

To delete duplicate rows in Sql server is one of the tedious tasks. Duplicate
rows might exist in a table because of bad database design or because
constraints are not applied. Unlike Oracle where we get unique row-id for each
row and using that we can delete duplicate records, there is no simple way to
delete duplicate records in Sql Server.
One method used to delete duplicate records is to write a stored procedure,
use cursor in that and delete row one by one. There is another simple
interactive way to delete duplicate rows in Sql Server without using stored
procedures and cursor.
I will use Enterprise manager for explanation but scripts can be used if
duplicate records are to be deleted on regular basis from some table. Create one
table OrderDetail with columns ShipmentId, OrderId, ArticleId and Quantity where
ShipmentId, OrderId and ArticleId fields should be unique.
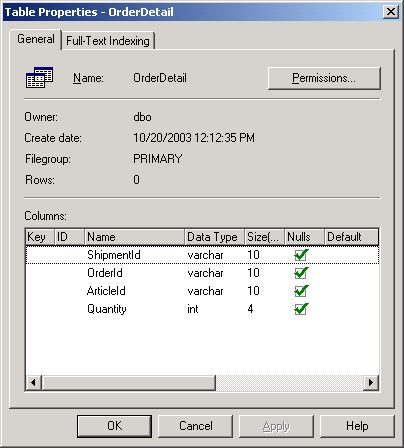
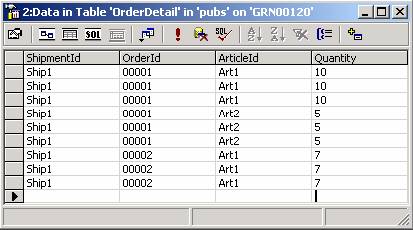
Add few duplicate records into this table.
Create a blank copy of table using:
Select * into OrderDetailCopy from OrderDetail where 1 = 0
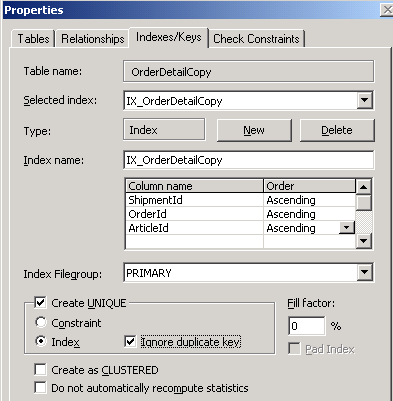
Create Unique index on columns ShipmentId, OrderId and ArticleId. Also check
Ignore duplicate key checkbox. Save the table.
Copy the records from OrderDetail into OrderDetailCopy using:
insert into OrderDetailCopy Select * from OrderDetail
You will get warning message: Server: Msg 3604, Level 16, State 1, Line 1 Duplicate key was ignored.
Now you have OrderDetailCopy table without any duplicate rows.
Drop table OrderDetail using
Drop table OrderDetail
Rename table OrderDetailCopy to OrderDetail using
Sp_rename 'OrderDetailCopy','OrderDetail'
