

Introduction
We all have tools in our toolbox. Having different tools and techniques in your toolbox means that you can pick the right tool for the job when you’re confronted with a new task. This article is an exercise in looking at some of the tools available and using several of them to accomplish a task. It also illustrates some techniques for manipulating text file data that aren’t immediately intuitive.
This article and solution use the following tools.
- DOS batch files
- Ultra Compare by IDM Solutions
- SQL Server 2008 Standard Edition
Problem
A while back my boss asked me to compare directories on two identical web servers to make sure the folders and files really were identical. The following criteria would qualify a file or directory as being different:
- The file or directory is missing from one server
- The date stamp is different
- The size is different
There were several things I had to consider in determining how to go about the task:
- The approach had to work against the live web servers while they were online, so intense CPU operations were something to be avoided.
- Because the web servers are online, I need to run the comparison off-hours, so automation is important.
- We had some tools available, but I couldn’t spend money on new ones. We had a tool called Ultra Compare, which could run in command line mode and perform the comparison I was looking to do.
- The web servers are in the DMZ and the SQL Servers are inside the domain. The SQL Server process could not access the file system on the web servers directly.
Approach
Batch files are efficient at file system operations, Ultra Compare is efficient at performing the file system comparison and SQL Server excels at manipulating data. After a brief proof of concept, I decided on the following approach:
- Use a batch file to process the comparison.
- Call Ultra Compare to perform the comparison itself, processing each web root individually and write the output into individual text files.
- Concatenate the output files into a single file for delivery to the database.
- Clean up the individual output files.
- Use SQL Server to manipulate the data and produce the report.
- Import the single file into a staging table.
- Manipulate and clean the data.
- Populate the data into a single reporting table.
NOTE: Our web servers have internal IP addresses with 55 and 57 in the fourth octet. Throughout this article and scripts, I refer to them by these numbers. You could refer to your servers as A and B, X and Y, 1 and 2 or whatever else makes sense to you to keep them separate. In this article, I’ve changed the IP addresses, servers, shares and sites in the interest of security.
Using Ultra Compare to Compare Files
I chose Ultra Compare to perform the comparison because it did what I needed to do, it had a command line mode and we already owned it. It supports quite a few command line switches and the following command is the one that’ll compare the files in two directories and write the results to an output file.
uc -r -dmb -vert -ne \\172.16.123.55\publicsites$\myxdrive.com \\172.16.123.57\publicsites$\myxdrive.com -o z:\temp\test_comp.txt
Here’s what the different parts of the command mean:
-r specifies to search recursively; include subdirectories
-dmb sets the folder compare to basic (presence, time and size)
-vert sets the output to vertical
-ne specifies to show differences in the output
\\172.16.123.55\publicsites$\myxdrive.com is the first folder to compare
\\172.16.123.57\publicsites$\myxdrive.com is the second folder to compare
-o z:\temp\test_comp.txt defines the output file
Let’s take a peek at the output file it produces.

The output of the comparison is formatted for reading in DOS. The first two rows specify what directories are being compared. Then come some header rows, detail rows and finally a footer row. It isn’t the friendliest format in the world for importing into a database, but many of us have had situations like this before and it’s workable. We’ll deal with parsing the file once we get it loaded into the database.
Performing the Comparison
I needed to keep each comparison isolated to its own text file because I needed the headers in place to denote the directories compared. This also allows me to process a single directory during development. The list is never static, so a simple loop in DOS would do the trick. Here’s the code to accomplish this:
:Initialization
set strServer55=\\172.16.123.55\publicsites$
set strServer57=\\172.16.123.57\publicsites$
set strOutput=Z:\Temp
:PerformDirectoryComparison
echo Folder Comparison Started
for /f %%g in ('dir %strServer55% /ad /b ^| findstr /v dir_to_exclude') do (
<nul (set /p x= Processing %%g...)
uc -r -dmb -vert -ne "%strServer55%\%%g" "%strServer57%\%%g" -o "%strOutput%\%%g.uc.txt"
echo Done
)
echo Folder Comparison Completed
The for /f performs everything in the do loop for each item returned by the dir command. The %%g variable is the index of our loop.
