

This article covers a wide variety of areas concerned with data migration. Primarily, it focuses on process, standards and some of the many issues to consider when undertaking this role.
Example Scenario
Throughout this article I will mention an example data migration project with the following characteristics. The system is a complete re-write of existing client server applications to a single integrated data model spanning 3 core systems. The system is intranet/internet based using VB 6, Active Directory Services (Win2k AS), SS2k EE, XML, DTS, IIS 5, COM+.
System Summary
Source Name | Tables
| Summary
|
NEWSYS | 286 | New corporate data model |
|
|
|
APP_A | 60 | Application A to be migrated to NEWSYS 1:1 mapping with some system code changes (remapping) and data merging with other applications. |
APP_B | 80 | Application B to be migrated to NEWSYS 60% of all tables require complete remapping and merging 40% of tables need to merge with APP_A data (ie. shared data needs to be merged together to form a unified source of data). |
Other | 90 | Reference Data from APP_A, APP_B, spreadsheets. |
|
|
|
Overall Team Dynamics
1 x Project Manager
1 x DBA
2 x Systems/Business Analysts
(representing APP_A, APP_D and APP_B)
6 x Programmers
1 x Application Architect
Migration Team (made up of people from above list)
1 x DBA
2 x Systems/Business Analysts
2 x Programmers
Broad Summary - Drill Down on Migration and Processes
The following summary does not include the initial planning phases and standard definitions; this is discussed later in the article.
![]()


![]()


Development of data cleansing scripts and other data migration routines, focusing on reference data first and if the resources are available, working on other scripts in parallel. Discuss with DBA indexing strategies for staging databases, rules for data cleaning if more than one “group” of programmers require the same data sets.
![]()


Data cleansing routines run, typically only once. Reports developed and communication managed between business owners and analyst to resolve issues as required. All documented in detail and decision processes tracked.
![]()


Migration begins - primary and foreign keys are always enabled (typically via T-SQL). Concurrency issues discussed and planned for with migrations teams. Migration “may” occur in multiple (and identical) MIG_NEWSYS databases if 1 migration team has different requirements to another in terms of performance and time to load. Even so, the DBA must have strict control of common reference data, schema configuration to ensure no issues arise when the teams meet to on common grounds.
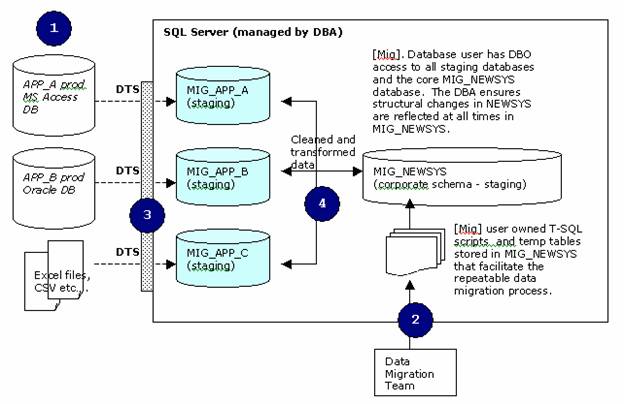
General Definitions
NEWSYS is the name of our new application database.
MIG_NEWSYS is our dedicated migration database for the app.
<sub-app> represents an applications database to be merged.
