

Introduction
This article was created to help readers understand CosmosDB change feed processing. The knowledge gathered here has been achieved by prototyping change feed solutions, numerous discussions with the Microsoft Product team and more recently production implementations. This know-how is distilled here in a simplified form.
What is the Change Feed?
Microsoft describes the Change Feed as follows
With change feed support, Azure Cosmos DB provides a sorted list of documents within an Azure Cosmos DB collection in the order in which they were modified. This feed can be used to listen for modifications to data within the collection and perform actions.
One thing that’s not abundantly clear in the MS documentation is that the modification notifications are aggregated and the notification is actually the latest version of a document. No explicit CRUD actions are exposed. For example, the data retrieved from the change feed will not include metadata identifying an insert or update explicitly. If a document is modified many times in succession between change feed reads you will not be able to access the intermediate state changes. For example, consider the document modification journey insert→modification→modification. If the change feed is read after the three CRUD operations complete you will only see the aggregate of changes, the document state. You will not have access to the state after insert or the state after the first modification. The final state, after the second modification, is all that is emitted from the change feed. The change feed does not currently capture deleted documents.
What is the Change Feed Used For?
There are many applications for the Change Feed and Microsoft highlight many in this document. One of the simplest use cases is to simply migrate data to a target storage technology.
Let’s look at a typical topology for simple change feed processing. The topology includes exploiting the geo-redundancy capabilities of the CosmosDB product.
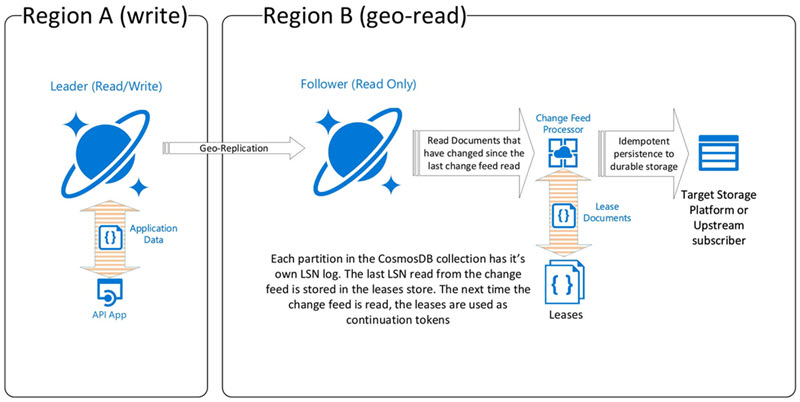
The change feed journey starts when an application inserts a document to the primary write region (the leader) of a CosmosDB collection. For the purpose of this documentation consider all transaction to be using the bounded staleness consistency level. CosmosDB’s internal local LSN (logical sequence number) is atomically incremented as part of the document insert operation. The LSN is broadcast to the secondary region (the follower). The follower is now aware that it is behind the leader and must catch up. The follower catches up by pulling the missing LSN transaction from the leader.
This is a rather crude depiction of the geo-replication used by CosmosDB. But it’s important to understand that LSN’s are being used to coordinate transactions and data across regions and that LSN’s are used to coordinate the change feed reads.
How Does Change Feed Processing Work?
Out of the box, the change feed is accessible by the CosmosDB client SDK and the CosmosDB REST API.
CosmosDB partitions are layers of compute and storage. Each partition manages a physical portion of the collection data and each partition has its own LSN to keep track of transactions. Change feed leases can be compared to reading a novel. You pick the book up, read it in sequence (page by page) for a period of time and then you need to put the book down. You don’t want to lose the page that you read last so you use a bookmark to pick up where you left off conveniently. In CosmosDB there are many partitions so one bookmark per partition needs to be maintained. The change feed lease collection is used to store a lease document per partition, the document includes the LSN bookmark. This lease collection can be any durable storage, it doesn’t have to be CosmosDB. However, all the implementations I’ve worked on to date use CosmosDB to store the leases.
Change Feed Processing Implementation Options
There are a few options when it comes to developing a change feed processor. Whether you want to create a push or pull mechanism limits those choices. The sections below summaries the possible options in order of difficulty
Write your own
This is the most difficult but flexible option. With this option both push and pull data subscription is possible.
