

Introduction
As DBAs, we often think of INCLUDE columns as a harmless way to cover queries.They aren’t part of the index key, so it’s easy to assume that adding them wouldn’t have much impact.
This thinking is dangerously incomplete. While INCLUDE columns don’t participate in index order, they physically reside in index leaf rows. The silent impact of this design choice became crystal clear in a recent experiment I ran to test how INCLUDE columns affect transaction log generation during updates.
INCLUDE columns only: When you update columns that are only in the INCLUDE portion of the index (not part of the key), SQL Server doesn't need to maintain the index structure – it simply updates the leaf-level data. This generates log records, but not as much as key column updates.
Key column updates: If you update columns that are part of the index key, this requires more log activity because the index structure may need rebalancing. SQL Server logs a delete and insert for the affected index rows, including all INCLUDE columns, resulting in higher log volume.
Wider rows: Adding more INCLUDE columns makes index rows wider. As a result, whenever updates occur – even if they’re not on the INCLUDE columns themselves – slightly more data gets written to the transaction log because the overall index row structure is larger.
While it’s understandable that adding INCLUDE columns increases index size and, consequently, full backup sizes, what’s not so obvious is how it also causes transaction log sizes to grow. This indirect behaviour is the real focus of our discussion.
Setup: Building a Realistic Orders Table
In this setup, I first created a database named TestLogImpact and set it to FULL recovery mode to enable transaction log backups for precise measurement. I then switched to this database and dropped any existing Orders table to start clean. Next, I created a wide Orders table simulating a realistic ERP scenario with columns such as CustomerID, OrderDate, ShipDate, Quantity, Price, Status, Comments, Region, CreatedBy, UpdatedBy, and five additional VARCHAR(500) columns named Extra1 to Extra5 to simulate payload-heavy tables. Finally, I inserted 100,000 dummy rows into this table by selecting from a CROSS JOIN of sys.all_objects to generate sufficient data volume. Each row was populated with a random CustomerID between 0 and 999, current dates for OrderDate and ShipDate, random Quantity and Price values, and repeated strings for Comments and all Extra columns to ensure wide rows. This dataset created a practical yet performance-impactful baseline for testing how index INCLUDE columns affect transaction log generation during subsequent updates.
CREATE DATABASE TestLogImpact;
GO
ALTER DATABASE TestLogImpact SET RECOVERY FULL;
GO
USE TestLogImpact;
GO
DROP TABLE IF EXISTS Orders;
GO
CREATE TABLE Orders
(
OrderID INT IDENTITY PRIMARY KEY,
CustomerID INT,
OrderDate DATE,
ShipDate DATE,
Quantity INT,
Price DECIMAL(10,2),
Status VARCHAR(20),
Comments VARCHAR(500),
Region VARCHAR(50),
CreatedBy VARCHAR(50),
UpdatedBy VARCHAR(50),
Extra1 VARCHAR(500),
Extra2 VARCHAR(500),
Extra3 VARCHAR(500),
Extra4 VARCHAR(500),
Extra5 VARCHAR(500)
);
GO
INSERT INTO Orders (CustomerID, OrderDate, ShipDate, Quantity, Price, Status, Comments, Region, CreatedBy, UpdatedBy, Extra1, Extra2, Extra3, Extra4, Extra5)
SELECT TOP (100000)
ABS(CHECKSUM(NEWID())) % 1000,
GETDATE(),
GETDATE(),
ABS(CHECKSUM(NEWID())) % 100,
CAST(ABS(CHECKSUM(NEWID())) % 5000 + 100 AS DECIMAL(10,2)),
'Open',
REPLICATE('Comment', 20),
'North',
'System',
'System',
REPLICATE('Extra1', 50),
REPLICATE('Extra2', 50),
REPLICATE('Extra3', 50),
REPLICATE('Extra4', 50),
REPLICATE('Extra5', 50)
FROM sys.all_objects a
CROSS JOIN sys.all_objects b;
GO
Step 1: Taking a Full Backup
Since log backups require a base full backup, I took one before proceeding.
BACKUP DATABASE TestLogImpact TO DISK = 'C:\Temp\TestLogImpact_full.bak' WITH INIT; GO
Step 2: Measuring Log Generation Without INCLUDE
I backed up the log to reset it before testing.
BACKUP LOG TestLogImpact TO DISK = 'C:\Temp\log_before_noinclude.trn' WITH INIT; GO
Then I created a nonclustered index without any INCLUDE columns.
CREATE NONCLUSTERED INDEX IX_CustomerID ON Orders (CustomerID); GO
I ran an update modifying Quantity values for customers between 100 and 900.
UPDATE Orders SET Quantity = Quantity + 1 WHERE CustomerID BETWEEN 100 AND 900; GO
Finally, I backed up the log after the update.
