

In Part I of this series, we discussed the basics of Peer-to-Peer Transactional Replication ("PPTR" for short), including when one would use PPTR, and considerations involved in the topology. In this part, we will set up an actual PPTR topology, and add, insert and delete rows to show what happens. Then I will explain why.
How to Set up PPTR
These instructions assume that you have two identical databases one one server. PPTR will, however, work equally well if the databases are on the same or different servers. This example will give instructions as needed to implement on more than one server.
Each server using PPTR must run SQL 2005 or newer Enterprise edition (PPTR isn't available on lower editions). Our example is built with SQL 2008 Enterprise edition.
In our example, we have one table named foobar. It is replicated between databases Tinker and Tinker2. Our example uses the same server for both databases.
The table:
CREATE TABLE [dbo].[foobar]( [foobar_npk_1] [int] NOT NULL ,[foobar_npk_2] [int] NOT NULL ,[foobar_data] [varchar](100) NOT NULL ,[foobar_id] [int] IDENTITY(1,1) NOT NULL, CONSTRAINT [PK_Foobar] PRIMARY KEY NONCLUSTERED ( [foobar_npk_1] ASC ,[foobar_npk_2] ASC ) WITH ( PAD_INDEX = OFF ,STATISTICS_NORECOMPUTE = OFF ,IGNORE_DUP_KEY = OFF ,ALLOW_ROW_LOCKS = ON ,ALLOW_PAGE_LOCKS = ON ) ON [PRIMARY] ) ON [PRIMARY]; GO
Uniqueness across all Nodes: Required.
The Foobar table clustered index is shown below. In Part I, I stressed the importance of inserted rows in any article table in any database being unique across all databases in the topology. Here is how we achieve that when your rows are clustered on an unique identity: In our case, we are clustering on foobar_id, which is an identity column.
The natural primary key is foobar_npk_1 and foobar_npk_2. Non-identity natural keys must be managed to be unique across all database nodes. If you insert the same natural primary key in two or more nodes, a conflict will arise.
CREATE UNIQUE CLUSTERED INDEX [IXC_FOOBAR_ID] ON [dbo].[foobar] ( [foobar_id] ASC ) WITH ( PAD_INDEX = OFF ,STATISTICS_NORECOMPUTE = OFF ,SORT_IN_TEMPDB = OFF ,IGNORE_DUP_KEY = OFF ,DROP_EXISTING = OFF ,ONLINE = OFF ,ALLOW_ROW_LOCKS = ON ,ALLOW_PAGE_LOCKS = ON ) ON [PRIMARY]; GO
Next up, we need to assign a different range of identities in the Tinker2 database, and we do that as follows:
-- Run this in Tinker2 *ONLY*
DBCC CHECKIDENT('foobar',RESEED,100000);
GO
In our example, we set the first identity in Tinker2 at 100,000, so that the table inserts in database Tinker do not clash with the inserts in the database Tinker2.
Now, we can set up Replication and PPTR.
Setting up Peer-to-Peer Replication
First, you need to configure distribution on the server. It is easily done in Management Studio, or with a script like this (I generated this script with Management Studio):
use master
exec sp_adddistributor @distributor = N'TESTSERVER', @password = N''
GO
exec sp_adddistributiondb
@database = N'distribution',
@data_folder = N'C:\SQLDB',
@log_folder = N'C:\SQLDB',
@log_file_size = 2,
@min_distretention = 0,
@max_distretention = 72,
@history_retention = 48,
@security_mode = 1
GO
use [distribution]
if (not exists (select * from sysobjects where name = 'UIProperties' and type = 'U ')) create table UIProperties(id int)
if (exists (select * from ::fn_listextendedproperty('SnapshotFolder', 'user', 'dbo', 'table', 'UIProperties', null, null)))
EXEC sp_updateextendedproperty N'SnapshotFolder', N'c:\sqldb\snap', 'user', dbo, 'table', 'UIProperties'
else
EXEC sp_addextendedproperty N'SnapshotFolder', N'c:\sqldb\snap', 'user', dbo, 'table', 'UIProperties'
GO
exec sp_adddistpublisher @publisher = N'TESTSERVER', @distribution_db = N'distribution', @security_mode = 1, @working_directory = N'c:\sqldb\snap', @trusted = N'false', @thirdparty_flag = 0, @publisher_type = N'MSSQLSERVER'
GOAfter that, you can create the Peer-To-Peer replication topology. Choose Tinker 1 Database in the New Publication Wizard and click Next:
You then choose a peer-to-peer topology:
Choose the tables to publish. Remember that the table must already exist in every node, with identical schema and data.