The client SDK has a number of methods available for reading the change feed. In it’s simplest form ReadPartitionKeyRangeFeedAsync gets a partition key range per physical partition. The key range represents the upper and lower bounds of the partitioned data. If the partition key was alphabetical, the first partition may have range A-C and the second partition may have D-E and so forth. However, partition keys are hashes of the logical key values, so the key ranges are incomprehensible to the human eye. CreateDocumentChangeFeedQuery can then be invoked for each partition range returned by the ReadPartitionKeyRangeFeedAsync call. To create partition bookmarks (leases) you’ll need to persist the response.continuation tokens in durable storage.
Utilize the Change Feed Library
This option is relatively straightforward to implement and offers a degree of flexibility. It’s only possible to implement a push data subscription.
The change feed library is available as a NuGet package. So all you’ll have to do is reference it in your project and make sure you provide the relevant environment config; CosmosDB account URL, auth key and lease DB collection details (the change feed library expects the leases to be stored in Cosmosdb). Once the NuGet is referenced, its a simple case of writing a custom IChangeFeedObserver to process the document changes.
Change Feed Azure Functions
Microsoft announced the release of Azure Function for change feed at Ignite 2017. Using the new CosmosDB Azure Function template you’re able to construct server-less code. Microsoft effectively hosts the change feed library as a service on their internal infrastructure. The feed is constantly read for changes and the changes are then passed synchronously to the Azure Function as an input array. (the Azure Function template expects the leases to be stored in CosmosDB).
Illustration
Once change feed processing code is implemented it’s just a case of creating some actions in response to the change data. In this simple illustration, the data is idempotently stored away in durable storage. Changes are read from the change feed in LSN order per partition. Chronological ordering across partition is not guaranteed. This is not an issue if the documents are atomic, with no dependency on related documents.
Geo-Replication with Change Feed
Having a secondary geo-replicated region is not necessary for change feed processing to occur. It is entirely plausible to read the change feed from a non-geo-replicated region (single region topology). However, the vast majority of high SLA environments will adopt an HA/DR strategy including one or more geo-replicated regions. CosmosDB is a single master global distributed system, geo-replicated provisioning constraints mean that each region in the failover group has an equal amount of RU provisioned. Change Feed reads have an RU charge, so funnelling all the change feed request to a secondary region means that the additional read load is isolated from the primary read. This isolation allows the OLTP throughput of the application to be monitored separately.
Change Feed Step-By-Step
Step 1: The client application writes a document to the primary write region (leader).

Step 2: The document is replicated to the secondary geographical region (follower).

Step 3: The change feed processor reads the change feed and the document is returned along with the LSN.

Step 4: The document is persisted to durable storage using an idempotent operation.
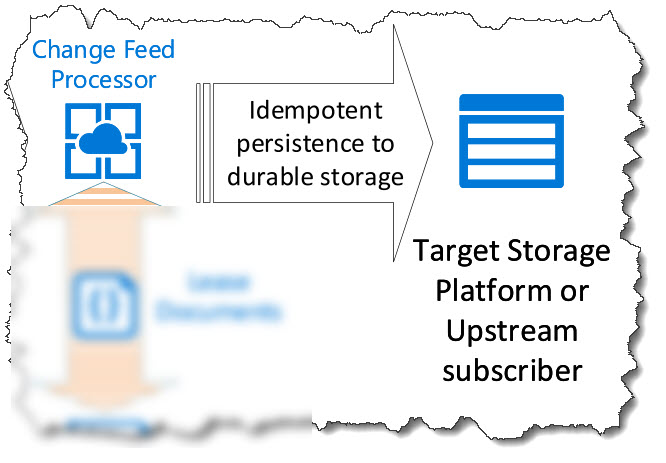
Step 5: After completion of the write to storage, the lease document is updated with the new LSN 1 (bookmark).
