
We’ve had views available to us in SQL Server and other database platforms for a number of years now. U-SQL strives to be as compatible as possible (to a point) with the T-SQL objects you’ve become used to over the years, and views are no exception.
In this step of the U-SQL Stairway series, we’ll investigate how to put views together in U-SQL, how they differ from their T-SQL counterparts, and how U-SQL uses them. I’ll try to avoid bad puns (“room with a view”, “it’s a lovely view” etc) as we go!
An Important Note: At the time of writing (August 2016), there is a bug in the local implementation of U-SQL which prevents you from querying a view written using SELECT statement syntax. A view containing the EXTRACT statement works fine. You’ll only have problems if you try to run against your local account, so if you want to follow along make sure you run the scripts in your Azure cloud. (UPDATE February 2017 - This issue has been resolved, you can now query views locally as well as in Azure)
What is a View?
For the uninitiated, a view looks and acts like a table. You can use it in your queries, you can join to it and you can filter it. But a view is actually nothing more than a query, which is executed behind the scenes whenever you request data from the view. Views are great because they can encapsulate logic which makes queries easy to read. In the UkPostcodes database we’ve been using throughout this series, we have three tables we constantly join together – Postcodes, Counties and Districts. Think how much simpler life would be if we had a view which already joined those tables together for us. Good news – life is about to become simpler!
Creating a View
The syntax of the U-SQL CREATE VIEW statement will look pretty familiar to anybody who’s used the equivalent T-SQL command:
CREATE VIEW IF NOT EXISTS DatabaseName.SchemaName.ViewName AS Query
The only optional components are the IF NOT EXISTS clause (if you don’t specify this and the view exists, an error will be raised) and the database and schema names (you can use the USE statement to specify these instead, or the view will be created within your current context if you don’t specify them).
Altering and Dropping Views
You cannot alter a view – if you want to modify a view you need to drop it first, then run the CREATE VIEW statement again. Dropping the view is pretty simple:
DROP VIEW IF EXISTS ViewName;
Creating a View for Real
We’re going to create a view to return a flat set of postcode details. Open up the Visual Studio project we’ve been using and create a new file called 300 Create PostcodeDetails View.usql. Type or paste the code below:
USE DATABASE UkPostcodes;
USE SCHEMA Postcodes;
DROP VIEW IF EXISTS PostcodeDetailsView;
CREATE VIEW IF NOT EXISTS PostcodeDetailsView
AS
SELECT p.Postcode, c.CountyName
FROM Postcodes AS p
LEFT JOIN Counties AS c ON p.CountyCode == c.CountyCode;
We have a simple join, which does nothing more than return the postcode and county name (we’ll bring districts into play later). Note the use of LEFT JOIN, which we introduced in article 8 (refer back for more details). We also have the semi-colon present – all U-SQL statements terminate with it, remember!
Using the U-SQL toolbar (at the top of the script), select your Azure account (go back to article 4 if you need a refresher). Once that’s done, run the script by hitting the Submit button on the toolbar. Everything should be sweetness and light:
Success! We now have a view ready to go, albeit a simple one. Add another new script to the project, calling it 310 Select From PostcodeDetails View.usql. Add this code and execute it (again, don’t forget to select your Azure account if you're using a pre-February 2017 version of the Data Lake tools).
USE DATABASE UkPostcodes; USE SCHEMA Postcodes; @pd = SELECT p.Postcode, p.CountyName FROM PostcodeDetailsView AS p; OUTPUT @pd TO "/outputs/pcodedetails.csv" USING Outputters.Csv();
This returns all postcodes, along with the corresponding county names (if available). As you can see, this is no different to using a table.

