

There may come a time when you are not in control of the input file format and it is in a decidedly non-standard format. I recently had to process such a feed file which had a metadata row both at the start and the end of the file. The file could be represented something like this, with only the “x,y,z” records being of importance (along with the column headers if we can get this info).
| Col1 | Col2 | Col3 |
| xxx start | ||
| x | y | z |
| x | y | z |
| x | y | z |
| xxx end |
The existence of a problematic first row is itself not a huge problem, as we can select to omit "n" rows from the start of a flat file when defining the connection manager; It's the last row that causes the problem.
Datawise, the issue is that for the red rows there is only one column: "xxx start" and "xxx end" and no comma separators, while the general data row is defined as "x,y,z".
This is not an easy problem to describe but I tried various keyword combinations on Google to see how others were coping with this issue.
Some people advise using the script task: http://www.sql-server-performance.com/article_print.aspx?id=1056&type=art
Some use the Conditional Split: http://www.sqlis.com/54.aspx
I've also seen packages which call VBscript code to open the text file, read all the lines and then write them back into the text file minus the problematic rows.
All of these are interesting technical solutions, however I decided against them for various reasons:
(1) I didn't want to write any code. I really wanted the package to be as simple as possible, so that it would be easily maintainable for other people who have to support it later on. Also, I have found adding scripts to slow down processes so I generally try to avoid them.
(2) In my case there are dozens of columns (maybe 70 or so), so I wanted the designer to define the column names for me by looking at the text file. The problem with the conditional split is that the column names are all manually defined one-by-one and many substring functions need coding.
(3) Finally I didn't want to use a script outside the package. I don't like deploying anything more than a dtsx file when moving between environments which again would make maintenance more difficult.
In short, my aim was to have the entire process encapsulated in a single package with no calls being made to outside processes, and have it as simple as possible to build and maintain.
So, how to do this? The way I do it now is quite simple (below):
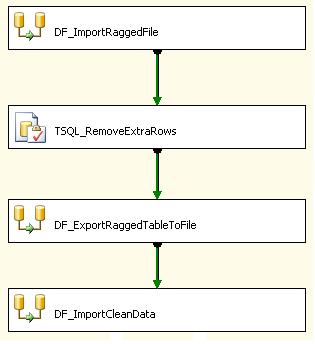
Initially I import the entire file into a single staging table. The Flat File source is defined as "Ragged right" and has one column which is 8000 chars long. The name of this column is meaningless as it is simply a placeholder. This is imported into a staging table which has one column - defined as varchar(8000). This way the entire file is always imported successfully. We now have the table populated with the correct rows and additionally the 2 problem rows.
Next we remove the extra rows. In my case this is a delete statement with a simple where clause as the length of the problem rows is constant and is significantly shorter than that of a normal data row. You'll need some way of distinguish this row(s) from the others and if you're lucky it'll be as simple as my case. If not, you might have to filter using the column delimiters. You might even try to use an identity column on the table and use min and max functions to find the problem rows (actually min + 1 because of the column headings). I didn't try using the identity method, as I'm always concerned (probably needlessly) that the order of inserts might not necessarily be guaranteed to be identical to that of the text file so I prefer to use separate logic. If the source file is generated form another process, the format of the problem lines should be constant so the logic should be straightforward.
Next I export the remaining rows into a temporary file. This is a Flat File defined as "Ragged right", again with one column. The staging table above is the source and data is exported from it to the staging Flat File.
Finally, this staging file is treated as a standard Flat File and imported as per usual in another data flow task. This means that the column names can now be determined from the source file by the designer.
We have added a couple of data-flow tasks which complicates the package a little, but it's all pretty straightforward and transparent. If / when a recordset source can be used, we can do away with the persisted staging Flat File to make it even neater in the future.