The dir command returns a bare listing of directories, but skips the “dir_to_exclude” folder completely. You don’t have to include the findstr command at all if you don’t have a directory to exclude.
The <nul command is a way of displaying progress while executing a batch file. It displays the text but doesn’t output a line break like the echo command does.
The uc command invokes Ultra Compare to compare the current directory on each server.
The echo command outputs the word “done” and adds a line break afterwards
The <nul and echo commands are solely for aesthetics and aren’t necessary unless you want feedback as you’re developing and running your script.
Preparing the Comparison Result for SQL Server
Once all the output files are created, I needed to move them into SQL Server for analysis. The easiest way to do this is to consolidate the individual files into a single file to copy to the server and import into a database.
The deletion step ensures that I’m starting with an empty file and not one I created in a previous run. Then a DOS loop will concatenate the output files into one.
:ConsolidateFiles
echo Post-Comparision Started
<nul (set /p x= Deleting Consolidated File...)
if exist "%strOutput%\web_compare.txt" del "%strOutput%\web_compare.txt" /f /q
echo Done
<nul (set /p x= Consolidating Comparison Files...)
for /f %%g in ('dir %strOutput%\*.uc.txt /a-d /b') do (
type "%strOutput%\%%g" >> "%strOutput%\web_compare.txt"
)
echo Done
Cleaning Up
One thing that irritates me to no end is a process that runs and leaves a lot of shrapnel behind by not cleaning up after itself. Well, this little batch file created one output file for each directory plus one consolidated file. The individual ones are no longer needed, so they need to be deleted. Using the same naming convention I used in creating the output, they can be deleted en mass.
:CleanUp
<nul (set /p x= Deleting Comparison Files...)
del "%strOutput%\*.uc.txt" > nul
echo Done
The final step is to copy the single comparison file over to the SQL Server for analysis.
<nul (set /p x= Copying to SQL Server for Processing...)
copy "%strOutput%\web_compare.txt" "\\mysqlserver\myshare$\temp\web_compare.txt" /y > nul
echo Done
The batch file is now done. The only file I’ve left on the web server is the consolidated output file with the all differences, so the web server is not accumulating a bunch of junk it doesn’t need. Once the process in in production, I can delete the consolidated file after I copy it to the SQL Server.
Importing the Output File
Let’s take another look at our output file format.

There are multiple blocks like this, one for each directory. The first two rows are the folders that were compared and the rest of the file is broken into columns. Given the format, I’m going to import into a single column in the staging table and perform the parsing later. Note that an identity column and columns to hold the paths are being created now, but they won’t be populated during the initial load.
IF OBJECT_ID('dbo.IncomingCompare', 'u') IS NOT NULL DROP TABLE dbo.IncomingCompare;
CREATE TABLE dbo.IncomingCompare (
RawLine Varchar(8000),
ID Integer not null identity (1, 1),
constraint IncomingCompare_PK primary key (ID),
ParentPath55 Varchar(8000),
ParentPath57 Varchar(8000));The import of the file into our staging table is simple, with just one bulk insert statement.
BULK INSERT dbo.IncomingCompare
FROM 'D:\temp\web_compare.txt'
WITH (DATAFILETYPE = 'char',
FORMATFILE = 'D:\temp\LoadPathComparison.xml',
FIRSTROW = 1,
MAXERRORS = 0);Here’s the very simple format file:
<?xml version="1.0"?>
<BCPFORMAT xmlns="http://schemas.microsoft.com/sqlserver/2004/bulkload/format" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<RECORD>
<FIELD ID="1" xsi:type="CharTerm" TERMINATOR="\r\n" MAX_LENGTH="8000" COLLATION="SQL_Latin1_General_CP1_CI_AS" /> <!--the whole row-->
</RECORD>
<ROW>
<COLUMN SOURCE="1" NAME="RawLine" xsi:type="SQLVARYCHAR" />
</ROW>
</BCPFORMAT>Now that the data is imported into the staging table, here’s what the table looks like.