You are then asked for security for the Log Reader Agent, if one is not already installed for another publication from that database (I am being naughty here and using the SQL Server agent account; that is a security vulnerability in production).
You then choose to create the publication and or generate a script. I prefer to generate a script, but for this example, we'll go straight to creation:
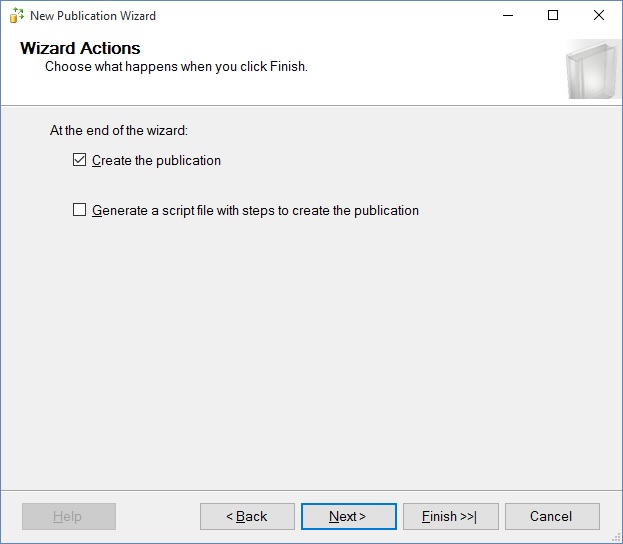
And we arrive at the final step of this wizard. Name the PPTR publication and choose to Finish.
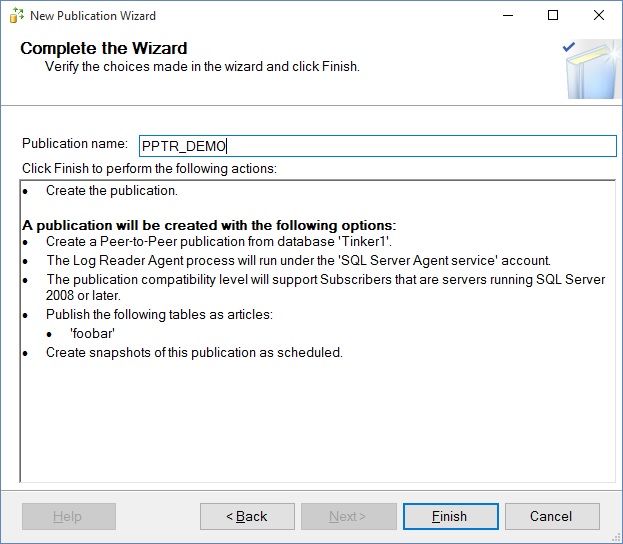
And then we get a publication!
