

In a previous article, I wrote about how to create your first stored procedure. This was in response to a number of questions, online and off, where individuals seemed confused about how to actual structure code in T-SQL outside of a query. That article covered the basics of writing a stored procedure and adding parameters, as well as a few suggestions. This article will go more in depth on some additional good practices that are helpful, and look at table valued parameters.
Create or Alter
When I started working with T-SQL, I was surprised at the language structure that required different code for objects, depending on when you worked with them. I had come from compiled languages where we always created constructs when we needed them with some definition like:
public static void SomeProd {
// do something
}In T-SQL, I had to get used to building a stored procedure like this:
CREATE PROCEDURE MyAmazingCode
@SomeParam int
AS
BEGIN
-- Do something here
SELECT @@VERSION
ENDIf I later decide to modify the code, say, add another parameter, I need to do this:
ALTER PROCEDURE MyAmazingCode
@SomeParam int
AS
BEGIN
-- Do something here
SELECT @@VERSION
ENDThat's crazy, and to me, that's a sign of a broken language. Perhaps it makes sense with table, though I'd argue that, it really makes no sense with views, stored procedures, and functions. In any case, prior to SQL Server 2016, we had to build programming structures that accounted for whether the object existed. I've seen people do things like this:
IF EXISTS (SELECT OBJECT_ID('dbo.MyAmazingCode'))
DROP PROCEDURE dbo.MyAmazingCode
GO
CREATE PROCEDURE dbo.MyAmazingCode
@SomeParam int
AS
BEGIN
-- Do something here
SELECT @@VERSION
ENDOr this:
IF OBJECT_ID('dbo.MyAmazingCode') IS null
EXEC('CREATE PROCEDURE dbo.MyAmazingCode as select 1')
GO
ALTER PROCEDURE dbo.MyAmazingCode
@SomeParam int
AS
BEGIN
-- Do something here
SELECT @@VERSION
ENDI'm not sure which I like better, but I don't really think any of them are great. In SQL Server 2016, we got the IF EXISTS clause, which meant we could do things like this:
DROP PROCEDURE IF EXISTS dbo.MyAmazingCode
GO
CREATE PROCEDURE dbo.MyAmazingCode
@SomeParam int
AS
BEGIN
-- Do something here
SELECT @@VERSION
ENDThat's still not great, but we also got CREATE OR ALTER in SQL Server 2016. That means I can just write this code all the time.
CREATE OR ALTER PROCEDURE dbo.MyAmazingCode
@SomeParam int
AS
BEGIN
-- Do something here
SELECT @@VERSION
ENDWe should have had that at the beginning. Actually, they should have just gotten rid of ALTER and allowed a CREATE PROCEDURE to create a new procedure or just automatically alter the existing one. What would have mattered?
I would recommend that all SQL Server 2016 or great code ought to use CREATE OR ALTER.
SET NOCOUNT
One of the common recommendations for a stored procedure is that you use SET NOCOUNT ON at the beginning of the code. We typically do this as follows:
CREATE OR ALTER PROCEDURE MyAmazingCode AS BEGIN SET NOCOUNT ON -- Do incredible coding here END
This is to prevent the server from sending row counts of data affected by some statement or stored procedure to the client. This reduces the communication of data to the client and lowers network load. SQL Server can be chatty, and this is one of those areas that can improve performance.
In SSMS, you would see this data on the Messages tab in your Query Window. An analysis over at SQLPerformance.com shows that on modern versions of SQL Server and hardware there is minimal impact, but it is still a recommended practice to reduce network communication where possible.
Many people also recommend setting XACT_ABORT on for your procedure, but plenty of people don't. You should understand hwo this works before you add it to your procedures.
Commenting Your Procedure
Since a stored procedure is often longer than one line of code, it may not be obvious what the purpose of the procedure is for your application. Adding a comment that describes the overall purpose is helpful for another developer (including yourself) that may look to modify this code in the future.
Let's look at an example. Here is a stored procedure from the AdventureWorks sample database. While I prefer the /* */ structure for multi-line comments, there are a number of good things to note here. First, the top comment explains what happens with the procedure and how it is to be used. This let's a developer know that this should be called from a CATCH block.
Next, I like the documentation of the OUTPUT parameter. This let's someone know that wants to use this procedure how they can get information back. I also think the comments about when the procedure ends quickly explain why this happens. There isn't a point in commenting that if the ERROR_NUMBER() is null or the XACT_STATE() is -1 that the procedure returns. I've seen those comments and they are not useful. This tells me why the procedure behaves a certain way.