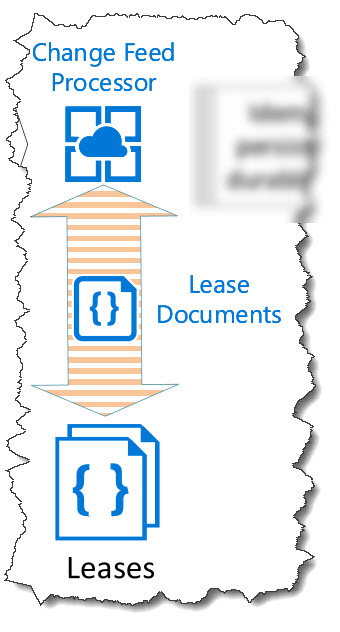
When a second document is written by the client application or the original document is updated by the client application, the LSN moves onto value 2 (step 1). Geo-replication takes place (step 2) and the secondary region is updated to LSN 2. The change processor retrieves the lease document from the lease store. This lease document has the LSN 1, which is then passed as part of the request header to the change feed. This tells the change feed to only return changes after LSN 1 (step 3). The document is then idempotently committed to the durable storage, and the lease is updated with LSN 2 (step 4 and 5)
Round Up
Whenever I read a technical article the thing I ask myself is “How do I use this new knowledge to serve future Gary”. I also like to ask myself “How does this new knowledge fit in with my current understanding of how a technology works.” So, I’ll try to answer both of those questions.
I’m sure a lot of readers will have a solid SQL Server background and will be assessing how CosmosDB and other new data technologies will fit into the systems they’re currently working with or may work on in the future.
Now we understand what CosmosDB change feed is, we can observe some architectural traits that are shared with some other familiar products/features.
If we look at two diagrams depicting CosmosDB Change Feed and SQL Server Change Tracking side by side we can observe a very similar picture.
| Change Tracking | Change Feed |
 |  |
The data flow in both diagrams starts with a business operation making a write to a database. The write is then read from a log of known changes and then propagated to a secondary system. We shouldn’t jump to the conclusion that change tracking and change feed are exactly the same*, but there are certainly many similarities that make them comparable. We can conclude that problems solved with the use of Change Tracking could also be solved with CosmosDB Change Feed and vice-versa.
* Change Feed doesn’t currently support delete operations.
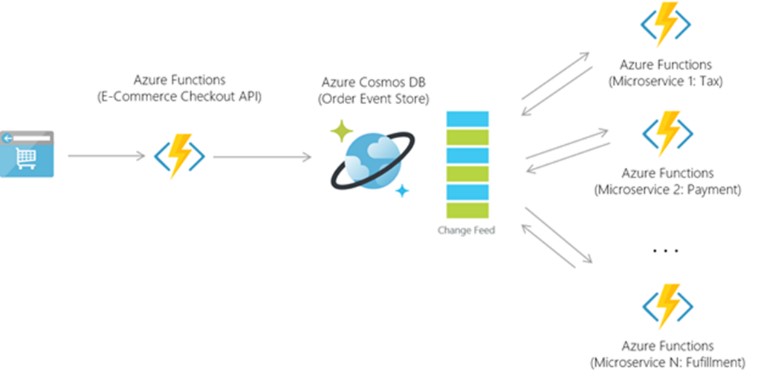
I have one more diagram to share but I won’t tell you where it comes from. Have a guess and put your thoughts in the discussion that accompanies the article.
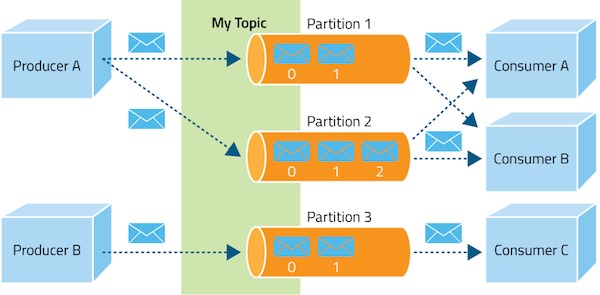
Again, we can see some very similar data flows. Data is produced, stored and then later propagated to a secondary system. Without giving the game away, the diagram doesn’t include any database, but the data flow still looks very similar to that of Change Tracking and Change Feed. I think this last diagram demonstrates how the lines between database features and data flow technologies are becoming progressively blurred. Moreover, Technologies like Change Tracking and Change Feed are becoming increasingly important and more commonplace in system architecture as we seek to integrate data into a greater and more diverse number of downstream systems.