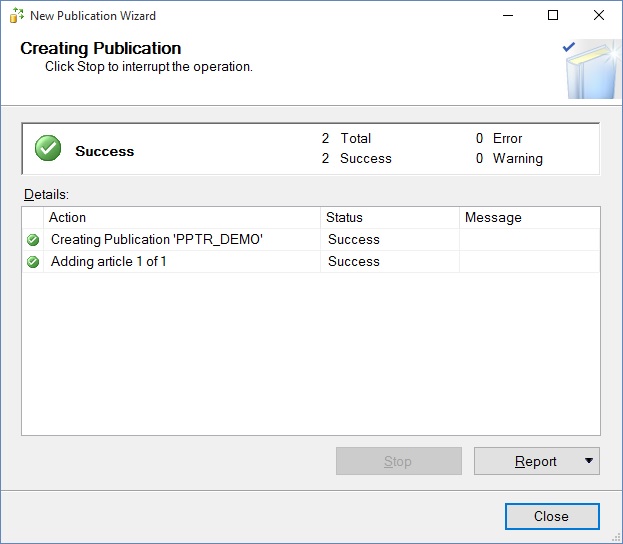
Now we have a publication with no other nodes. Time to move on to adding nodes. In Management Studio, we can see the publication:
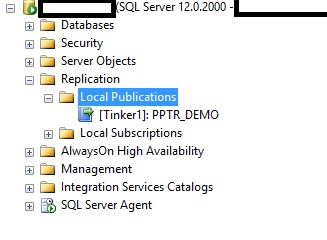
Right click the publication and choose Configure Peer-to-peer topology.
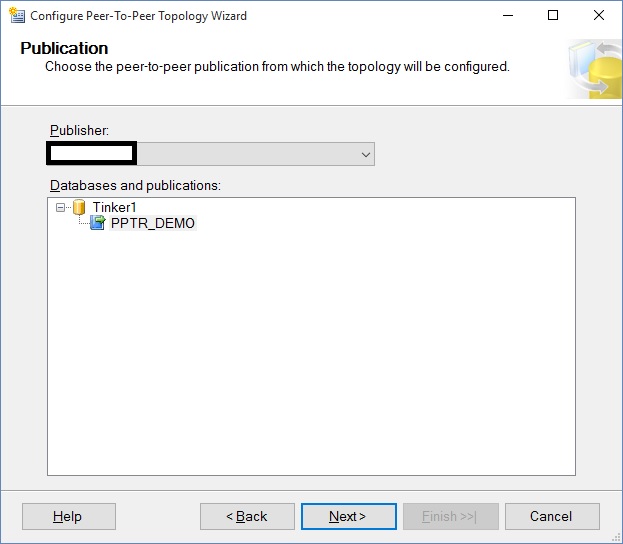
Highlight the PPTR publication and click Next. At that point you will see this rather cryptic window:
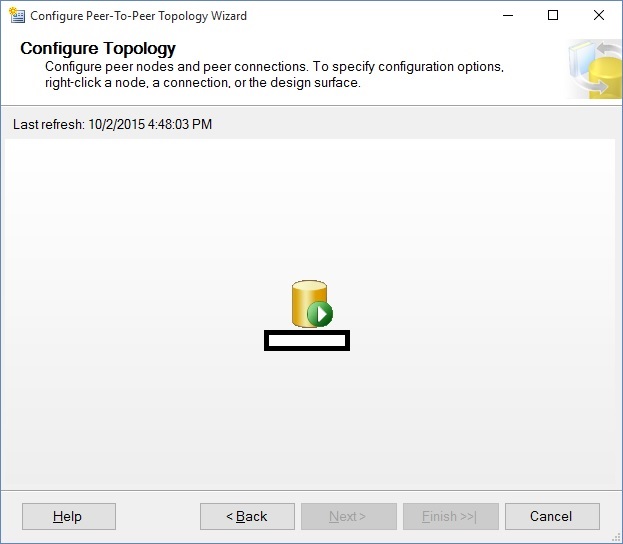
I've cleared out the server name for security purposes, but that is what appears under the icon.