I would say that the comment in returning the @@IDENTITY value isn't needed. Most users should know this, and they should also know that SCOPE_IDENTITY() ought to be used here.
-- uspLogError logs error information in the ErrorLog table about the
-- error that caused execution to jump to the CATCH block of a
-- TRY...CATCH construct. This should be executed from within the scope
-- of a CATCH block otherwise it will return without inserting error
-- information.
ALTER PROCEDURE [dbo].[uspLogError]
@ErrorLogID [int] = 0 OUTPUT -- contains the ErrorLogID of the row inserted
AS -- by uspLogError in the ErrorLog table
BEGIN
SET NOCOUNT ON;
-- Output parameter value of 0 indicates that error
-- information was not logged
SET @ErrorLogID = 0;
BEGIN TRY
-- Return if there is no error information to log
IF ERROR_NUMBER() IS NULL
RETURN;
-- Return if inside an uncommittable transaction.
-- Data insertion/modification is not allowed when
-- a transaction is in an uncommittable state.
IF XACT_STATE() = -1
BEGIN
PRINT 'Cannot log error since the current transaction is in an uncommittable state. '
+ 'Rollback the transaction before executing uspLogError in order to successfully log error information.';
RETURN;
END;
INSERT [dbo].[ErrorLog]
(
[UserName],
[ErrorNumber],
[ErrorSeverity],
[ErrorState],
[ErrorProcedure],
[ErrorLine],
[ErrorMessage]
)
VALUES
(
CONVERT(sysname, CURRENT_USER),
ERROR_NUMBER(),
ERROR_SEVERITY(),
ERROR_STATE(),
ERROR_PROCEDURE(),
ERROR_LINE(),
ERROR_MESSAGE()
);
-- Pass back the ErrorLogID of the row inserted
SET @ErrorLogID = @@IDENTITY;
END TRY
BEGIN CATCH
PRINT 'An error occurred in stored procedure uspLogError: ';
EXECUTE [dbo].[uspPrintError];
RETURN -1;
END CATCH;
END;
A good recommendation is to have a simple, but useful header that you use to document the purpose of your procedure and then include comments in places where you think the next developer might not know why you implemented some code. It's easy to determine what is happening, and certainly everyone should have a VCS that stores code to know who and when things changed, but the why is often lost. I might re-use a comment on why I made a change in both the procedure and as my VCS commit message.
Here is an example of a stored procedure header that I have often used. Note that while I like including the comment inside of the body of the stored procedure, it could be placed above.
CREATE PROCEDURE [schema].[procedure_name]
/*
Descripton:
Returns:
Updates:
*/AS
GOThis allows me to explain why the procedure is used and how it works at a high level. If there are return values (or OUTPUT params, I'd include them in the Returns: section. Otherwise I'd leave that out. The Updates would contain lines with a date that explain what I've changed.
CREATE OR ALTER PROCEDURE dbo.GetOldArticles @StartDate DATE = NULL, @EndDate DATE = NULL /* Descripton: This procedure scans older articles that have previously been published and returns those articles that meet this criteria: - not linked externally - last publication date between the parameter values - ordering by rating, then reads If parameters are not passed in, the default range should be 36-24 months previously (start-end) Returns: Result set with article ID, name, last publication date, rating, and reads. Updates: 20170601 Changed the parameter setting to use sysutcdatetime() instead of getdate() because of a server move to UTC time. */
This is fairly lightweight, and while some of this might be duplicated in a VCS comment, this is a good way to keep some consistency of what the procedure does with the code. In an emergency situation where a deployment might have failed or this may be causing data issues, having a description of what the procedure should to is invaluable.
One note about comments. If they appear before the BEGIN statement, you will see them in Profiler if you use this. If they are after the BEGIN, this doesn't happen. Note, don't use Profiler. Learn to use Extended Events.
Nesting Stored Procedures
In many languages, functions and methods are used to encapsulate small sections of code and you call these as needed, never worrying about how many times a function might call another function. That's not the case in SQL Server.
While stored procedures are a valuable tool for encapsulating some logic, you must be careful becuase there is a limit to how many levels deep you can nest stored procedure calls. That limit is 32, which means if you build a complex system that has each stored procedure doing a little work but calling other procedures, you might run into this limit. In practical code, I haven't seen this occur, but I know it does happen to some people.