Migration Team & Responsibilities
Data Migration Role
| Data Migration Responsibilies
|
Business Owners (users) | Data cleansing. Migration testing. Data mapping and migration business rule approval. Final approval and signoff Sourcing and management of additional staff to assist migration data cleansing. |
Analyst(s) | Data model. Adherence and champion to migration standards. Mapping of data from source to destination systems. Requirements Analysis and ongoing user liaison. Inter-system mapping and merging of data documentation, management and liaison. Supply migration team with all associated documentation to complete/change migration scripts and associated reporting. Reports to users in all cases with migration progress. Liase with project managers. |
Database Administrator | Physical data model schema ownership. Migration document QA and naming standard checks. Ownership of all staging databases and final “migration” databases (schema image of corporate data model). Communicate schema changes to all key analysts and programmers and get approval before any change is made. Own the database security model. Ongoing standard DBA tasks. |
Application Architect | Architecture and methodology Common libraries Configuration Management Standards and QA (not so much migration) Technical Support/Special Projects |
Senior Application Programmer | Allocation of programming tasks to programmers. Provide high level of technical expertise and assistance to programmers. Ensure adherence to architecture and programming standards. Code walkthrough’s. Verifies all data merging tasks. Verifies all migration reports send to end-users via Analysts. Liase closely with analysts with migration tasks, reporting, impact analysis. |
Programmer | Develops all migration code based on documentation allocated my senior programmer. |
End User Management (CRITICAL SUCCESS FACTOR)
It is very important that the business owners actually do “own” the data and the associated application redevelopment, and I mean this actually does extend from the steering committee and executive meetings out into user land and is not something born from your imagination. In them doing so, it is important that you provide your clients with effective reporting mechanisms throughout the data migration effort. You must be consistent and firm, as a slip up in a row count from one month’s data cleansing/migration effort to another can result in a flurry of sarcastic emails and calls from your managers. The client will invest a significant about of their time with cleansing and merging of data, and therefore, will require ongoing statistical reports on their progress, and possible views into your system for the more advanced user to check up on data merging results.
Reference Data (CRITICAL SUCCESS FACTOR)
It is not unusual to find that over one third of all tables are reference data tables. It is very important to get this right early in the migration, as all systems will depend on it. It is not uncommon for programmers to embed specific lookups (ie. to address type, relationship type columns for example) in their code, and as such, changing it 4 to 6+ weeks into the project will not be pleasurable experience for you and the programming staff. Even so, strictly speaking the impact should be measurable so long as well managed programming standards are employed.
Reference data will be sourced from:
a) external data files
b) incoming staging databases (ie. one system has the definitive set of data)
c) one off hard coded inserts/updates in t-sql code
The standards section of this paper will discuss naming conventions, but where possible keep t-sql routines that manipulate reference data to a minimum. Look as using a series of generic scripts that allows you to quickly reload all reference data at any time. For example:
sp_msforeachtable "ALTER TABLE ? NOCHECK CONSTRAINT all" sp_msforeachtable "ALTER TABLE ? DISABLE TRIGGER all"
exec MIG_REFDATA_LoadAll_sp
sp_msforeachtable "ALTER TABLE ? CHECK CONSTRAINT all" sp_msforeachtable "ALTER TABLE ? ENABLE TRIGGER all"
Use the following DBCC command for validating foreign keys after each re-load.
DBCC CHECKCONSTRAINTS WITH ALL_CONSTRAINTS
As a final note, take careful consideration of reference data that changes regularly to meeting external (and possibly internal) reporting requirements. You need to decide how the mapping strategy with work, namely:
a) will the table cater for the versioning of reference data?
b) will the table cater for the enabling/disabling of reference data items?
c) will all reference data remapping take place via views or within the application ?
d) does your scheme for reference data versioning apply to all applications using it?
Migration Step 0 – Define Standards and Process
The DBA should clearly define the standards to be used for all objects created in the MIG_NEWSYS database. I have successfully used the following:
[MIG] database user
All migration “users” will be connecting as the [MIG] user. This user has DBO access to the MIG_NEWSYS database and all associated MIG_<sub-app> databases. Why?
- simple to move scripts between servers and DB’s as required
- simple to identify migration scripts over other users
- easier to maintain security and control over mig users
- do not have to give SA access or other higher privs
- can quickly revoke access without any impact
Database do’s and don’ts for the MIG user:
- Don’t – create any objects in the MIG_<sub-app> (staging databases) or remote databases.
- Do – always login as the MIG user
- Do – always follow the standards listed below
- Do – manage your own script change control (including t-sql stored procedures, UDF’s, views, tables).
- Don’t – remove data on shared tables
- Don’t – edit stored t-sql code without adding comments as to the purpose of the change.
- Do – carefully document your changes to all migration code
- Do – complete code headers and dependency maps
File System Layout and Process Documentation
All migration team members work off a generic file structure. This is very important for DTS routines and obviously for ease of administration during the migration process. The directory structure may vary significantly between projects, but a based set may be:
Note: myApp = source system name to be merged into corporate data model.