You then right-click on the empty area to add a database to the topology:
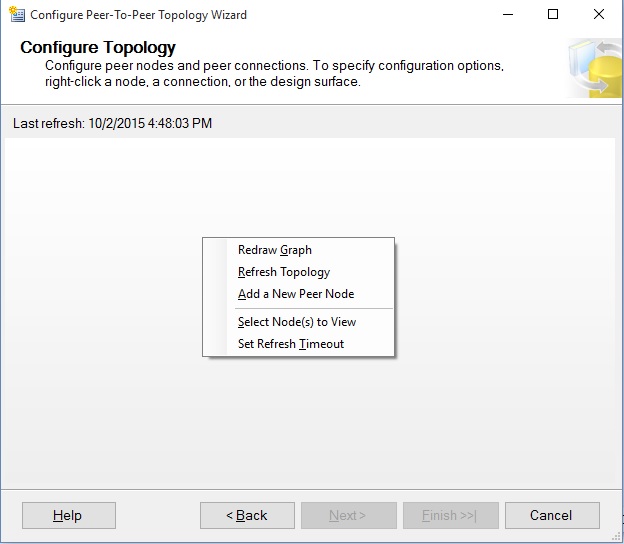
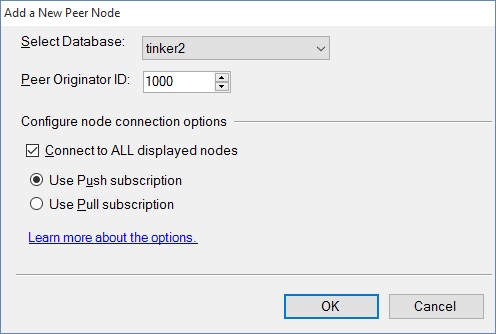
Choose the "Add a New Peer Node option.you will get a connection window, connect to the server hosting the database that is joining the topology. This can be the same as the server on which the database runs. You will get this window to ask for the peer database on that server: You also have to choose the Peer originator ID. this is important to resolving conflicts. The node with the highest number wins conflicts. And, unfortunately, someone has to win - no ties allowed.
You should also choose to collect to all displayed nodes, every time. I know of no valid reason to have a partially-connected node, because data integrity would be bupkus.
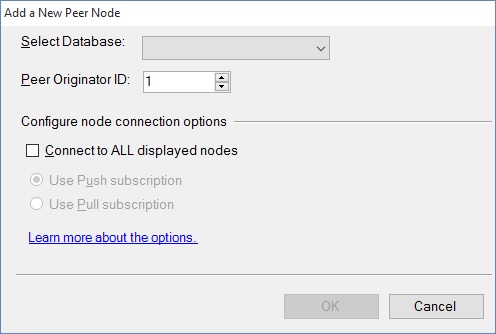
Here's what I set up:
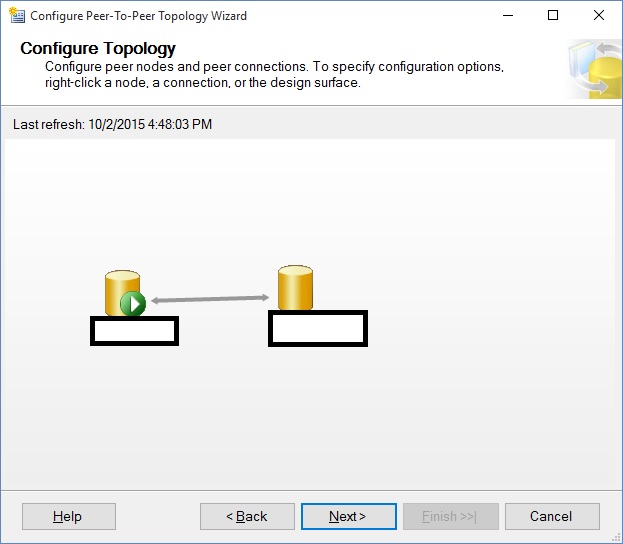
You then get a screen with two nodes on it. Keep on doing this for all of the peers.
When you have all of the peers included, click Next. You then need to set Log Reader security for the all of the new peernodes, which will be listed on the window that I snapshotted below (Please note that I again used the process account of the agent, a no-no in production, in order to expedite this presentation).