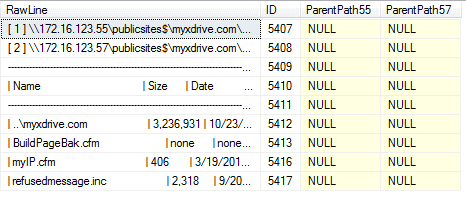
Parsing the Data
Here’s where the challenging and fun part (at least for me, but I like this stuff ;-)) begins. I need to get the staging table columns populated with the parent paths and clean out the junk rows that aren’t needed. There are several different steps here, so we’ll tackle them one by one.
Parent Paths
The first step is to populate the ParentPath55 column, which is the path on the first server being compared. Take a look at the first two rows in the staging table above. The first row of each block of rows is the one that needs to be populated into the ParentPath55 column. The SQL is simple enough. I know this is a non-SARGable predicate, but I found the performance to be similar to using the LIKE operator and I don’t have to deal with the regular expression syntax.
UPDATE dbo.IncomingCompare SET ParentPath55 = RawLine WHERE SUBSTRING(RawLine, 1, 5) = '[ 1 ]';
Our staging table now looks like this:
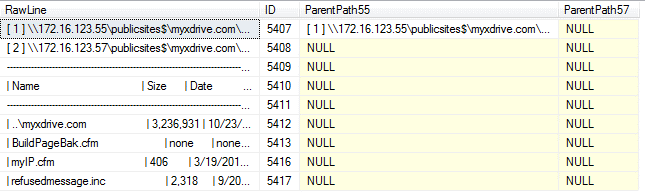
The next step is to populate the ParentPath57 column in the same row where we just set ParentPath55. The value will come from the RawLine column in the row following the ParentPath55 row we populated. Not wanting to fall into the temptation to loop unnecessarily, I’ll employ a set-based solution by joining the table to itself based on the primary key. Put another way, for each ParentPath55 row, I’ll update the ParentPath57 column with the value from the row immediately following it.
WITH cteParents AS (
SELECT p1.id, p2.RawLine Path57
FROM dbo.IncomingCompare p1
INNER JOIN dbo.IncomingCompare p2 ON p1.ID + 1 = p2.ID
WHERE p1.ParentPath55 IS NOT NULL
)
UPDATE dbo.IncomingCompare
SET ParentPath57 = p.Path57
FROM cteParents p
WHERE dbo.IncomingCompare.ID = p.ID;Here’s our staging table now:
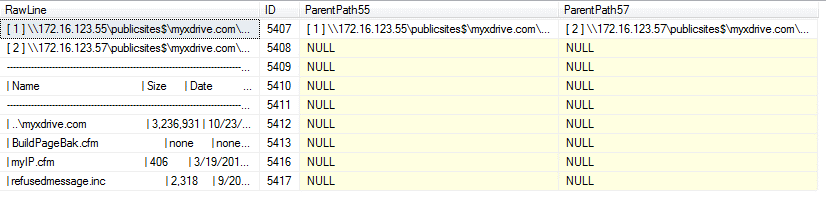
We now have a situation where the ParentPath55 and ParentPath57 columns are populated for the first row starting the set of rows for each root directory. The detail rows are the ones I really need, but they’re not populated yet. I’ll employ a quirky update (also known as a three-part update; see http://www.sqlservercentral.com/articles/T-SQL/68467/ for more information) to populate the parent path columns with the first populated row in each block. This again avoids the temptation to employ a loop and is nasty fast. Remember we’re on SQL Server 2008, so we don’t get to use the LEAD and LAG window functions.
DECLARE @PreviousGroup55 Varchar(8000) = '',
@PreviousGroup57 Varchar(8000) = '';
UPDATE dbo.IncomingCompare
SET @PreviousGroup55 = ParentPath55 = CASE WHEN ParentPath55 IS NULL THEN @PreviousGroup55 ELSE ParentPath55 END,
@PreviousGroup57 = ParentPath57 = CASE WHEN ParentPath57 IS NULL THEN @PreviousGroup57 ELSE ParentPath57 END
FROM dbo.IncomingCompare
WITH (INDEX (0), TABLOCK)
OPTION (MAXDOP 1);The path columns in the staging table are now filled in for every row.
