

I had a chance to meet Brooke Philpott, the lead developer of
sqlSentry, at TechEd 2005 in Orlando this year and discuss a
few technical points about the product. It's always interesting to hear about
the development of a product, so we decided to
continue the discussion via email and with Brooke's permission, the result has
been written up in an interview format.
AW: Brooke, let's start with some background about you, and then move into some
technical questions. First question - how did
you get into programming?
BP: I began programming at 8, when my parents bought my brothers and me an Apple
IIc. I began writing simple programs in Apple Basic. I liked games like Zork so
I started writing text based adventures. I was always fascinated with games and
my parents bought me a C game programming book at that time, but I remember
telling them I couldn’t use it because I didn’t have that compiler. They had
no idea what I was talking about. After that I didn’t really program until I was
a sophomore in college.
I majored in Mathematics and I started learning how to program in
Mathematica. I really wanted to do a Mandelbrot
set generator because I’d studied fractals in high school and I found them to be
really interesting (and great looking). At
that time 24-bit color machines were finally readily available, so I set out to
do a Mandelbrot set generator and finally
finished my first prototype. It ran dog slow but it rendered the set in true
color. I continued to refine it and my third
iteration was 100 times faster than the first. That really got me excited. After
that I took another programming course for
math and learned C++/Java. I decided to write a
Mandelbrot set generator (see a
pattern here?) in C++ for my Macintosh
PowerPC. That was much harder than using Mathematica because I had to use a lot
of Pascal-based libraries like QuickDraw and I was pretty much teaching myself
at that point (the teacher was teaching me how to write for loops and cin/cout,
not 24-bit
rendering/QuickDraw usage). Eventually I got something done but I almost tore my
hair out in the process.
AW: Did you see yourself as a programmer when you were young?
BP: I guess, since I was programming at 8. I didn’t know whether I’d end up a
programmer, but I knew I was going to be doing
“computer stuff”, I just wasn’t sure if it would be hardware or software as I
was also very into electronics at that time.
AW: Where did you go to college and what was your major?
BP: I went to Davidson College and majored in Mathematics.
AW: How long have you been with sqlSentry?
BP: I’ve been working on sqlSentry since the product's inception about two and a
half years ago. I've been with InterCerve,
the company behind sqlSentry, for over 5 years. Initially I was charged with
coming up with a visual renderer for jobs to
help get a handle on schedule collisions occurring on our own SQL Servers, so
the very first thing I worked on was the
concept code for the calendar. That work began as a side project during time
away from other projects, and quickly expanded
from there.
AW: A big coding question with most developers I've worked with: lights on or
lights off?
BP: When I’m at work I code with the lights on because I’ve got other people
around me. When I’m working from home though I keep them off with no music or
other distractions. I tend to focus better that way.
AW: How big is the development team?
BP: The development team is five. We have two core developers, myself and Seth
Dingwell who have ownership of all the C#
code, plus Greg Gonzalez (the PM and President of the company) writing some of
the remote stored procedures like block
detection, remote queue failsafe code, DTS and SQL Agent Log readers, etc. Greg
also provides a lot of expertise in the areas
of database performance tuning/indexing, so we can get the product running as
fast as it can on the SQL Server platform. We
have two other developers that work on targeted areas like the licensing process
on more of an as-needed basis, and they work
on other InterCerve development projects as well.
AW: Working in such a small team usually is pretty exciting. Do you enjoy it or
would you like to have more people working on
the development of the product?
BP: Working on a small team has its advantages. I like the tight feedback loop.
When we want to get something done we just
sit down, talk about it, scope it out, and do it. Things are very efficient. On
the other hand, it can be difficult to get
such a large project completed in such a small time with such a small team. It
takes a lot of hard work and discipline. The
product being the size it is could benefit from additional developers (I think
this is true of most projects) but with that
comes other challenges. Source control gets trickier. It’s more important to
make sure everyone has a clear focus on what
they need to be doing. And, of course, you have to pay more money to keep all
the developers on the payroll.