Using Views in Joins
We can use a view to join to other tables. I mentioned the Districts table at the top of the article. We can join the view to this table, although we’ll have to go through the Postcodes table too. Amend script 310 so it looks like this:
USE DATABASE UkPostcodes;
USE SCHEMA Postcodes;
@pd =
SELECT p.Postcode, p.CountyName, d.DistrictName
FROM PostcodeDetailsView AS p
INNER JOIN Postcodes AS po ON p.Postcode == po.Postcode
INNER JOIN Districts AS d ON po.DistrictCode == d.DistrictCode;
OUTPUT @pd TO "/outputs/pcodedetails.csv" USING Outputters.Csv();
This returns the expected information:
It’s a horrible query though. The view already references the Postcodes table, so we shouldn’t need to refer to it again. It would be much better if the district name was returned as part of the view. Not a problem. Open up script 300 again and change the code to this:
USE DATABASE UkPostcodes; USE SCHEMA Postcodes; DROP VIEW IF EXISTS PostcodeDetailsView; CREATE VIEW IF NOT EXISTS PostcodeDetailsView AS SELECT p.Postcode, c.CountyName, d.DistrictName FROM Postcodes AS p LEFT JOIN Counties AS c ON p.CountyCode == c.CountyCode LEFT JOIN Districts AS d ON p.DistrictCode == d.DistrictCode;
Run this to update the view. Now change script 310 to look like this:
USE DATABASE UkPostcodes;
USE SCHEMA Postcodes;
@pd =
SELECT p.Postcode, p.CountyName, p.DistrictName
FROM PostcodeDetailsView AS p;
OUTPUT @pd TO "/outputs/pcodedetails.csv" USING Outputters.Csv();
This is much simpler. Execute that script and open the output file. You’ll see the same results as seen earlier using the joins, but we’ve now nicely encapsulated that logic in the view. What a result!
Using Views to Hide Complexity
So far, so good. Of course, we haven’t really done anything particularly astonishing thus far. All we’ve done is hide a pretty simple join query. Whilst this gives us some good reuse, the query could easily be written by any half-decent U-SQL developer as part of a larger script, maybe by assigning its results to a rowset or using the script as a sub-query.
No, views really come into their own when we use them to make the complex appear simple. Pop back to script 300, which contains the view definition. We’re going to amend the view so it returns the two parts of the postcode as separate columns, using the space as a separator. Here’s the code:
USE DATABASE UkPostcodes;
USE SCHEMA Postcodes;
DROP VIEW IF EXISTS PostcodeDetailsView;
CREATE VIEW IF NOT EXISTS PostcodeDetailsView
AS
SELECT p.Postcode,
p.Postcode.Substring(0, p.Postcode.IndexOf(" ")) AS Part1,
p.Postcode.Substring(p.Postcode.IndexOf(" ") + 1) AS Part2,
c.CountyName,
d.DistrictName
FROM Postcodes AS p
LEFT JOIN Counties AS c ON p.CountyCode == c.CountyCode
LEFT JOIN Districts AS d ON p.DistrictCode == d.DistrictCode;
This is interesting. The new lines we’ve added are not your normal common or garden columns:
p.Postcode.Substring(0, p.Postcode.IndexOf(" ")) AS Part1,
p.Postcode.Substring(p.Postcode.IndexOf(" ") + 1) AS Part2,
We’re using the expressive power of the C# language here to split up the postcode, by using a space. For the postcode “W22 1PP”, for instance, we’d receive the following values back:
- Part 1: W22
- Part 2: 1PP
Splitting data in this way could really help with statistics – for instance, we may be asked to return the number of householders in a particular postcode area. We could use Part 1 of the postcode to help us do that.