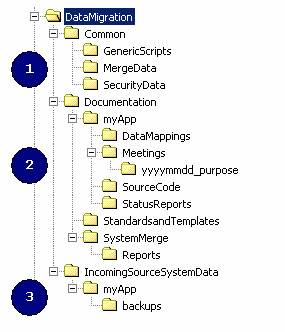
NOTE: Make sure this is a common drive map for all developers (ie. same drive/path)
1. Common directory
i. Generic script – all common utility scripts and command line tools.
ii. Merge data – includes all spreadsheets, Access DB’s or CSV files etc that have manually merged data for the corporate database to link two or more applications together. This area is critical and must be updated at a minimum. It will be used my a variety if people to approved the merging of records for subsequent data loads via DTS.
iii. Security data – optional and depends of your security framework within your application. Includes data files listing base security privileges and system parameters to be loaded into the corporate data model for the migrated applications.
2. Documentation directory
i. MyApp – documentation specific to the application. Base documentation templates will come from the directory below it and have created and managed by the DBA or analyst. This document has the step my step processes to load and report on a data migration for the application.
ii. Standards and Templates - includes code templates, migration document templates, naming conventions and associated standards.
iii. System Merge - information about the merging of data from one application to another, and the rules associated with the merge. Typically these are signed off my data owners and are pivotal for the merge process.
3. IncomingSourceSystemData directory
i. MyApp – copies of production databases (optional) ready for loading via DTA into the staging database(s). Multiple backup copies may be required.
General Naming Standards
Standards are critical for a successful migration as the amount of code can grow dramatically over time. In all cases the purpose of an object (see below) should be short, to the point and documented.
DTS packages
<newsys> - MIG - <purpose> loading reference data, staging databases etc.
Generic Utility T-SQL Code
mig.UTILITY_<purpose>_sp generic utility t-sql code, ie. stip <cr> etc
T-SQL Code
mig.MIG_REFDATA_<name>_sp single to many procs to load reference data,
may utilise remapping tables or call other remapping stored procedures.
mig.MIG_LOAD_<sub-app>_<purpose>_sp migration code specific to the sub-app
mig.MIG_REMAP_<name>_sp remapping specific stored procs (optional)
Tables
mig.MIG_REFDATA_<name> staging reference data
mig.MIG_REMAP_<purpose> remapping data tables, optionally add <sub-app>
mig.MIG_<sub-app>_<purpose> staging and other tables specific to app mig
mig.MIG_System_Log logging of all errors etc during running of stored procs
mig.MIG_Conversion_Matrix to map old p.keys to the new p.keys (where applic.)
Views
mig.MIG_sub-app>_<purpose> custom views
Tracking, Error handling and Transactions
The MIG_SYSTEM_LOG table should be used to track long running jobs, alternatively, the programmer may chose text files (especially if they are writing code in VB). This is not mandatory but available for use. The developer must take responsibility with:
a) clearing data from the table (and not affecting other users), this can be cater for the with the columns SystemLogIntendedFor or SystemLogByWhom and of course the date column for the table (see table structure below). The DBA may need to setup indexing and of course monitor space usage. Ideally, the DBA should set physical database limits to manage disk space or proactive monitoring scripts.
With T-SQL, the developer must determine:
a) what constitutes a transaction and a valid record or set of records. Take care with transaction management and ensure all transactions are counted for, you don’t want the DBA killing off an apparently stalled job only to find SQL Server rolls it back.
b) whether the first set of steps in the script is the remove all previously inserted data (in key order) in case then script is being run for a second, third of more times (typically due to error).
c) When to break out of the code and how? (do you need to cascade errors up the chain of code calls?)
Here are some examples code snippets:
<...>
<mysql statement>
set @v_error_count = @v_error_count + @@ERROR
<...>
if @v_error_count > 0 begin
print 'Error @ employer# '
print @emp_id
raiserror('Error in - MIG_MYAPP_Load_Employers_sp', 16,1)
while @@TRANCOUNT > 0
ROLLBACK TRAN
RETURN 1
end
<...>
In the data models I have worked with, all tables had these columns (or similar to):
last_update_count integer default 0 not null
last_update_on datetime default getdate() not null
last_update_by varchar(50) <no default, app user> not null
Therefore, standards were defined for record marking as they came to in easily remove records that belonged to your particular migration script. If you do not have this, look at using the matrix table (see next) to identify your rows verses existing data.