AW: Let's move into some more product specific questions now. What language are
you using and why did you choose it?
BP: We chose C# for a number of reasons. We wanted to move to .NET as we all
came from VB backgrounds and wanted rapid
development, as well as the increased power and flexibility offered by the
framework. At the time that sqlSentry was started
version 1.1 of the framework was out and we had already starting using C# as our
primary programming language. Personally I
was attracted to the language because it was very clean and concise. I always
felt that VB.NET got syntax extensions to
handle things it wasn’t initially designed for, and hence things that should be
relatively straightforward, like casting,
become garbled using functions like
CType. I also prefer case sensitivity in a
language. Interop using
also flows
better because I can take C/C++ samples and modify them relatively easily if I
need to.
AW: How many lines of code is sqlSentry?
BP: sqlSentry v2.0 is roughly 250 thousand lines of code, including reusable
libraries written during the process (the
calendar, thread management, and general utilities). This is up from about 80
thousand lines in our v1.2 product.
AW: Do you use SQL-DMO for managing the jobs?
BP: We started using SQL-DMO but had problems with reliability. SQL-DMO is very
stateful, and we may need to pass around a
“job” object to multiple parts of the app on multiple threads, plus save/load
attributes of that to and from the database. We
ended up getting a lot of exceptions because we’d need that job to be readable
and couldn’t always count on it, because if
the connection it was attached to was disconnected for any reason reading the
properties wouldn’t work. It’s also a lot
thicker because it’s COM, so we wanted to move away from that. Right now we are
using SQL-DMO in a few specialized places,
like creating a job script and reading SQL Server/Group registrations from the
registry.
AW: I understand the application also makes use of SQL Name Space - where/why do
you use and how has it worked out?
BP: SQL-NS allowed us to quickly tie into forms that may have otherwise taken a
long time to recreate, at the same time
providing a familiar UI for the DBA. We knew when somebody clicked properties on
a job we wanted to show the job properties
as they look in Enterprise Manager, but we didn’t want to reinvent the wheel.
SQL-NS made it a snap to do so. However,
bringing up the SQL-NS forms via COM-Interop is easier than getting rid of them.
We were plagued early on with some very
strange errors, including ones that would just make the application crash
outright. We were able to resolve every known one
by just being really aggressive about getting rid of SQL-NS when done by
explicitly calling Marshal.ReleaseComObject and
CoFreeUnusedLibraries() via P/Invoke. Without these we ran into issues like heap
corruption.
AW: Using SQL-NS seems to have made a lot of sense for you and your users, what
do you think about Microsoft's decision to not
implement something similar in 2005?
BP: While I would liked to have seen SQL-NS like functionality in 2005 there
just wasn’t enough demand for it. Our long-term
plan was always to replace these screens with our own versions anyway, so it
won't really impact us too much other than
expediting that process a bit. SQL Server 2005 is huge product release and I
think in order to make any sort of deadline
Microsoft had to decide which features would make the cut. When we spoke to
them, they were surprised we were using it, as
they had a small number of developers that were using the feature in 2000. It
was always unsupported anyway, so I can
understand why it didn’t make the cut for 2005. Ultimately you have to provide
the features that benefit the customer most
and I wouldn’t want them to hold up the 2005 release for another 3 months just
for us and some other development shops using
SQL-NS.
AW: What has been the most complicated feature to implement and why?
BP: There are two. The first was the tiling algorithm for the calendar on
busy/complex schedules. Getting the calendar to render single events was easy,
but getting it to organize events when there are a lot of events was a
challenge. I think I went through 5 algorithms before I finally got the one that
works 100% of the time, which is the one you see in the product today. It was
finalized before 1.0 but every time I thought I had it nailed some weird case
would pop up and it wouldn’t lay out the events correctly. The other really hard
piece was the Job Monitor, which actively looks at running jobs and sends
notifications when they start, exceed a run threshold, or are missed. It was
tough because we are not scheduling these. We have to go in after the fact and
figure out when they are going to run and pretty much handle any transition SQL
Agent throws at us. For instance, if you know a job is scheduled to start at
10:00 AM and it runs for 2 hours, how do you know when it’s started? You can’t
read the log file because SQL Agent doesn’t write to the log until it’s done. If
you rely on the fact that it’s executing you may miss it if it’s a short running
job. How do you know when it’s complete? You can’t use the execution status
because it may start again before you check that. All in all it’s pretty
complicated and you have to have a lot of
different checks and balances to make sure you get everything.