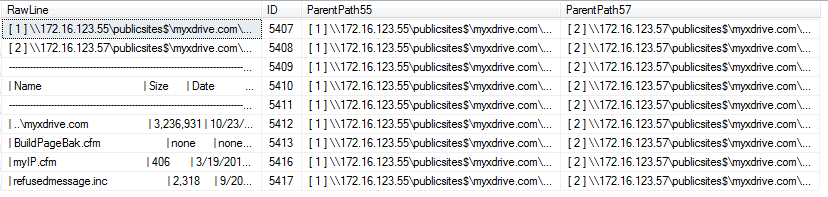
Deleting Unwanted Rows
Finally, I have a columnar data set I can work with. The only thing left is to clean out the unneeded rows. The empty lines, the header separators and the lines denoting the parent paths aren’t needed, so a single update statement will handle everything. Yes, there are non-SARGable predicates in here, but the same situation applies to the SUBSTRING as before and the NULLIF handles the NULLs and empty values. We could accomplish the same thing with multiple update statements, but that proved to take longer than this single update.
DELETE FROM dbo.IncomingCompare
WHERE NULLIF(RawLine, '') IS NULL
OR RawLine LIKE '-----%'
OR RawLine LIKE '| Name%'
OR SUBSTRING(RawLine, 1, 5) IN ('[ 1 ]', '[ 2 ]');Building a Permanent Table
Next, we have to build and populate a permanent table. Note that a column to store the file type is included in the table. I won’t populate it initially, but instead do it later.
IF OBJECT_ID('dbo.SiteDiffs', 'u') IS NOT NULL DROP TABLE dbo.SiteDiffs;
CREATE TABLE dbo.SiteDiffs (
Path55 Varchar(255),
Path57 Varchar(255),
FileType Varchar(32),
FileName55 Varchar(255),
FileSize55 Bigint,
FileDate55 Datetime,
FileName57 Varchar(255),
FileSize57 Bigint,
FileDate57 Datetime);Using a divide and conquer approach, I’ll use everyone’s reliable friend DelimitedSplit8K (see Jeff Moden’s “Tally OH!” article at http://www.sqlservercentral.com/articles/Tally+Table/72993/ for more information) to split up the single column and a crosstab query to break the data into columns. I’ll then trim off the leading and trailing spaces that were brought in from the comparison. Finally, I’ll clean the data in the columns a bit more and convert them to our proper data types. When a file or directory is on one server but not the other, Ultra Compare populates the word “none” for the date stamp and size. As I know of no way to convert the word “none” into either a Datetime or an Integer, I’ll NULL out those values.
WITH cteSplit AS (
--use a crosstab query to separate our split items into columns
SELECT ic.ParentPath55, ic.ParentPath57, ic.RawLine,
MAX(CASE WHEN s.ItemNumber = 2 THEN s.Item END) FileName55,
MAX(CASE WHEN s.ItemNumber = 3 THEN s.Item END) FileSize55,
MAX(CASE WHEN s.ItemNumber = 4 THEN s.Item END) FileDate55,
MAX(CASE WHEN s.ItemNumber = 5 THEN s.Item END) FileName57,
MAX(CASE WHEN s.ItemNumber = 6 THEN s.Item END) FileSize57,
MAX(CASE WHEN s.ItemNumber = 7 THEN s.Item END) FileDate57
FROM dbo.IncomingCompare ic
CROSS APPLY dbo.DelimitedSplit8K(ic.RawLine, '|') s
GROUP BY ic.ParentPath55, ic.ParentPath57, ic.RawLine
),
cteTrimmed AS (
--everything we brought in has lots of padding on both ends, so we'll eliminate it
SELECT Path55 = LTRIM(REPLACE(t.Path55, '[ 1 ]', '')),
Path57 = LTRIM(REPLACE(t.Path57, '[ 2 ]', '')),
FileName55 = LTRIM(RTRIM(FileName55)),
FileSize55 = LTRIM(RTRIM(FileSize55)),
FileDate55 = LTRIM(RTRIM(FileDate55)),
FileName57 = LTRIM(RTRIM(FileName57)),
FileSize57 = LTRIM(RTRIM(FileSize57)),
FileDate57 = LTRIM(RTRIM(FileDate57))
FROM cteSplit
),
cteCleaned AS (
--clean our results and explicitly convert our values. we have to allow for the word "none" in
--the size and date columns, as that's what ultra compare populates when the matching file or
--directory isn't on the other server.
