
In Level 9 of this Stairway, I covered batch mode. I explained why batch mode grants an additional speed boost in addition to the already considerable performance improvements achieved by reading from a columnstore index. I also showed a "combined mode" execution plan, where batch mode is used for some operators, and row mode for the rest.
The example I used displayed "good" combined mode. This means that all operators that process large amounts (millions) of rows run in batch mode, and only operators that work on far less data (usually after aggregation) use row mode.
In the next two levels, I will look at batch mode limitations. You will see queries that use only row mode, or that use "bad" combined mode (using row mode operators on huge volumes of data). In each case, I will point out the root cause of the batch mode failure, but I will also show how a rewrite of the query can help SQL Server find a "good" combined mode plan instead.
The sample database
All sample code in this level uses Microsoft's ContosoRetailDW sample database and builds upon the code samples from the previous levels. If you didn't follow this stairway from the start, or if you did other tests in that database and are now concerned that this might impact the code in this level, you can easily rebuild the sample database. First, download the Contoso BI Demo Database from https://www.microsoft.com/en-us/download/details.aspx?id=18279, choosing the ContosoBIdemoBAK.exe option that contains a backup file. After that, download the scripts attached to this article and execute the one appropriate for your system (either SQL Server 2012 or SQL Server 2014. If you are running SQL Server 2016, I suggest using the 2014 version of this script; keep in mind however that there have been significant changes in this latest version so many of the demo scripts in this stairway series will not work the same on SQL Server 2016. We will cover the changes in SQL Server 2016 in a later level). Do not forget to change the RESTORE DATABASE statement at the start: set the correct location of the downloaded backup file, and set the location of the database files to locations that are appropriate for your system.
Once the script has finished, you will have a ContosoRetailDW database in exactly the same state as when you had executed all scripts from all previous levels. (Except for small variations in the index creation process that are impossible to avoid).
Also note that the examples in this level are all intended to demonstrate issues specific to SQL Server 2012. All code will run without error on later versions, but you will not see the same problems and you will not benefit from using the suggested workarounds.
Batch mode limitations
In SQL Server 2012, only a small number of execution plan operators support batch mode; a few more were added in SQL Server 2014 but there are still omissions. As soon as any other operator is needed, execution falls back to row mode. This was a one-way transition in SQL Server 2012. In SQL Server 2014, support was added for "mixed mode plans", where execution can transition between batch mode and row mode multiple times; however SQL Server tries to minimize these transitions because of the overhead involved.
In all these cases, queries will still run faster than they would when using a rowstore index, but they will not give you the full performance benefit. However, it is often possible to work around these limitations by rewriting the query. This usually requires some extra thought and the resulting queries can be harder to maintain, but they will give you better performance.
Which operators support batch mode?
SQL Server 2012 only supports batch mode in a few operators. Apart from (obviously) the Columnstore Index Scan, these are Filter, Compute Scalar, and Hash Match – and the latter only for the logical operations Aggregate and Inner Join. In addition, a special new operator, Batch Hash Table Build, was introduced that is in some cases required to prepare the data before it can be processed by a Hash Match operator.
In SQL Server 2014, the Batch Hash Table Build operator is no longer needed and has been removed. The Hash Match operator now supports batch mode in all its logical join variations (outer joins, semi-joins, and anti-semi joins), as well as in the new "Global Aggregate" logical operation. Also, support for batch mode has been added to the Concatenation operator.
Now, while the list of batch-enabled operators seems rather short, these few operators (especially after the SQL Server 2014 improvements) can actually already make a lot of queries run in batch mode.
For people who live and dream in execution plans, the above lists of operators will be very useful. But if you spend more time in the query editor than in the execution plan display, then you will need to know how these limitations translate to queries. So in the next two levels, I will focus on query patterns that are known to cause issues with batch mode (or other limitations related to columnstore indexes). As mentioned, the patterns demonstrated in this level all apply to SQL Server 2012 only; if you run the same code on newer versions you will not see the same problems. In the next level we will also highlight some patterns that cause issues on SQL Server 2014 as well. (I will describe the improvements in SQL Server 2016 in a later level). I will also show how to work around these limitations.