AW: Do you have an install where we could get a screen shot of a very
complicated schedule?
BP: Here is one of a busy global view showing long running jobs and failures
across all servers.
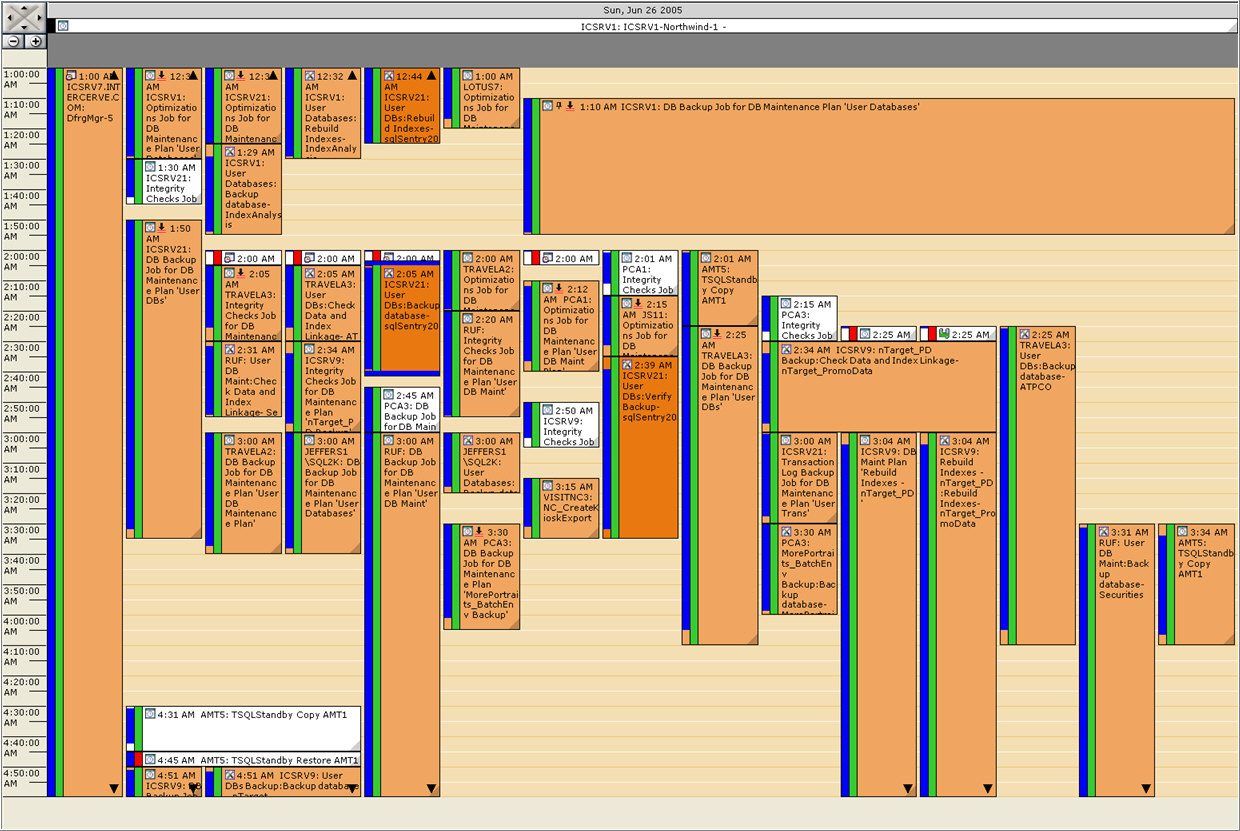
Click for larger image
AW:
What's your favorite feature?