SELECT Path55 = LTRIM(REPLACE(t.Path55, '[ 1 ]', '')),
Path57 = LTRIM(REPLACE(t.Path57, '[ 2 ]', '')),
t.FileName55,
FileSize55 = CONVERT(Bigint, NULLIF(REPLACE(t.FileSize55, ',', ''), 'none')),
FileDate55 = CONVERT(Datetime, NULLIF(t.FileDate55, 'none')),
t.FileName57,
FileSize57 = CONVERT(Bigint, NULLIF(REPLACE(t.FileSize57, ',', ''), 'none')),
FileDate57 = CONVERT(Datetime, NULLIF(t.FileDate57, 'none'))
FROM cteTrimmed t
)
INSERT INTO dbo.SiteDiffs(Path55, Path57, Filename55, FileSize55, FileDate55, Filename57, FileSize57, FileDate57)
SELECT c.Path55, c.Path57, c.FileName55, c.FileSize55, c.FileDate55, c.FileName57, c.FileSize57, c.FileDate57
FROM cteCleaned c;The Path55 and Path57 columns still have the date stamp in the column, which I don’t really need. Getting rid of it is as simple as this.
UPDATE dbo.SiteDiffs
SET Path55 = SUBSTRING(Path55, 1, CHARINDEX(' ', Path55)),
Path57 = SUBSTRING(Path57, 1, CHARINDEX(' ', Path57));Yes, this could have been done in when the table was populated, but I chose to break it out into a separate step. If, for some reason, the boss wants to see it along with the root path, the value can be left there or split into separate columns before being cleared out.
The permanent table is getting there. Here’s what it looks like now.

File Type
Note that I didn’t populate file type at all in the permanent table. I could accomplish this by using a LIKE operator and a cross apply with a massive list of values, but since I’m going to be using this again and it’s probably going to grow, it makes sense to create a physical table with the mask to match and then use our cross apply against the table. This is, by no means, an exhaustive list, but it covers many of the file types we use. Yes, the leading % (wildcard) character means that the query will not be able to use an index in subsequent updates, but it’s the cleanest way I know of to match different conditions and determine the file type based on the name.
IF OBJECT_ID('dbo.FileTypes', 'u') IS NOT NULL DROP TABLE dbo.FileTypes;
CREATE TABLE dbo.FileTypes (
Match Varchar(16) not null,
Description Varchar(64) not null);
INSERT INTO dbo.FileTypes(Match, Description)
VALUES('..%', 'Directory'),
('%.aspx', '.NET Page'),
('%.ascx', '.NET Web Control'),
('%.asmx', '.NET Web Service'),
('%.aspx.vb', '.NET VB Page'),
('%.aspx.cs', '.NET C# Page'),
('%.vb', '.NET VB Class'),
('%.cs', '.NET C# Class'),
('%.asp', 'Classic ASP Page'),
('%.compiled', '.NET Precompiled Site'),
('web.config', 'ASP.NET Site Configuration'),
('app.config', 'ASP.NET Application Configuration'),
('machine.config', 'ASP.NET Machine Configuration'),
('%.cfm', 'ColdFusion Markup'),
('%.cfc', 'ColdFusion Component'),
('%.cgi', 'CGI Script'),
('%.inc', 'ColdFusion Include'),
('%.dll', 'Dynamic Link Library'),
('%.xml', 'XML File'),
('%.txt', 'Text File'),
('%.csv', 'Text File'),
('%.jpg', 'Image'),
('%.jpeg', 'Image'),
('%.png', 'Image'),
('%.gif', 'Image'),
('%.htm%', 'HTML'),
('%.css', 'CSS'),
('%.js', 'Javascript'),
('%.php', 'PHP File'),
('%.mp3', 'MP3 Audio'),
('%.wav', 'Wave Audio'),
('%.doc', 'Word Document'),
('%.docx', 'Word Document'),
('%.xls', 'Excel File'),
('%.xlsx', 'Excel File'),
('%.ppt', 'PowerPoint Presentation'),
('%.pptx', 'PowerPoint Presentation'),
('%.zip', 'Zip File'),
('%.pdf', 'PDF File');Now that the list is created, I’ll use it to set the file type based on the filename on 55. Where it’s missing, I’ll use the filename on 57 in a separate pass. Where it still isn’t covered, I’ll just set the type to “Uncategorized” and let the individual application owners figure it out. Because the list is in a table, anything I missed when I created the list (and there will be some) can simply be added to the table and won’t require any code updates to set the file type properly.