Outer joins
As already mentioned in level 1, outer joins cause a fallback to row mode (in SQL Server 2012 only). Depending on the rest of the query, the result will either use only row mode, or it will use "bad" combined mode. An example of the latter can be seen by running the code in listing 10-1:
USE ContosoRetailDW;
go
WITH NonContosoProducts
AS (SELECT *
FROM dbo.DimProduct
WHERE BrandName <> 'Contoso')
SELECT ncp.ProductName,
dd.CalendarQuarter,
COUNT(fos.SalesOrderNumber) AS NumOrders,
SUM(fos.SalesQuantity) AS QuantitySold
FROM dbo.FactOnlineSales AS fos
INNER JOIN dbo.DimDate AS dd
ON dd.Datekey = fos.DateKey
RIGHT JOIN NonContosoProducts AS ncp
ON ncp.ProductKey = fos.ProductKey
GROUP BY ncp.ProductName,
dd.CalendarQuarter
ORDER BY ncp.ProductName,
dd.CalendarQuarter;
Listing 10-1: Using an outer join
The relevant part of the execution plan for this query is shown in figure 10-1. As in the previous level, the shaded area shows which operators run in batch mode.

Figure 10-1: Outer join causes row mode fallback
The scan of the FactOnlineSales table and the inner join to the DimDate table are executed in batch mode, but then execution falls back into row mode for the outer join to the non-Contoso products from the DimProduct table. The three marked operators, Parallelism (Repartition Streams), Hash Match (Left Outer Join), and Hash Match (Partial Aggregate), each process a huge number of rows – over 12 million for the first two, and almost 8 million for the third. The rest of the plan (not shown in the screenshot) processes fewer than 20,000 rows – also in row mode, but for such a low number of rows that's not an issue.
The easiest way to speed up this query would be to change the outer join back to an inner join, to enable batch mode for the marked operators. But that can change the results of the query, which is of course not acceptable. However, we can change the join type if we also make other changes to compensate, as shown in listing 10-2. The query is more complex, but it runs a lot faster because we now get a "good" combined mode plan:
USE ContosoRetailDW;
go
WITH NonContosoProducts
AS (SELECT *
FROM dbo.DimProduct
WHERE BrandName <> 'Contoso')
, JoinedAndAggregated
AS (SELECT ncp.ProductName,
dd.CalendarQuarter,
COUNT(fos.SalesOrderNumber) AS NumOrders,
SUM(fos.SalesQuantity) AS QuantitySold
FROM dbo.FactOnlineSales AS fos
INNER JOIN dbo.DimDate AS dd
ON dd.Datekey = fos.DateKey
INNER JOIN NonContosoProducts AS ncp
ON ncp.ProductKey = fos.ProductKey
GROUP BY ncp.ProductName,
dd.CalendarQuarter)
SELECT ncp.ProductName,
jaa.CalendarQuarter,
COALESCE(jaa.NumOrders, 0) AS NumOrders,
jaa.QuantitySold AS QuantitySold
FROM JoinedAndAggregated AS jaa
RIGHT JOIN NonContosoProducts AS ncp
ON ncp.ProductName = jaa.ProductName
ORDER BY ncp.ProductName,
jaa.CalendarQuarter;
Listing 10-2: Rewrite of an outer join to use more batch mode
The trick used here is to consider the similarities and differences between the inner and the outer join. Both joins combine sales data with product data for non-Contoso products; both joins will exclude sales of products that are not in the NonContosoProducts list. The only difference is what happens with non-Contoso products that have no sales. The inner join removes these products; the outer join includes row for each of them with NULL values for all columns from the other table. In the aggregation that follows, each of these extra rows is a separate product that will become a separate "group" (consisting of that single row) in the aggregation; the CalendarQuarter column will be NULL; a COUNT aggregation will return 0 for COUNT(columnname), or 1 for COUNT(*) or COUNT(constant).