Execute the CREATE VIEW script and then return to script 310, which we’ll amend slightly to return the Part1 and Part2 columns:
USE DATABASE UkPostcodes;
USE SCHEMA Postcodes;
@pd =
SELECT p.Postcode, p.Part1, p.Part2, p.CountyName, p.DistrictName
FROM PostcodeDetailsView AS p;
OUTPUT @pd TO "/outputs/pcodedetails.csv" USING Outputters.Csv();
Execute this…and everything blows up! We hit a runtime error:
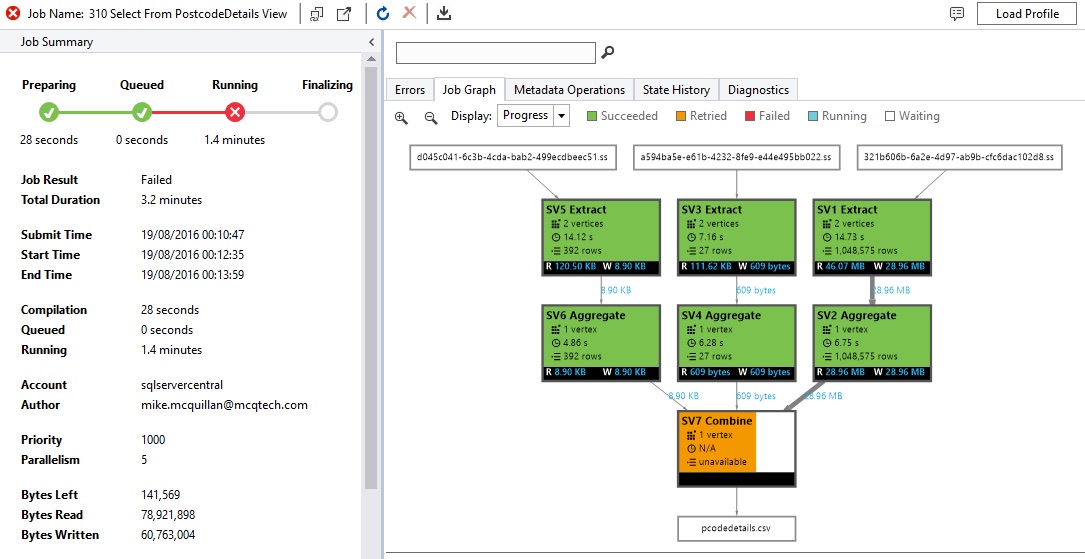
What the heck does this mean? Careful investigation reveals our data is the source of the issue. If you click on the Error tab, the full reason is revealed – not all of the postcodes in our data set contain a space:
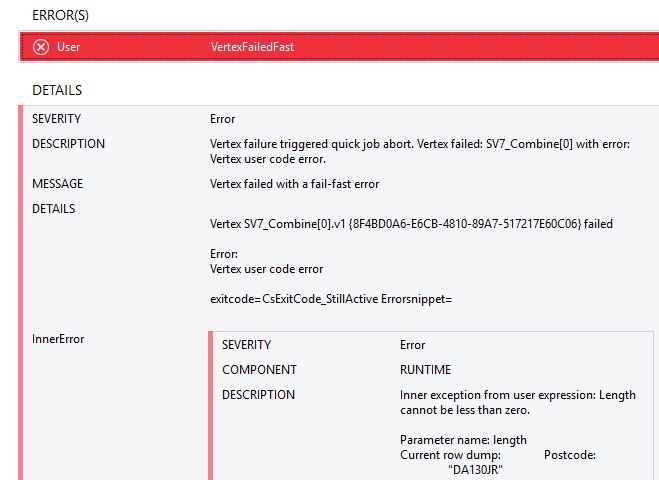
Consequently, when U-SQL hits a postcode value without a space, it cannot calculate the IndexOf position – so the method returns -1 to denote no index was found. But we’re using IndexOf to tell the Substring method how long the string is it should fetch. 0 to -1 is not a valid length, hence the “length cannot be less than zero” error.
Fortunately, we can amend our view so it will correctly return data for postcodes with a space in them, whilst ignoring the postcodes without a space. In an ideal world, we’d modify the data to give it consistency, but this fix gives us the benefit of a “belt and braces” approach, ensuring the query won’t explode into balls of flames should some incorrectly formatted data be present.
So, what is this magical way to fix this problem, I hear you ask? My friends, I give you…the conditional operator!
The Conditional Operator
If you’ve ever used the IIF statement, a CASE statement or a SWITCH statement in any language, you’ll be on familiar territory here. All of those statements take an expression, and then return a specified value based upon how the expression is matched. It’s the same thing with the conditional operator used in C#. The format of a statement using the operator is:
Boolean expression == true ? true_value : false_value
Of course, there’s no rule that says the Boolean expression must always match true – you can match it up as required. This statement is equally valid:
Boolean expression == false ? false_value : true_value
The value that matches the expression is always specified after the ?, with the non-matching value coming after the :. The conditional operator is similar to the T-SQL IIF statement, in that only one matching and one non-matching value can be specified. This is different to CASE or SWITCH statements, which can support the matching of multiple values.