This is what you will see:
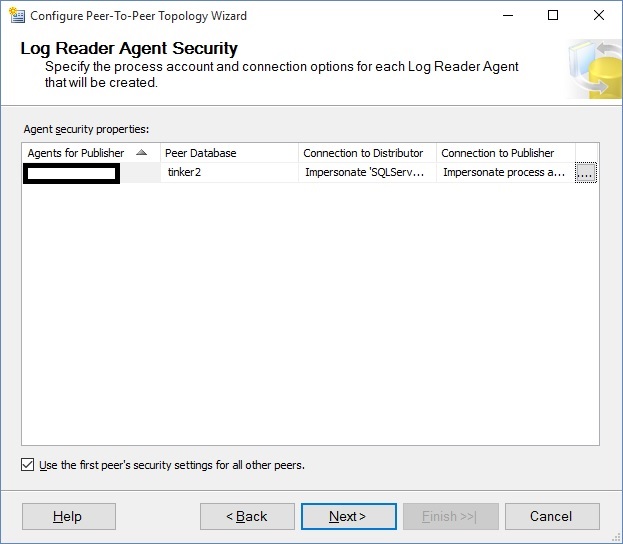
You can speed things up when there are meny peers by checking the "Use the First peer's security settings for all other peers" before choosing the settings for the first peer.
Clicking next will bring up a similar window for Distribution agent security:
Click Next.
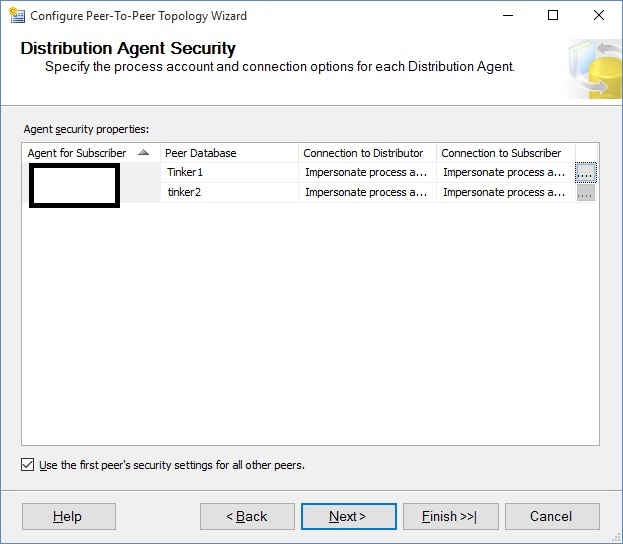
Again, choose the security and click next. Now, you will be asked the $64,000 question: Did you keep the data identical? But the way it actually looks is like this:
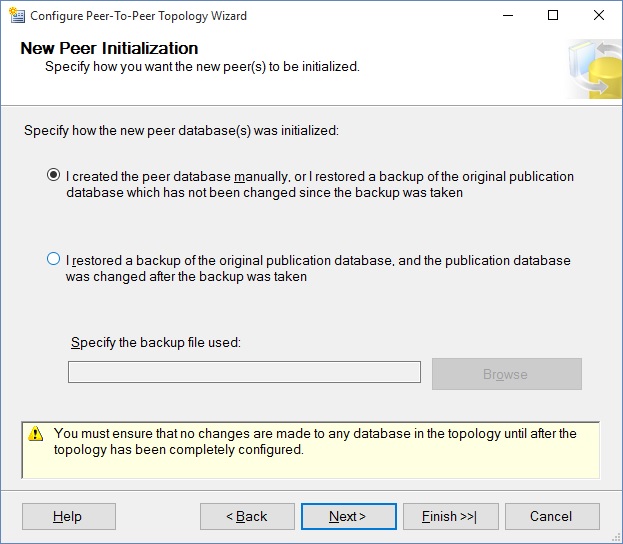
If the first statement is not true, I recommend that you do not start PPTR. If the publication database has changed, it wants a backup file for comparison purposes; I've never seen this approach used successfully anywhere.
In short, make sure that every table that is part of PPTR is identical in schema and data prior to setting up PPTR, and make equally sure that the databases are quiesced before beginning this adventure!