In listing 10-2, I start with an inner join, so I lose these extra rows. Then, after aggregation, I add another join to the non-Contoso products, this time an outer join, for the sole purpose of reintroducing those lost rows. So instead of first adding one extra row for each unmatched product and then aggregating per product, I now first aggregate per product and then add an extra row for unmatched products. The final results are equal (as long as I take care to do a proper COALESCE for the COUNT results), but now all the joins and most of the aggregation are done in batch mode. The execution plan has become more complicated, but all operators that run in row mode now process a small number of rows.
The explanation above proves that the two queries are logically equivalent; they will always, under any circumstances, produce the same results. That is a key consideration for all the rewrites presented in this and the next level. A rewrite is only acceptable if you can prove without any doubt that it will never change the results. Just testing is not enough; sometimes an erroneous rewrite will only cause differences in some edge cases that might not exist in your test data. However, the proof should not replace testing, it is still possible that you made an oversight in your logic, or that you introduced a bug by a simple typo in the query.
On my laptop, performance improves from 5.8 seconds for the original query to 0.7 seconds after the rewrite. After proving that the rewrite will not change the results and testing that I didn't make an error, I am happy to give this performance improvement to my users. Of course with a long comment in the code to explain to my coworkers why I replaced a simple outer join query with a more complex query, and the proof that these are in fact equivalent.
UNION ALL
Another annoying limitation for batch mode execution on SQL Server 2012 occurs when combining result sets using UNION ALL. This may not be a common SQL construct in data warehouse and reporting applications, but it might be used even without the data analyst being aware of it, especially on a SQL Server 2012 installation.
A common method to work around the read-only limitation for columnstore indexes on SQL Server 2012 is to partition the large fact tables by date. Data that is old enough to be stale is stored in the fact table (with a columnstore index). More recent data (that is still changing), is stored in a smaller table with only rowstore indexes. When a time period closes, a columnstore index is built on the smaller table after which partition switching can be used to add this data to the larger table. (See https://social.technet.microsoft.com/wiki/contents/articles/5069.add-data-to-a-table-with-a-columnstore-index-using-partition-switching.aspx for an example of this technique).
The benefit of this technique is that you get the performance benefit of the columnstore index for most of the data, and still have read/write possibilities on the much smaller "recent" fraction of the data. But the down-side is that now the data is spread out over two tables. In order to facilitate easy querying, many DBAs will create a view that combines the data from the two tables. Data analysts can then query that view instead of having to query both tables and combined the results.
In the Contoso sample database, there is no table that can be easily used to set up a very realistic example of this technique, so I have to resort to the rather contrived example shown in listing 10-3:
USE ContosoRetailDW;
go
-- Quick and dirty way to create an empty copy of the table
SELECT *
INTO dbo.FactOnlineSales_RowStore
FROM dbo.FactOnlineSales