--set the file type for each row using the filename on 55
UPDATE sd
SET FileType = ft.Description
FROM dbo.SiteDiffs sd
CROSS APPLY dbo.FileTypes ft
WHERE sd.FileName55 LIKE ft.Match;
--where the file type isn't set, apply the same rule using the filename on 57
UPDATE sd
SET FileType = ft.Description
FROM dbo.SiteDiffs sd
CROSS APPLY dbo.FileTypes ft
WHERE sd.FileName57 LIKE ft.Match
AND sd.FileType IS NULL;
--where the file type still isn't set, we're going to set it to uncategorized
UPDATE dbo.SiteDiffs
SET FileType = 'Uncategorized'
WHERE FileType IS NULL;Our permanent table is now complete. Here’s what it looks like:

Other Data Rules
I now have a single, denormalized table with all the differences. If there’s more work to do in defining what gets taken out of the set, they can be deleted as appropriate. For example, if you don’t care about images and backup files, those rows can be deleted by using the FileType column. If you don’t want to see any difference more than two years old, they can be deleted by using one of the date columns.
If new rules are defined, we can rebuild the data with the new rules without performing a new comparison of the file system; we can simply reload our text file. Remember, the last one is still on the SQL Server and the web server.
Reporting
Where we go from here depends on our reporting requirements. If the boss just wants an Excel file with all the differences, we can run a query, copy/paste and deliver it. If he wants a web page with filters and grids, we can normalize the data into an efficient reporting table structure, index it appropriately, write a simple web page and let people use it to their heart’s content.
An obvious summary query answers the question of what file types are mismatched most often. We can see a summary of our mismatched file counts by type by a simple query:
SELECT FileType, COUNT(*) FROM dbo.SiteDiffs GROUP BY FileType ORDER BY COUNT(*) DESC;
Another easy one is what frequently-used extensions we don’t have covered in our table of file types. Those can be queried like this:
WITH cteExtensions AS (
SELECT s.item
FROM dbo.SiteDiffs sd
CROSS APPLY dbo.DelimitedSplit8K(REVERSE(sd.FileName55), '.') s
WHERE s.ItemNumber = 1
AND NOT sd.FileType = 'Directory'
)
SELECT e.item, COUNT(e.item)
FROM cteExtensions e
GROUP BY e.Item
ORDER BY COUNT(e.item) desc;Expansion and Adaptability
There are many ways to customize this process to suit your own particular needs. What you do depends on your exact situation. This was written to solve a specific problem, but the techniques could be used to solve other unique situations.
Ultra Compare
Many individual steps in this process could be changed to suit your particular situation. For example, if you don’t have Ultra Compare and you can’t get approval to buy it, you could use your tool of choice. You’d have to change the process to parse the incoming text, but it could be done.
Personally, Ultra Edit is my text editor of choice and I think Ultra Compare does a fine job of comparing files and folders. It isn’t free, but is relatively inexpensive. I’ve used it for years and find it to be well worth the money, but we all have our favorite tools. For information on Ultra Edit or Ultra Compare, see the Ultra Edit site at http://www.ultraedit.com/.
Other Scenarios and Next Steps
If the requirement is that this process is run weekly and a new data set populated to our reporting page, we could schedule the batch file as a scheduled task in the operating system, convert the SQL into a procedure and create a database job to run the procedure. The only requirements are that the batch file runs from a machine that has Ultra Compare installed and also has visibility to the file systems of the both the web servers and the SQL Server.
If you have to run the process regularly and the SQL Server can see the file system on the web servers, you could have the stored procedure do all the work. It could run the batch file using xp_cmdshell and then process the results. The only requirements are that Ultra Compare is installed on the SQL Server and the web server file system visibility exists. Personally, I don’t like installing software on my SQL Servers, but that’s just my preference. I’d rather run it elsewhere.
Where you go from here with this ends with the most famous answer of all: It depends.