Let’s apply the conditional operator to our problem. The lines in our view that have caused the issue are:
p.Postcode.Substring(0, p.Postcode.IndexOf(" ")) AS Part1,
p.Postcode.Substring(p.Postcode.IndexOf(" ") + 1) AS Part2,
We need to change these lines to something matching the following pseudo-code:
Postcode does not contain a space ? return full postcode : return first or second part of postcode
Whenever the IndexOf statement doesn’t find a match, it returns a value of -1. We can use this to determine whether the postcode contains a space or not. Here is the new code:
p.Postcode.IndexOf(" ") == -1 ? p.Postcode : p.Postcode.Substring(0, p.Postcode.IndexOf(" ")) AS Part1,
p.Postcode.IndexOf(" ") == -1 ? p.Postcode : p.Postcode.Substring(p.Postcode.IndexOf(" ") + 1) AS Part2,
If the IndexOf(space) == -1, we return the full postcode (as it doesn’t contain a space). Otherwise, we return the appropriate part of the postcode. Part 1 says return the substring of the postcode up to the first space (this does not return the space itself). Part 2 returns everything after the space. We add 1 to the value because the match starts at the space, so without the +1 the space would be returned as part of the value, which we don’t want.
Things will be clearer with an example. Assume we are using the postcode W22 1PP. The results would be:
Part 1: W22
Part 2: 1PP
If Part 2 did not utilise the + 1 expression, 1PP would become four characters long due to the additional space. Hope that’s clear.
MSDN has plenty of information on the conditional operator and the C# string methods, so head over there if you want to learn more.
Using the Conditional Operator in a View
We’re now in a position to modify our view. Open script 300 and change the code to use the ternary operator statements.
USE DATABASE UkPostcodes;
USE SCHEMA Postcodes;
DROP VIEW IF EXISTS PostcodeDetailsView;
CREATE VIEW IF NOT EXISTS PostcodeDetailsView
AS
SELECT p.Postcode,
p.Postcode.IndexOf(" ") == -1 ? p.Postcode : p.Postcode.Substring(0, p.Postcode.IndexOf(" ")) AS Part1,
p.Postcode.IndexOf(" ") == -1 ? p.Postcode : p.Postcode.Substring(p.Postcode.IndexOf(" ") + 1) AS Part2,
c.CountyName,
d.DistrictName
FROM Postcodes AS p
LEFT JOIN Counties AS c ON p.CountyCode == c.CountyCode
LEFT JOIN Districts AS d ON p.DistrictCode == d.DistrictCode;
Run this to create the new version of the view, then open up script 310 and run that again. This time, we have success!
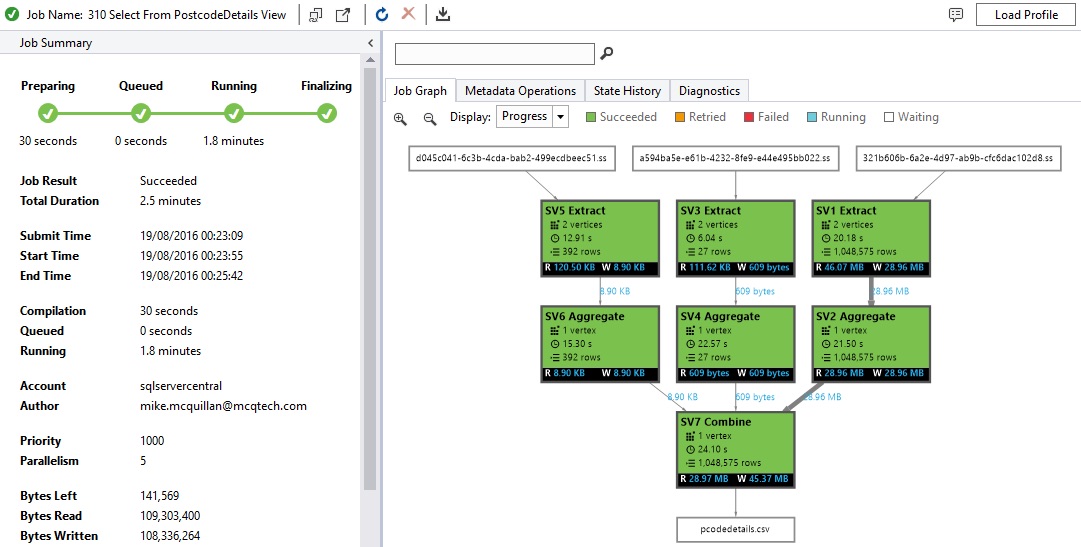
If you take a look at the file now, you’ll see the Part1 and Part2 columns are populated for postcodes that contain a space, with the full postcode displayed when no space can be found.
