In previous articles, we've looked at the basics of Dynamic Data Masking (DDM) in SQL Server 2016 as well as the behavior of the default mask with various data types. Now we will look at the other types of data masking options available to us. We will not examine the behavior of every data type for each mask. However we will look at the behavior of many how we might expect the various masks to work.
This article will examine the three masks coming in SQL Server 2016 outside of the default data mask. These are the
- random
- custom string (or pattern)
Each of these is documented in Books Online, but we will take a more in depth look at how these masks actually function in our application code.
The Email Mask
Let's start with the email mask. This is one of the more common patterns that applications often mask. In this case, the email mask is built in and results in a mask that work as follows:
- the first letter of the data (the email address)
- a series of xx's before the @ symbol.
- a series of x's for the domain and subdomain(s)
- a .com at the end.
That seems reasonable. Let's see how this works in practice. I'll create a table and add some data. Note that this mask uses the word email, with open and close parenthesis. No parameters are used in the SQL Server 2016 version.
CREATE TABLE Contacts
( ContactID INT
, ContactName VARCHAR(200)
, ContactEmail VARCHAR(300) MASKED WITH (FUNCTION='email()')
)
GO
INSERT dbo.Contacts
( ContactID, ContactName, ContactEmail )
VALUES
( 1, 'Steve', 'steve.jones@sqlservercentral.com')
, ( 2, 'Andy', 'andy.warren@sqlshare.com')
, ( 3, 'Kendall', 'kendall@volleyball.rec')
, ( 4, 'Delaney', 'dj@knowledgebowl.co.us.edu')
, ( 5, 'Kyle', 'k@live.com')
GO
SELECT
*
FROM dbo.Contacts AS c
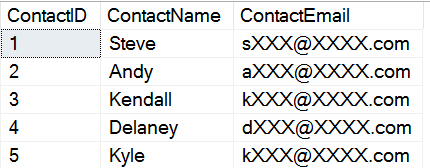
As you can see, I've got a variety of data, of different sizes and shapes for the masked field.
Now let's see this data masked from a user. I've granted SELECT rights to a normal user, and view the data.
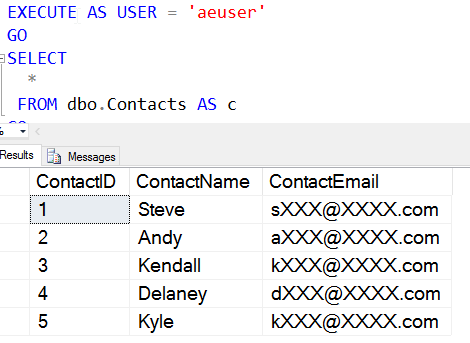
As you can see, I get a consistent mask. The size, length, format, etc. of the data is irrelevent. I always get a one character beginning to the email, a set of 3 Xs, the @ symbol, 4 Xs, and then ".com." Even if I have other domains, or multiple subdomains, the mask is consistent and doesn't reveal other domains.
Let's now add some other data and see how this affects the mask. I'll add some malformed domains and problem emails.
INSERT dbo.Contacts
( ContactID, ContactName, ContactEmail )
VALUES
( 6, 'Allen', 'allen.com')
, ( 7, 'Dean', null)
, ( 8,'Uma', 'dog.org')
, ( 9, 'Deuce', 'DeucesAreWild')
, ( 10, 'Oscar', 'grouch@')
GO
I'll query the data in the same way, with my AEUser, normal user. From here, I now see this data:
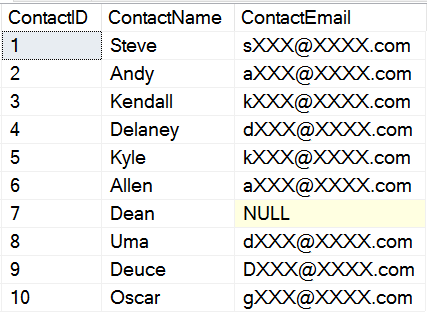
Hmm, this is interesting. It doesn't matter how my data is formed. Only the NULL reveals there is NULL data in that field. I think I'd prefer that this be "nxxx@xxxx.com", but that's me. I prefer to try and minimize data leakage as much as possible.
However other than that, I can see that even my malformed emails, for "dog.com" and "grouch@" are properly masked. The email mask is limited to:
- char
- nchar
- varchar (including max)
- nvarchar (including max)
- text
- ntext
I did find that this mask isn't supported on:
- int/tinyint/smallint/bigint
- datetime
- float/real
- sql_variant
- hierarchyid
- xml
- geography/geometry
This isn't surprising. After all, the email mask is built for strings, which means that only the string datatypes make sense. If you atttempt to mask any of the other types with the email mask, you receive an error on table create/alter.
The Random Mask
The random mask is designed for use with numeric types. The idea is that a random number is used to replace the existing data with something else. The RANDOM mask takes two parameters, which are the start and end of the range. Despite being in brackets in BOL, these are required. The format is shown below.
Let's run some tests here. We will create a new table here:
CREATE TABLE emailtest
( myemail int MASKED WITH (FUNCTION='random(1, 10)')
)
GO
INSERT dbo.emailtest
( myemail )
VALUES
( 100), (200), (300)
GO
Now let's run some queries. I'll use the same user, with SELECT rights to the table.
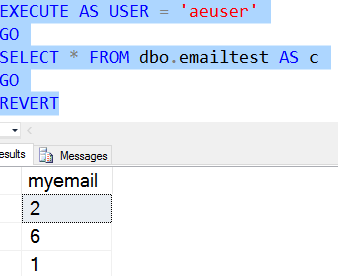
I ran this mutliple times, but here are 3 consecutive executions.



