

Would you like to learn a handy little process for extracting, transforming and loading data fields from a free-form source like a web page or word processing document into something structured like a staging table? Maybe you have a public database of some sort that you need information from but can only get it by way of a web page. You could always just have an assistant type it in a spreadsheet but then you have to worry about consistent formatting and all kinds of other evils. A lot of us have been asked from time to time by the company top dog to find a way to gather information on the Internet into a database for some kind of reporting purpose. I want to show you (3) steps for getting information from a free-form source like a web page into a SQL staging table. I will demonstrate the tools needed and the sequence in which it must be done.
Step #1: The Data Source
The data source can be any free-form document like a web page, word processing document or whatever. The key here is that the anatomy of the document needs to be consistent and not change. The only thing that should change is the data field value itself. For example, I created this procedure to get GPS data from web-based truck fleet reports into a Data Warehouse staging table. The reports were generated in HTML and were consistent (for the most part) in terms of margins, font sizes, orientation, field placement and the only thing that changed from report to report was the data field values that I needed.
Step #2: The XML Virtual Printer
You need to get the data into a format that is readable by SQL Server Integration Services (SSIS) and the technique I'm explaining uses XML. Unless the data source will export to XML the easiest way to get your data into XML format is to print it to an XML virtual printer which creates a physical file on your drive. I purchased the XML Printer software created by Archae (www.xmlprinter.com) for a very small fee and found it to be easy to configure. The printer is installed, configured and shared on a print server (your SQL Server will do unless the DBA gives you a hassle) and then you add a new printer from the share on a client computer designated to someone who will be pulling up the data source reports and doing the printing.
One cool thing about the Archae XML printer is that you can tell it to parse the print job and extract only the data fields you need. This saves you from processing a ton of unnecessary data. The parsing is based on a "definition" file that you create using a small application that comes with the paid license of XML Printer called XML Printer Composer. The definition file defines the data fields in the data source print job that the XML Printer parser must find and extract out. This is what my definition file looks like...
<?xml version="1.0" encoding="utf-8"?>
<!-- do not edit this file manualy, use Composer -->
<definition>
<field type="text" id="ArbitraryFieldName1" pos="absolute" anchor="461;605/35" align="left|top" elemsize="0;0" page="1" font-face="Verdana" font-size="7.5" />
<field type="text" id="ArbitraryFieldName2" pos="absolute" anchor="389;939/5" align="left|top" elemsize="0;0" page="1" font-face="Verdana" font-style="bold" font-size="7.5" />
<field type="text" id="ArbitraryFieldName3" pos="absolute" anchor="1475;712/34" align="left|top" elemsize="0;0" page="1" font-face="Verdana" font-size="7.5" />
<field type="text" id="ArbitraryFieldName4" pos="absolute" anchor="1011;611/57" align="left|top" elemsize="0;0" page="1" font-face="Verdana" font-size="7.5" />
</definition>
This is what my parsed print job looks like...
<?xml version="1.0" encoding="utf-8"?>
<data>
<ArbitraryFieldName1> ArbitraryFieldName1Value </ArbitraryFieldName1>
<ArbitraryFieldName2>ArbitraryFieldName2Value</ArbitraryFieldName2>
<ArbitraryFieldName3>ArbitraryFieldName3Value</ArbitraryFieldName3>
<ArbitraryFieldName4> ArbitraryFieldName4Value </ArbitraryFieldName4>
</data>
Finally for this step you might want to consider manually inspecting a number of parsed print jobs before you go on to step (3) for quality control and definition file tweaking purposes.
Step #3: The SSIS Package
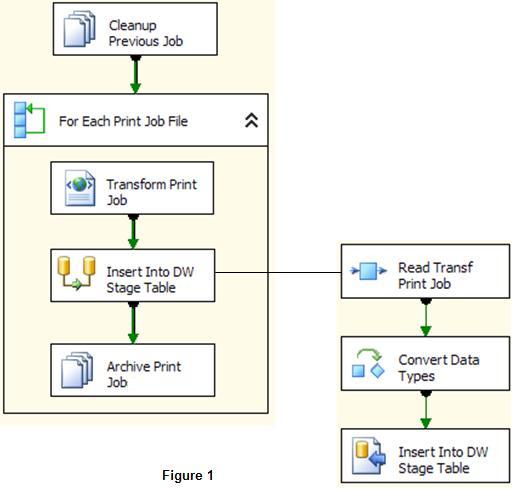
Now we're getting to the fun part. You will need to create an SSIS package that will pick up the files with an XML Control Flow Task in a Foreach Loop Container and for each file transform it and load it into your staging table. Here's the process...