BACKUP LOG TestLogImpact TO DISK = 'C:\Temp\log_after_noinclude.trn' WITH INIT; GO
Step 3: Measuring Log Generation With INCLUDE
Next, I dropped the previous index and recreated it with INCLUDE columns covering almost all other wide columns.
DROP INDEX IX_CustomerID ON Orders; GO CREATE NONCLUSTERED INDEX IX_CustomerID_INCLUDE ON Orders (CustomerID) INCLUDE (OrderDate, ShipDate, Quantity, Price, Status, Comments, Region, CreatedBy, UpdatedBy, Extra1, Extra2, Extra3, Extra4, Extra5); GO
I backed up the log to reset it again.
BACKUP LOG TestLogImpact TO DISK = 'C:\Temp\log_before_include_update.trn' WITH INIT; GO
Then I ran the same update as before.
UPDATE Orders SET Quantity = Quantity + 1 WHERE CustomerID BETWEEN 100 AND 900; GO
Finally, I took a log backup after this update.
BACKUP LOG TestLogImpact TO DISK = 'C:\Temp\log_after_include.trn' WITH INIT; GO
Results: The Surprising Truth
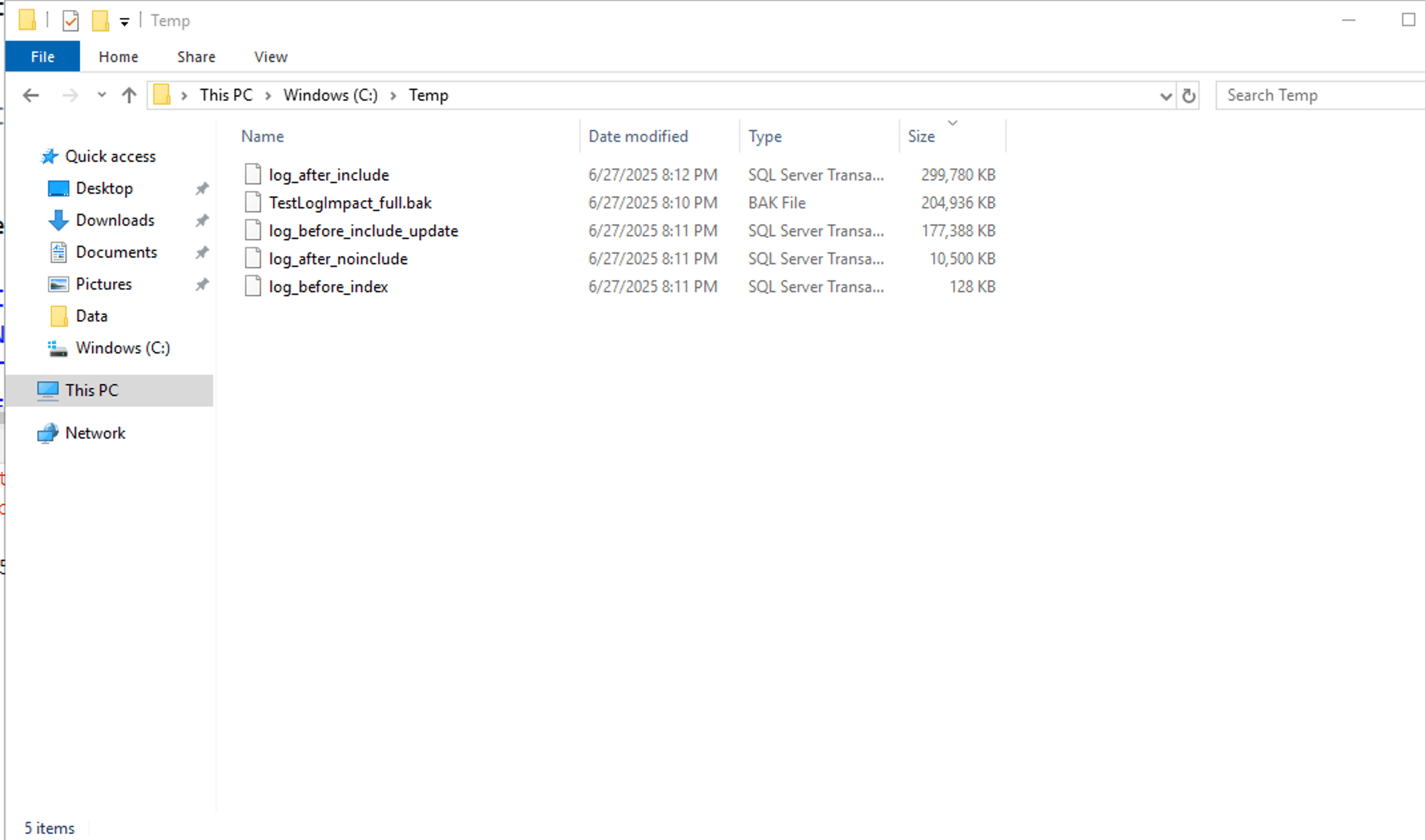
Before discussing the result lets summarise the backup size in below table(Refer Image):
| File Name | Size (KB) | Approx Size (MB) |
|---|---|---|
| TestLogImpact_full.bak | 204,936 KB | ~200 MB |
| log_before_index.trn | 128 KB | ~0.12 MB |
| log_after_noinclude.trn | 10,500 KB | ~10 MB |
| log_before_include_update.tn | 177,388 KB | ~173 MB |
| log_after_include.trn | 299,780 KB | ~293 MB |
When I ran the update on the Orders table with just a simple nonclustered index without INCLUDE columns, the transaction log backup size was around 10 MB, as seen in log_after_noinclude.trn. That felt normal – the update touched many rows but the log backup was still within expected size for a table of this width and row count.