BP: My favorite feature is the notification system. I’m really proud of that
part. It’s very scalable and is very flexible at the same time. I can say that
certain conditions are only allowed to be assigned to certain object types (job
started can only be assigned to jobs) and certain actions can only be assigned
to those (kill job can’t be assigned to job completed). This allows a rich user
experience without really any hard coding since these relationships are stored
internally. The engine
handles the mappings and the inheritance of conditions (global to server to job
levels). The whole system can be easily extended as well and can apply to more
than just jobs/SQL Server. You could base any monitoring/notification system
around it. You just create the conditions and actions, the relationships between
them, then feed messages into the notification pipeline when things occur and it
takes care of the rest.
AW: What do you believe is the most overlooked benefit of using sqlSentry?
BP: I think its probably queuing. Queuing is complicated and a lot of people
don’t fully get it (it took me a while to
understand.), but it can be extremely effective in helping level your schedules
across your server, because it provides a way
for sqlSentry to dynamically reschedule jobs as they are about to run based on
the load of the current system. It’s very cool
but it takes a little while to figure out the intricacies.
AW: What's a scenario where queuing makes sense?
BP: Queuing is great for cases where you want a particular job to be able to use
whatever resources it needs (disk, cpu, memory, network, etc.) and not have to
compete with other jobs, but you either can't or don't want to define explicit
dependencies using our chaining feature. Greg Gonzalez's (sqlSentry product
manager) recent article in SQL Server Standard illustrated how even a small
amount of schedule contention can lead to significant performance problems and
prevent jobs from ever reaching their optimal runtimes...which can lead to the
dreaded maintenance window overrun. For example, if I have a backup job that is
being slowed down every night by several recurring jobs that run continuously, I
can simply right-click the backup job on the calendar and set it to queue up to
5 other jobs for a specified time, say 30 minutes. Next time the backup job runs
sqlSentry will effectively put up to 5 other job schedules "on hold" until
either the backup job completes, or runs past 30 minutes, allowing the backup
job use whatever resources it needs during that time. There are several other
options to give you precise control over exactly what will be queued and for how
long, as well as whether or not a queued job auto-starts automatically or
resumes its next scheduled run upon leaving the queue. The image below is an
example of a backup job that queues several recurring jobs, and how queuing
helped reduce it's runtime by 7.5%. orange represents schedule collisions.

Click for larger image
AW: Sounds like you've put a lot of time into it - any planned enhancements on
the horizon?
BP: Probably the best new queuing feature in v2.0 is the ability to set an
"auto-start threshold" for any queuing job. One risk with queuing has always
been that if a queuing job happened to queue some critical job that only runs
once a day or less
frequently, say a nightly backup job, if you didn't remember to set the backup
job to "never be queued" or to auto-start
automatically when popping off the queue you might miss a scheduled run. In our
v1.0 product you had to remember to do this
for any critical jobs, which could be quite tedious.
In v2.0, the auto-start
threshold defaults to 4 hours, which means that any time a job is queued, when
it pops off the queue if its next scheduled run is more than 4 hours in the
future it will auto-start automatically...if it's within 4 hours it will resume
it's next scheduled run. This does two things: it prevents those critical
non-recurring jobs from ever missing a run, and it helps even the load when a
queuing job completes by only auto-starting the jobs that really need to be
started, thus minimizing contention from a bunch of jobs being auto-started at
once. The best part is you don't have to touch any jobs other than the queuing
job for this to happen.
AW: Can you tell us a bit about your internal beta program that you conduct
before any public releases?
BP: For maintenance releases, the developers test the code first after it’s
written and before anything is checked in. We
consider that Phase 1. We do a build when we are ready that’s internal. After
that everything is labeled, our issue tracking
system is updated that items are ready for test, and the build is marked. We’re
fortunate that one of the business units of
our parent company, InterCerve, is a Microsoft-focused hosting operation, so we
have a tremendous test bed internally to help
flush out issues early before we push anything out to external beta testers or
the general public.