When you design a stored procedure, this is usually to manipulate some data and potentially return results to a calling piece of code. Often that is a client, but at times it might be other code. T-SQL is a set based language, not a row based one, so if you find that you are calling lots of procedures to do a piece of work and each might call other procedures, you ought to re-examine the design of your code and ensure that you work with sets of data (multiple rows) where possible.
In a practical sense, there are times that you need to call another procedure from the current stored procedure. We do that with the EXEC command. Here's an example.
Let's suppose I have a procedure that is designed to return the total of current day's sales orders and the name of the customer with the largest order for that day. I have another procedure that already gets the largest customer order of the day and want to use that rather than repeat that code.
CREATE OR ALTER PROCEDURE dbo.GetLargestOrder
AS
BEGIN
SELECT TOP 1
CustomerKey
, oh.OrderKey
, OrderTotal
FROM dbo.OrderHeader AS oh
ORDER BY OrderTotal DESC;
END;
GO
CREATE OR ALTER PROCEDURE dbo.GetDailySalesSummary @dt DATE
AS
BEGIN
CREATE TABLE #LargeOrder
( CustomerKey INT
, OrderKey INT
, Ordertotal MONEY);
INSERT #LargeOrder EXEC dbo.GetLargestOrder;
SELECT CustomerKey, OrderKey, OrderTotal FROM #LargeOrder AS lo
UNION ALL
SELECT
CustomerKey
, OrderKey
, OrderTotal
FROM dbo.OrderHeader AS oh
WHERE OrderDate = @dt
ORDER BY lo.Ordertotal DESC;
END;
GO
Notice the second procedure contains a call to the first procedure. If we were to check the @@NESTLEVEL inside of the dbo.GetLargestOrder procedure, it would be 2 when being called from dbo.GetDailySalesSummary. This is because we have two procedures being executed in the calling stack. We can nest up to 32 procedures, but this is rarely a practical level of nesting code.
Table Valued Parameters
One of the changes in the T-SQL language was the addition of table valued parameters (TVP). While SQL Server supports up to 2100 parameters in a stored procedure, that is a very cumbersome way to transfer data. Starting with SQL Server 2008, T-SQL allowed a table type to be used as a parameter and contain a number of rows as parameters.
In order to use a TVP, we must first declare a table type that is the structure of the table we wish to pass into a stored procedure. We then use this type as our parameter, both in the stored procedure header and in the calling routine. Let's see an example.
I will create a type that holds status values. For my simple example, I am using a single column, but I could easily include multiple columns.
CREATE TYPE dbo.StatusValues AS TABLE (StatusKey INT);
When I define my stored procedure, I include the TVP as any other parameters. The data type is the Type itself. This is shown below.
CREATE OR ALTER PROCEDURE GetOrderWithStatus
@dt DATE
, @status StatusValues READONLY
AS
BEGIN
SELECT
oh.OrderKey
, oh.OrderDate
FROM
dbo.OrderHeader AS oh
INNER JOIN @status AS s
ON oh.Status = s.StatusKey
WHERE oh.OrderDate > @dt;
END;
GO
When I want to call this, I need to create another variable using this type. I then add the data I need and pass this into the stored procedure call.
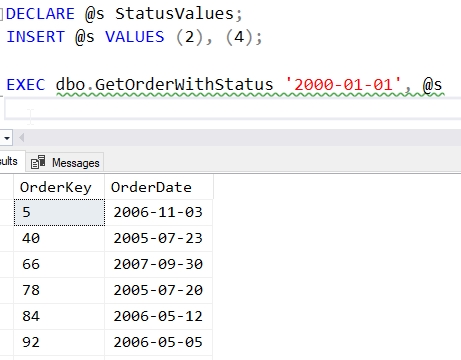
This allows me to structure my stored procedure to work with a set of data provided by the calling routine.
A couple of limitations should be noted. First, the TVP must be read only in the definition. If I try to compile a stored procedure without the READONLY keyword, I will get an error. I cannot change the data in the TVP inside of the stored procedure. Second, I cannot use these as the target of a SELECT INTO or INSERT EXEC routine.
Moving On
This article is designed to try and give you some ideas and recommendations for building better stored procedures. We look at a few of the code structures that you can use in your code and how to better document your stored procedures. We also touched on parameters and nesting.
Stored procedures provide a great abstraction that allow you to work with data in a loosely coupled way in your application code. They work well with Entity Framework, NHibernate, and other application code. These give you some freedom to modify the underlying schema, while providing a stable API to your application.
I highly recommend that you learn to write and use stored procedures as a way of encapsulating data access in your code.