But when I ran the exact same update after creating a nonclustered index with INCLUDE columns covering almost every wide VARCHAR column in the table, the log backup size wasn’t just a bit bigger – it shot up to nearly 300 MB, as seen in log_after_include.trn. This means the same update generated around 30 times more transaction log volume just because the index contained those INCLUDE columns.
To be honest, I knew INCLUDE columns increase index size and can slightly increase log generation because of wider rows. But I did not expect a 10 MB update to become a 300 MB update purely due to INCLUDE usage. This isn’t about a few extra MBs you can ignore – it’s the difference between a smooth replication pipeline and one that lags badly because your log backups are hundreds of MB larger every hour.
It’s also worth noticing log_before_include_update.trn. This log backup was taken right after I created the nonclustered index with the INCLUDE columns – no data update had even happened yet. Just creating the index itself generated around 173 MB of transaction log, purely because the index included so many wide columns. That alone shows how heavy INCLUDE columns can be, even before your first update runs against them.
These results show why we cannot treat INCLUDE columns as harmless. They physically reside in index leaf rows, and any update that touches indexed data writes wider log records when INCLUDE columns are present. In environments with frequent updates and DR replication, this silent log bloat can directly impact backup storage, restore times, network costs, and RTO compliance.
 INCLUDE index updates generated much larger logs.
INCLUDE index updates generated much larger logs.Why Does This Happen?
INCLUDE columns are physically stored in the index leaf rows. When you update a column covered by the index, SQL Server writes log records reflecting the before and after images of the affected parts of the index row. Wider INCLUDE columns translate directly into wider log records.
I also tested updating only INCLUDE columns versus key columns. Updating key columns causes row movement in the index, logged as a delete and insert of the entire index row, including INCLUDE columns. This generates the maximum possible log volume. Updating only an INCLUDE column doesn’t cause row movement, but it still logs the INCLUDE value change within the index row, generating more log than if the column wasn’t included at all. In short, key column updates are worse, but INCLUDE updates aren’t free.
The Hidden Business Cost
When we think about creating or modifying indexes – especially when adding INCLUDE columns – our focus is usually on query performance. Will it speed up a SELECT? Will it reduce key lookups? But rarely do we pause to consider the ripple effects on the business side of operations.
In production environments that rely on log shipping or AlwaysOn availability groups, these changes can carry a hidden price tag. Every large update or index modification generates transaction log records. The larger the log records, the bigger the log backups. For log shipping, this means the secondary server now has to restore bigger log backup files, increasing replication lag. Your DR site that was just a few seconds behind could now be minutes behind, exposing the business to data loss risks during failovers.
Similarly, in AlwaysOn availability groups, larger transaction logs mean more data to synchronise between replicas. If your network bandwidth or replica performance cannot keep up, the secondary replicas begin to lag. For business-critical systems, this directly translates into longer failover times, breaching RTO/RPO SLAs silently.
Beyond performance and availability, there’s a pure cost dimension. Backup storage isn’t free. When every log backup is inflated with unnecessary changes – often INCLUDE column updates that were never even queried – your backup size, storage bills, and even retention management complexity multiply quietly in the background.
In essence, an index meant to optimise one slow query can end up silently choking your HA/DR pipelines, increasing your backup storage bills, and delaying recovery times during critical incidents. That is why index design decisions should never be taken in isolation – their impact on the broader operational ecosystem must be evaluated with equal diligence.
Conclusion
INCLUDE is a powerful tool, but it isn’t a free lunch. Before adding wide INCLUDE columns to cover your reporting queries, we need ask urself: Is this coverage worth the hidden cost in transaction log generation, replication bandwidth, and RTO compliance?
Sometimes, the performance tuning choices we make echo far beyond our immediate query – and INCLUDE columns are one of those choices.