So in Phase 2 it moves to
our testers and DBA's here internally, who verify every change and also start
using it day to day, running it 24/7 against
over 100 servers (SQL Server and Task Scheduler). I call this the “bake” period
because it’s in the oven. Generally we let
this set for a while until we are comfortable that the fixes and features were
implemented correctly and no regressions were
introduced. Once we reach that point we release it to the public.
New to
sqlSentry v2.0 is an automated version checker, so
users are notified right away whenever a new build is available. After a major
release we average one maintenance release
every 1 - 2 weeks, and this feature has proven invaluable in helping ensure
customers have the latest and greatest bits.
For major releases it’s a similar process but we obviously have a larger
dev/testing window, and before public release we
also have a Phase 3 where it’s sent to a targeted set of private beta sites that
tend to have large, complex environments
since we really want to stress the app. Our integrated exception reporting
system is key during all beta phases as it enables testers to report issues with
minimal effort. It’s also critical after release to the public since if anything
happens to slip through beta we know about it right away.
AW: What about exception reporting? Is that done via email or internet
connection?
BP: It's done via Internet connection to a secure web service if the "submit"
button is clicked on the exception dialogue box. If connectivity isn't available
the user can just as easily copy and paste the exception details into an email
and send it to us. Most of the exceptions that come in are via the web service.
From there we have an exception management system which aggregates submitted
exceptions by build #, total unique users affected, times submitted, etc., which
is great for helping us prioritize the associated fixes.
AW: How many support requests do you get in a week/month?
BP: On a light week we may have about 5 requests. On a busy week we may have 20
to 40. The monthly average is probably around
100. We’ve recently introduced forums and a KB on our site to give folks another
means to find answers without having to
contact support directly. We’re also in the process of rolling out a customer
portal so that users can log in and submit
bugs and feature requests as well as check the status of their open issues.
AW: You mentioned that the application checks for updates automatically. Many
servers are firewalled with no access to the
internet. Can I assume it fails gracefully in such situations? And what are the
alternatives to learn about updates?
BP: This is true, many servers are firewalled and can't use it. However, what
we've found is that many DBA workstations do have Internet access, and since the
update checker runs only from the sqlSentry Console which is typically installed
on the
workstation, it is able to connect successfully. It's on by default and checks
only when the console is first opened, and
since it runs on a different thread it won't block other console activity while
it's trying to connect. If it can't connect
it will respond gracefully with an error message, and can easily be disabled
permanently by checking a box. If the user isn't running the update checker they
can always go directly to our download page to get the latest build:
We do email users whenever a major version or "milestone" incremental version is
released, but we don't typically email users for every minor incremental
release. That is unless we are working with someone
on a particular issue that affects them, in which case we'll let them know
directly as soon as a new build is available with
a fix.
AW: How will the changes in SQL Server 2005 affect the application? Will it
require a different version?
BP: There are some pretty significant changes in SQL Server 2005. Some are
small, like the fact that jobs and schedules are
separate entities with a many to many relationship versus a one to many. Others
are more significant, for example, the
transition from DTS to SSIS. Others are non-existent (SQL-NS is gone in 2005).
There will be a new version required to
support 2005 due to these changes, sqlSentry v2.5, which we just announced at
Tech-Ed. (link: http://www.sqlsentry.net)
Vendor Update: sqlSentry v2.5 was released on
November 30, 2005
AW: Brooke, I think that wraps up the technical questions. Let's conclude
with a final question about you - what do you do to relax and have fun? And do
you have a photo to share so we can make you famous?
BP: I try to keep in shape so I work out about 5 times a week. I’m a big gaming
fan so I play online games like World of Warcraft
and
Battlefield 2 (my current
favorite). I like to travel as well when I have the time. I’m also trying to get
back into making music but it’s a time consuming process.



{kind=link}