As you can see, the same query returns new data each time. None of this data remotely resembles the data in the table. What if I put in data that is inside of the random mask? Let's try that. I'll drop the table and add new data.
CREATE TABLE emailtest
( myemail int MASKED WITH (FUNCTION='random(1, 5)')
)
GO
INSERT dbo.emailtest
( myemail )
VALUES
( 1), (2), (3)
Now we query and see this:

As we can see, some of the random data isn't in the table, but this is returned. This is a good thing.
Do I need the range? Let's try that and see.
CREATE TABLE emailtest ( myemail tinyint MASKED WITH (FUNCTION='random()') )
I do need the range, as I get this error:
Msg 16004, Level 16, State 0, Line 52Incorrect number of parameters for data masking function 'random' for column 'myemail'.In terms of data types, only numeric types are supported. If I choose a type like numeric or float, I get values that fit in those types. As I can show here:

If I run this multiple times, I get a variety of values.
The string types (char, nchar, varchar, nvarchar), despite having implicit conversions, do not work here. These data types are not supported:
- strings - char, nchar, varchar, nvarchar
- dates - date, time, datetime, datetime2, datetimeoffset
- sql_variant
- xml
- hierarchy id
- geography/geometry
There is more to look at here, but I'll save some of this for another article that examines the various DDL you can use with Dynamic Data Masking.
The Custom String Mask
The last mask we have in SQL Server 2016 is the Custom mask. I'm not sure why this is named Custom String when the function is "partial", but that's the chocie that was made. Here we specify the function as:
partial(prefix, [padding], suffix)
The way we read this is that we expose the first few letters of the data, based on the value of prefix. Prefix needs to be a number. The same thing for suffix, where the last characters are exposed. If the original value is too short, the prefix/suffix are not exposed.
The middle value is the actual mask to use. This is a string, so let's look at how this might duplicate our email table. Note that this value is enclosed in double quotes.
In this case, we only expose 1 character of the prefix, 4 of the suffix, and a "xxx.xxx" in between. Here's the DDL and insert.
CREATE TABLE Contacts
( ContactID INT
, ContactName VARCHAR(200)
, ContactEmail VARCHAR(300) MASKED WITH (FUNCTION='partial(1, "xxx.xxx", 4)')
)
GO
INSERT dbo.Contacts
( ContactID, ContactName, ContactEmail )
VALUES
( 1, 'Steve', 'steve.jones@sqlservercentral.com')
, ( 2, 'Andy', 'andy.warren@sqlshare.com')
, ( 3, 'Kendall', 'kendall@volleyball.rec')
, ( 4, 'Delaney', 'dj@knowledgebowl.co.us.edu')
, ( 5, 'Kyle', 'k@live.com')
GO
Now the query by our normal user.
As we can see, this is a more realistic masking of the actual data, which could be useful in situations where the user needs to see a portion, but a very limited portion of data. In this case, the domain is returned. However we get some strangeness if I include the malformed data from the email mask section. In this case, I'll see:
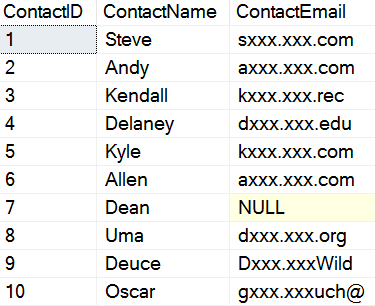
This may not be what we want, and this doesn't make much sense. We also have some data leakage here.
In terms of data type support, this looks like the email() mask. Only string types are supported.
There is much more to cover here with the Custom String mask, and it deserves its own article, like the default mask. Coming soon.
Conclusion
We examined the other three masks, Email, random, and Custom String. Two of these are built for string types, and one for numeric types. Neither support dates or the other specialized types. These are limitations,but since the default mask supports most types, we can mask data if needed.
I expect the types of functions and masking to grow over time, potentially even allowing us to write SQLCLR masks, maybe User Defined Data Masks (UDDM) at some point. In any case, this is a good addition to SQL Server and a nice set of functions to use.
Once again, remember this isn't a security function, and there could be data leakage. Treat this as an application programming convenience feature that simplifies the masking process in development, but doesn't really protect data if users can issue ad hoc queries. We will look at some of the vulnerabilities in a later article.