Core Migration Tables and Stored Procedures
The migration effort will result in data being remapped, requirements to track the progress of long running stored procedures, and operate simultaneously with other migration tasks underway in other areas of the corporate data model. As such, we require some pre-defined and documented tables to ensure based migration concurrency and auditing:
Conversion Matrix
This table tracks all new/old value remapping during data migration (where appropriate).
CREATE TABLE [mig].[MIG_CONVERSION_MATRIX] (
[table] [varchar] (50) NOT NULL ,
[typeof] [varchar] (80) NOT NULL ,
[newkey1] [varchar] (50) NULL ,
[newkey2] [varchar] (50) NULL ,
[newkey3] [varchar] (50) NULL ,
[newkey4] [varchar] (50) NULL ,
[oldkey1] [varchar] (50) NULL ,
[oldkey2] [varchar] (50) NULL ,
[oldkey3] [varchar] (50) NULL ,
[oldkey4] [varchar] (50) NULL ,
[notes] [varchar] (100) NULL ,
[lastupdated] [datetime] NOT NULL ,
[lastupdatedby] [varchar] (50) NOT NULL
) ON [PRIMARY]
GO
System Logging / Tracking
Used to tracks data migration activity and progress.
CREATE TABLE [mig].[MIG_System_Log] (
[SystemLogId] [decimal](18, 0) IDENTITY (1, 1) NOT NULL ,
[SystemLogDetails] [varchar] (2000) NOT NULL ,
[SystemLogTypeCode] [varchar] (25) NOT NULL ,
[SystemObjectAffected] [varchar] (50) NULL ,
[SystemLogDate] [datetime] NOT NULL ,
[SystemLogByWhom] [varchar] (50) NULL ,
[SystemLogIntendedFor] [varchar] (20) NULL
) ON [PRIMARY]
GO
Migration Step 1 – Staging Database(s) and Sourcing Data
The first step is to establish the MIG_ databases. If the temporary MIG_ databases are not possible then read-only linked servers may be used. Even so, never link to production databases for whatever reason. The MIG_ databases will be loaded often from their production system counterparts, and as such, must be repeatable and quick to run. I use DTS for a majority of the work here.
The major advantages to creating the MIG_ databases are:
- can run “pre-migration data fix” scripts against the data before we begin the major load
- once in SQL Server, its very easily to transform and query data rather than dealing with flat files or other database formats and syntax
- we have complete CRUD control
In the end it’s the DBA’s call. Very large data sources may be a problem and the time to load and build the MIG_ databases may be unacceptable. Even so look at a staged approach to the migration to resolve.
The regularity of the load will increase near the end of the data migration process and during initial testing. The DBA may choose to script the databases to easy of restoration. Be careful that replacing databases may impact multiple migration team members and can result in complete reloads of reference data etc associated with the staged data. Also be aware that a support server may also need to be refreshed in order for users to compare their production database snapshot with the migrated data set.
Look at indexing the MIG_ database tables to speed your extraction and querying of migration data, and always use a fill factor of 95% (you will never insert new data and the updates will be minimal).
Migration Step 2 – Load Core Reference Data
Up next we have the T-SQL stored procedure and DTS routines to load in the core application reference data. You will be surprised how many tables are reference data tables, at times being over 1/3 of the total tables.
Reference data is critical. I cannot highlight the importance of well-defined, accurate reference data as early as humanly possible. Why? For these fundamental reasons
impact the developers – who hard code ID lookups, eg. 1 = Postal Address type and 2 = Guardian, if you swapped these two months into the project then be prepared to wear a helmet.
change of codes or addition of missing codes can mean complete UAT and/or testing of coded logic to ensure the program still works.
can delay development as no data means no code cutting.
Reference data is not too difficult to source and most codes will be retained from the incoming systems. There will be a small percentage of tables that require code remapping. To mange reference data and remapping, I set-up the following spreadsheets:
refdata.xls – 1 sheet per incoming table
remap.xls – 1 sheet per table for remapping.
This maps to a single MIG_REMAP_<purpose> table within the MIG_NEWSYS database.
Not all reference data is kept in the spreadsheet, data may be transformed within a single t-sql routine to complete the load from the staging databases based on general agreement from all business owners.
