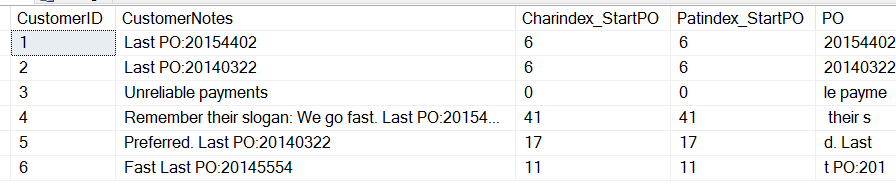
Note that we can see here both functions return the same value, the starting position of the "P" in "PO". There are a few differences. CHARINDEX can start at a certain position in the string while PATINDEX can take wildcards. In this simplistic case, we can use either one.
I will use CHARINDEX here, and alter my query to this:
SELECT CustomerID
, 'PO' = SUBSTRING(CustomerNotes, CHARINDEX('PO:', CustomerNotes), 8)
FROM dbo.Customers
WHERE customerNotes LIKE '%PO%';That gives me this, which isn't what I want.
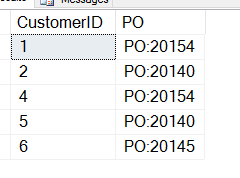
I have forgotten that CHARINDEX gives me the beginning position of the PO, so I must add to this value. Here's a query that works:
SELECT CustomerID
, 'PO' = SUBSTRING(CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3, 8)
FROM dbo.Customers
WHERE customerNotes LIKE '%PO%';Note that I have added 3 to the result of the CHARINDEX function. Here are the results:
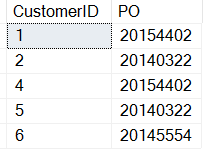
The PO Grows
It seems like this is a good query, but let's imagine we add a bit more data.
Note that in this case, we have purchase orders that have grown in size. Some are 8 characters, and some are 9. Certainly we can just take 9 characters, but we could grow to 10 or more. In addition, we have other notes after the PO in places.
Let's modify our query to see what we can do. I've added a twist to my CHARINDEX.
SELECT CustomerID
, CustomerNotes
, 'Start of PO' = CHARINDEX('PO:', CustomerNotes)+3
, 'End of PO' = CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3)
, 'PO' = SUBSTRING(CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3, 8)
FROM dbo.Customers
WHERE customerNotes LIKE '%PO%';
Here are the results:
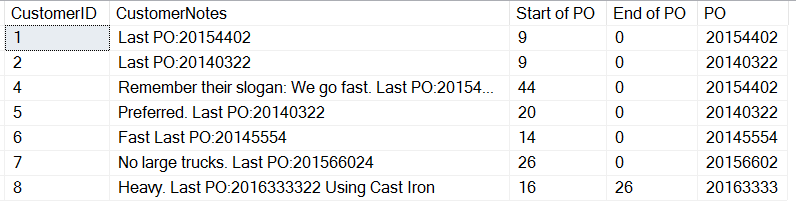
If we look closely, we see that our last entry, with text after the PO gives us a CHARINDEX result. This is because we are searching for a string, we get a 0 if no entry is found. Only customer 8 has a space after the PO. This means we can calculate the length of the PO for the last entry, but what about all the other entries that have a different format?
We can use a CASE statement here, since we have two possibilities here. One CASE will check for a space and return the index of the space inside the string. The other will return the length of the string itself, when no space exists. This gives me code like this:
Update: My math was incorrect. Changed from -3, to -2 in the code below.
SELECT CustomerID
, CustomerNotes
, 'Start of PO' = CHARINDEX('PO:', CustomerNotes)+3
, 'End of PO' = CASE WHEN CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) = 0
THEN LEN(CustomerNotes)
ELSE CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3)
END
, 'Real End of PO' = CASE WHEN CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) = 0
THEN LEN(customernotes)
ELSE CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3)
END - CHARINDEX('PO:', CustomerNotes)
, 'PO' = SUBSTRING(CustomerNotes
, CHARINDEX('PO:', CustomerNotes)+3
, CASE WHEN CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3) = 0
THEN LEN(customernotes)
ELSE CHARINDEX(' ', CustomerNotes, CHARINDEX('PO:', CustomerNotes)+3)
END - CHARINDEX('PO:', CustomerNotes) - 2
)
FROM dbo.Customers
WHERE customerNotes LIKE '%PO%';
If we look at this code, it's very similar to the SUBSTRING code we used before, but now instead of a fixed length, 8, for the number of characters to return, we are returning values with a formula. The formula is essentually the real end of the PO (the 5th column in the result set) and the start of the PO. There is a CASE statement for when we get a zero.
Now if we do the math, we can see how long each PO is. For most POs this is 8 characters (11 characters after the start of the "P" in "PO:"), but 9 characters for customer 7 and 11 for customer 8.
Some of you might wonder about the -3 in the code, but if you remember the rules of arithmatic, I've actually carried through the minus to the quantity representing the beginning of the PO number.
Conclusion
This isn't the end of the possibilities for POs embedded in the a notes field. I could have someting like "test PO: 201530444. New test" and that would cause problems with our code. In fact, there are plenty of other cases I'd have to handle in the real world.
This article came from a few string extraction problems I've had to solve in the real world, and these types of problems do occur. Hopefully I've given you some skills to practice that will help you in your SQL Server string manipulation.
As with any techniques you might learn here, be sure you assess the performance impact. Execute your code against a large set of test data and determine how well this technique may work versus other techniques. I'd recommend you use a tally table to generate data at a scale larger than your production tables.
String manipulations can be computationally expensive in SQL Server, so be sure you understand the impact of your choices before you deploy code to a production system.