Foreach Loop Container: Nothing fancy here. Use the Foreach File Enumerator and define the Enumerator configuration properties. You also need to create a user variable of type string and configure under Variable Mappings. This variable will store the full path to the parsed XML print job.
XML Control Flow Task: A couple tricky things here. In order for the XML Data Flow Source (used next) to read the XML file correctly you must first transform the parsed XML file and convert each data element into attributes of the <data> element and at the same time add a <table> parent element . This is done using Extensible Stylesheet Language Transformations (XSLT). In the interest of efficient processing, you should create and store the transformed XML in a user variable of type string to be read by the XML Data Flow Source instead of a physical file. This is what my XSLT file looks like...
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:strip-space elements="*"/>
<xsl:output method="xml" indent="yes"/>
<xsl:template match="*">
<xsl:choose>
<xsl:when test="text()[normalize-space(.)]">
<xsl:attribute name="{name()}">
<xsl:value-of select="."/>
</xsl:attribute>
</xsl:when>
<xsl:otherwise>
<Table>
<xsl:copy>
<xsl:copy-of select="@*"/>
<xsl:apply-templates/>
</xsl:copy>
</Table>
</xsl:otherwise>
</xsl:choose>
</xsl:template>
</xsl:stylesheet>
XML Data Flow Task: Before you configure this Task to get the XML data from the user variable you created you need to first point it to a physical parsed print job file and generate an XML Schema Definition (XSD) file to use for each file during runtime. Then after you've created the XSD file you re-configure this task and point it to the user variable. The XSD file defines the specific format that the XML Data Flow Task should expect to see for each print job. This is what my XSD file looks like...
<?xml version="1.0"?>
<xs:schema attributeFormDefault="unqualified" elementFormDefault="qualified" xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="Table">
<xs:complexType>
<xs:sequence>
<xs:element minOccurs="0" name="data">
<xs:complexType>
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="ArbitraryFieldName1" type="xs:string" use="optional" />
<xs:attribute name="ArbitraryFieldName2" type="xs:string" use="optional" />
<xs:attribute name="ArbitraryFieldName3" type="xs:decimal" use="optional" />
<xs:attribute name="ArbitraryFieldName4" type="xs:string" use="optional" />
</xs:extension>
</xs:simpleContent>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
SQL Server Destination: Onward to the SQL Server. You could also use an OLEDB Destination if you loading into different platform. You might also have to perform some Data Conversion (see figure 1) to convert the types before this task will execute. The designer in Visual Studio does a good job at showing type mismatches.
Other: Depending on your auditing and recovery requirements you may also want to setup auditing functionality in your SSIS package. In my case ease of implementation was a priority so I put some simple file tasks into operation (see figure 1) to move each processed print job into another folder after the data flow completed for that file and also a file task to delete that batch of files at the beginning of the next package execution time. This allowed me the window of time between post-processing and the next execution to resolve any discrepancies.
You might also want to consider setting up an OnError Event handler to e-mail you in case of error. For example, if your staging table has a primary key to ensure integrity and your data pipeline contains duplicate records (maybe your assistant accidentally printed the job twice) the job would fail and you would want to know about it. Occasionally I also find that the parser didn't recognize and therefore didn't extract a data field because the anatomy of the data source document exceeded the tolerance level defined for that field in the parser definition file.
There is a lot of power in XML and SQL Server tools to deal with data transfer between heterogeneous systems. I have found this handy little process for extracting, transforming and loading data fields from a free-form source like a web page to be very helpful in a variety of applications. This certainly isn't the only way but I'm confident that if you adapt this to your unique situation you too will succeed.

{kind=link}