Creating Views Over Files
We’ve seen how to create views over SELECT statements. It’s also possible to create a view over a file too. Add a new script to your project, calling it 320 Create Counties File View.usql. Here’s the code, which will look familiar if you’ve read the earlier parts of the series:
USE DATABASE UkPostcodes; USE SCHEMA Postcodes; DROP VIEW IF EXISTS CountiesFileView; CREATE VIEW IF NOT EXISTS CountiesFileView AS EXTRACT CountyCode string, CountyName string FROM "/ssc_uk_postcodes/counties/England_Counties.csv" USING Extractors.Csv();
Run this to create the view. If you don’t have the files we’re using in this stairway, you can download them. Once the view has been created (if you want to check if it’s been created, look at the Views section of your database in the Visual Studio Server Explorer), add another new script, 330 Select From Counties File View.usql. We’ll write a simple query to grab all of the counties:
USE DATABASE UkPostcodes; USE SCHEMA Postcodes; @counties = SELECT CountyCode, CountyName FROM CountiesFileView; OUTPUT @counties TO "/outputs/countiesviewresults.csv" USING Outputters.Csv();
Submit this job and everything will run successfully.
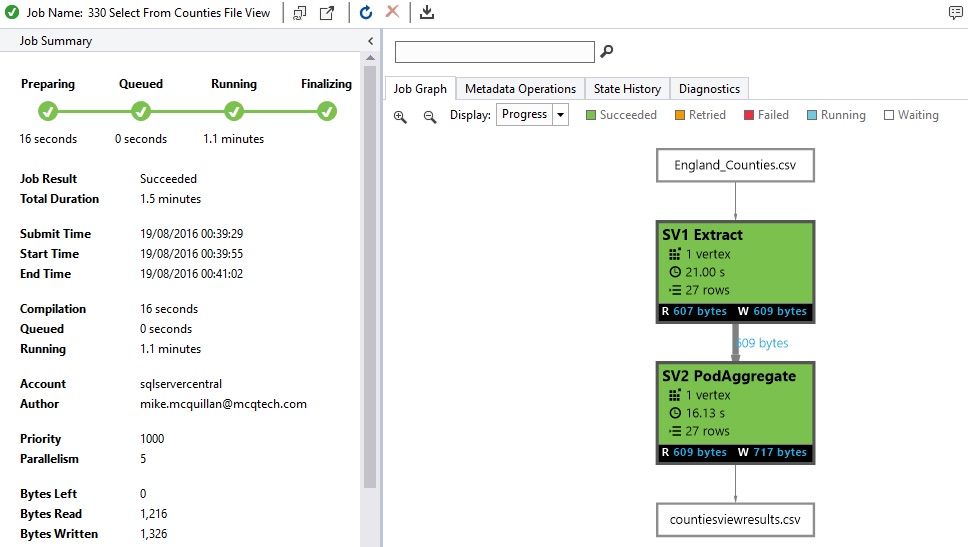
You can then navigate to the countiesviewresults.csv file in the Azure Portal if you’re so inclined. There you go, lots of county file goodness!
Summary
Not only have we learned about views in this article, we’ve also begun to see how powerfully expressive the U-SQL language can be, thanks to its tight integration with C#. We’ll see lots more expressions as the series progresses.
Views offer some great benefits to the unsuspecting (and the suspecting!) U-SQL developer. Some of these are:
- Executed in the same way as a rowset assigned to a variable (inline to the query)
- Always uses the latest data
- The view is available to all queries
- Supports SELECT statements (as we’ve shown here)
- Supports EXTRACT from files (which we’ve just seen)
Views can aid code reuse and can hide complexity from developers. One thing they can’t do is offer parameterisation – if you want to filter a view you need to add a WHERE clause to the query you’re writing. U-SQL has an answer for that in the shape of Table-Valued Functions, which will be the next step in our U-SQL stairway.