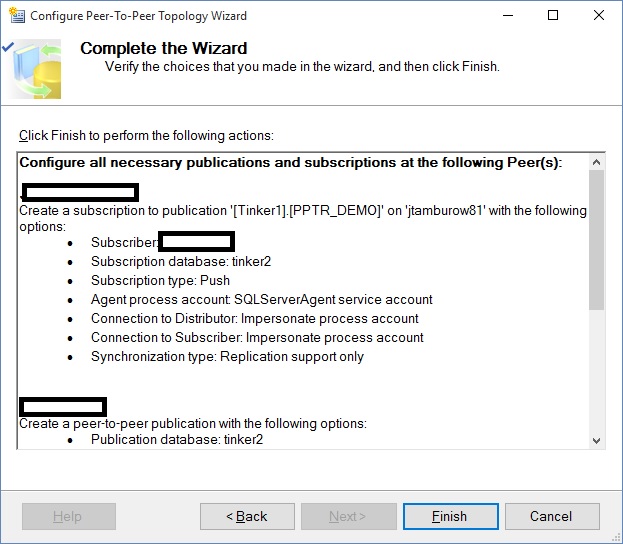
Now we come to the penultimate screen: The Completion screen, where SQL Server gives you a summary of what it will do:
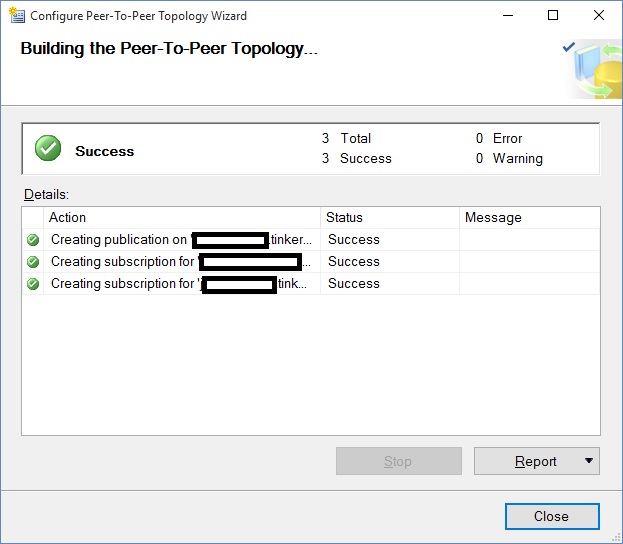
Now, we click next and the magic happens!
PPTR is now up and running. We can see it in Management Studio:
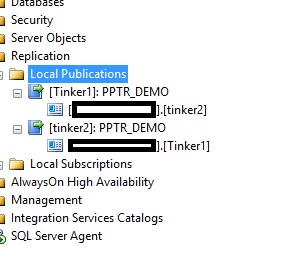
Now it is time to prove it out...
Adding rows to each node.
First, let's add some data to foober in Tinker1. I inserted 1000 rows of data into Tinker1.
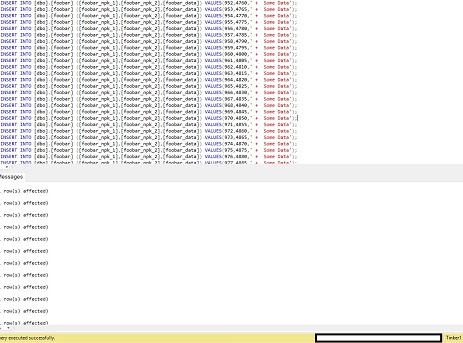
And we see that the 1000 rows exist in Tinker2:
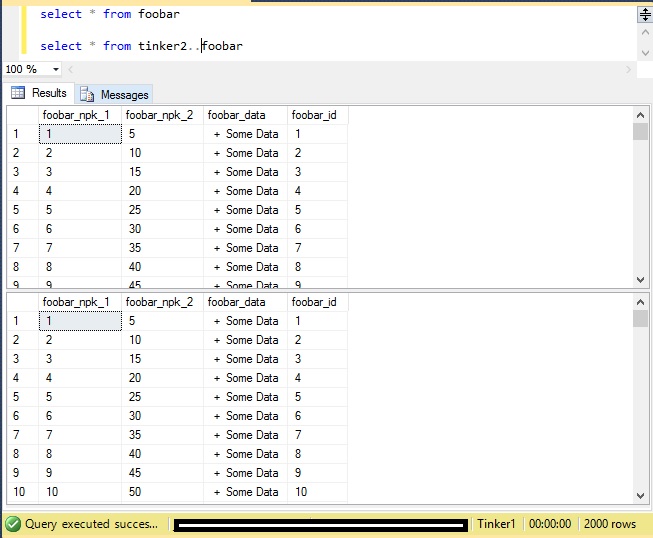
So now, let's add the same rows into Tinker2:
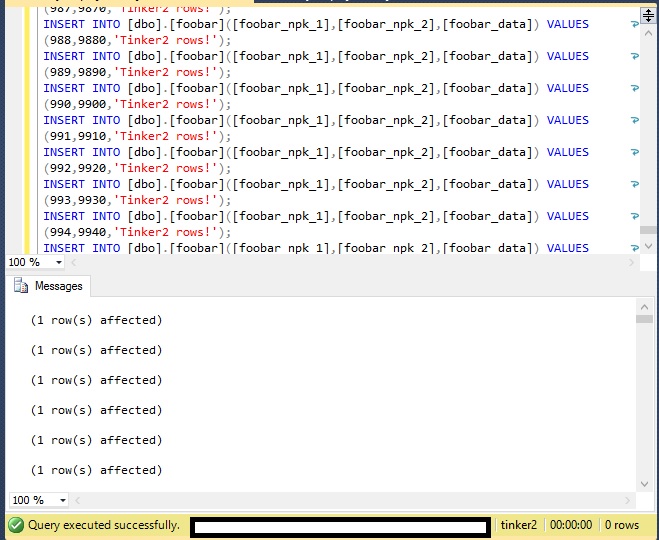
Now, let's query Tinker1 and Tinker2:
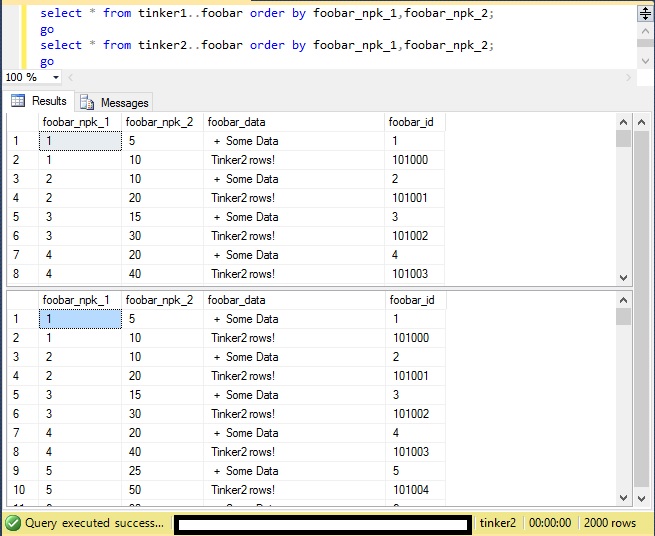
As you can see, both nodes have the data. Tinker2 received the rows inserted into tinker1 and vice versa. As long as the actual primary key (and all other unique indexes or constraints) is unique to both nodes, you will have no problems at all with inserting, updating or deleting rows.
Now we have deployed PPTR and added rows to both nodes. We have demonstrated that PPTR will work.
In the next article, we will discuss stability and troubleshooting. There are some tips and tricks that will make peer-to-peer replication easy to maintain. I've learned the the hard way, with all-nighters on weekends with angry vice-presidents on the conference bridge. Hopefully, if you have the need to PPTR, what I share will help you have an easy time to implement.
----
John F. Tamburo is the Chief Database Administrator for Landauer, Inc., the world's leading authority on radiation measurement, physics and education. John can be found at @SQLBlimp on Twitter. John also blogs at www.sqlblimp.com.