This can cause issues with managing the reference data loads
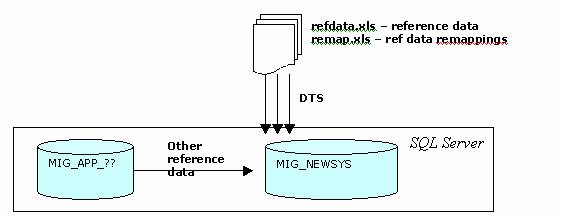
Spreadsheets are an easy way to maintain lists of reference data outside of the scope of other incoming migrated data sources. A single stored procedure should be developed to process all reference data. Use staging tables for reference data within MIG_NEWSYS, eg. mig.MIG_REFDATA_<name>.
Migration Step 3 – Ongoing Scripting and Loading of Core Data
It is very important that the migration database schema is kept fully in-sync with the other development database. The only trick here to watch out for is scripting changes from Enterprise Manager and running them in development may work fine, but in the migration database you thousands of extra rows etc, timing a change may require a little more timing. I have always kept a strict control of DDL in all database environments to better manage change, if this is a problem for you the look at schema comparison tools such as those available from red-gate software.
The DBA should also consider scripting the databases once per week for safety sake more than anything. This is of course on top of your daily backups. It is very rare that your staging and migration databases require anything more than full backups once per day, and possible twice if you consider a possible one-day loss too great. Don’t forget though that databases are one thing, but your file system with merge data and associated documentation is also critical.
The timing of staging database reloads needs to be planned with end-users and all affected migration team members. A reload of a staging database may coincide with the refresh of the production database on your staging server for example so end-users can report on the staging database to compare data with the migration effort.
Migration Step 4 – Merge and Remapping Data
Data merging is one of the most difficult tasks in the migration progress. You must be very careful here simply because people will be investing large amounts of their time and money mapping one data value to another and do not want to be told days or even weeks down the track that what they have been doing is no longer relevant. This can happen for a variety of reasons, but change of key is a typical gotcha.
As an example of data merging, I had two key systems that worked with traineeship data (a traineeship being a 2,3 or 4 yr contract between an employer and a student to undertaking on the job training in their chosen field, i.e. plumber). The problem here is one system had the apparent “definitive and fully accredited” set of traineeships but is wasn’t their core buss to manage students doing them, verses the other system whose job it was to track, manage and maintain traineeship contracts. Therefore, both had lists of “valid” traineeship codes and the associated qualification for the traineeship, and both business areas wanted their data.
In order to do this, we:
a) Load System A in first – this had the formally “approved” set of traineeships and qualification data. Identity value were fixed on a set range for these particular tables to cater for ensure expansion (yes – the systems still work as per normal while you are migrating).
b) Load in remapping tables
c) Load System B based on mapping table data.
The merge spreadsheets (remapping data) can be difficult to produce. Ours consisted of a series of sheets. The first has the 1:1 mapping to date of System A data with System B data (and their p.keys). The last column was an approved flag (Y or N) to denote a merge approval. Other spreadsheets includes all data values from System A and other sheet for System B, then a final sheet that had both systems data ordered by the description of the traineeship to assist users in locating “similar” records. Of course, this sounds all fine and dandy, but producing the sheets is tough. Look for a common ground for merging data over (id fields, descriptions, combinations of field etc). The critical part here is making sure that you have all the data necessary to map back to System A and B to complete the merge as stated in the spreadsheet. Don’t forget also to run scripts over the mapping tables from time to time to locate missing or new codes from the systems when new snapshots are taken.
Migration Step 5 – Core Data Migration
When I say “core data migration”, I am talking about the series of scripts that are run after staging databases are refreshed and cleansed and reference data has been loaded and validated. Once done, we begin the series of scripts that will populate the migration database (whose schema as previously mentioned is identical to what will eventually go into production).
The migration documentation for your system will clearly outline of pre-and-post scripts to be run for each stored procedure. The developers may choose to write a single t-sql routine that calls a series of others in step to make life a little easier. When using t-sql, use SET NO COUNT and take care with error handling. The developers should also be making using of the matrix and system tables. As a minimum, use the matrix table whenever keys are altered and data is to be remapped, this table should also go into production for future reference if need be.