WHERE 1 = 0;
go
-- Add a few rows of sample data
INSERT INTO dbo.FactOnlineSales_RowStore
SELECT TOP (10) DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey,
SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount,
ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount,
TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate
FROM dbo.FactOnlineSales
ORDER BY OnlineSalesKey;
-- Create the same indexes as the fact table (except the columnstore index)
ALTER TABLE dbo.FactOnlineSales_RowStore
ADD CONSTRAINT PK_FactOnlineSales_RowStore_SalesKey
PRIMARY KEY NONCLUSTERED (OnlineSalesKey);
CREATE CLUSTERED INDEX ix_FactOnlineSales_RowStore_ProductKey
ON dbo.FactOnlineSales_RowStore (ProductKey);
go
-- Create a view that combines the two tables
CREATE VIEW dbo.FactOnlineSales_Combined
AS
SELECT *
FROM dbo.FactOnlineSales
UNION ALL
SELECT *
FROM dbo.FactOnlineSales_RowStore;
Listing 10-3: Creating a view to combine columnstore and rowstore data
The code in listing 10-3 creates an additional table (FactOnlineSales_RowStore) to mimic the table for recent data, and a view (FactOnlineSales_Combined) that combines both tables for easy querying. Let's see how this view performs in a typical data warehousing query:
USE ContosoRetailDW;
go
SELECT dp.ProductName,
dd.CalendarYear,
SUM(fos.SalesQuantity) AS QuantitySold,
AVG(SalesAmount) AS AvgSalesAmt
FROM dbo.FactOnlineSales_Combined AS fos
INNER JOIN dbo.DimDate AS dd
ON dd.Datekey = fos.DateKey
INNER JOIN dbo.DimProduct AS dp
ON dp.ProductKey = fos.ProductKey
GROUP BY dp.ProductName,
dd.CalendarYear
ORDER BY dp.ProductName,
dd.CalendarYear;
Listing 10-4: Data warehousing query on a view that uses UNION ALL
Because of the view, there is a UNION ALL "hidden" in this query. But if a DBA created the view, then the data analyst who writes this query might not be aware of this. They will find out, though, when they run this query. On my laptop, it takes almost five seconds to run, much longer than other queries on the same table. This is because the entire query runs in row mode.
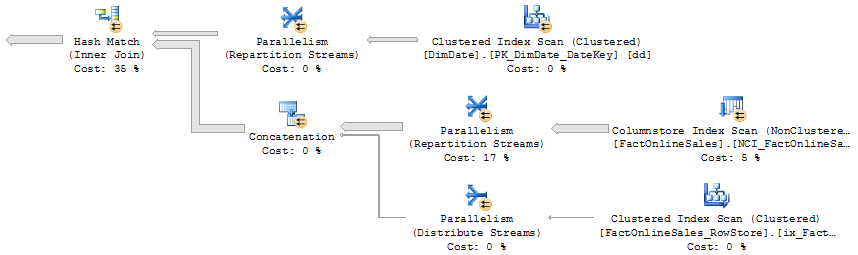
Figure 10-2: Row mode is used for a UNION ALL
Figure 10-2 shows a part of the execution plan. This plan fragment is rather straightforward: the two FactOnlineSales tables are read and the data is combined using the Concatenation operator (the execution plan's equivalent of a UNION ALL). This operator doesn't support batch mode in SQL Server 2012, so the only part of the plan that could in theory be executed in batch mode is the Columnstore Index Scan operator. In this case, even that operator is executed in row mode – probably because the optimizer expects the overhead of the mode transition to cost more than the benefit of scanning in batch mode.
In order to work around the batch mode limitation for UNION ALL, we have to give up the convenience of using the single view. The same results can be returned much faster on SQL Server 2012 by using this query:
USE ContosoRetailDW;
go
WITH ResultsForColumnsStore
AS (SELECT dp.ProductName,
dd.CalendarYear,
SUM(fos.SalesQuantity) AS QuantitySold,
SUM(fos.SalesAmount) AS SumSalesAmt,
COUNT(fos.SalesAmount) AS CntSalesAmt
FROM dbo.FactOnlineSales AS fos
INNER JOIN dbo.DimDate AS dd
ON dd.Datekey = fos.DateKey
INNER JOIN dbo.DimProduct AS dp
ON dp.ProductKey = fos.ProductKey
GROUP BY dp.ProductName,
dd.CalendarYear)
, ResultsForRowStore
AS (SELECT dp.ProductName,
dd.CalendarYear,
SUM(fos.SalesQuantity) AS QuantitySold,
SUM(fos.SalesAmount) AS SumSalesAmt,
COUNT(fos.SalesAmount) AS CntSalesAmt
FROM dbo.FactOnlineSales_RowStore AS fos
INNER JOIN dbo.DimDate AS dd
ON dd.Datekey = fos.DateKey
INNER JOIN dbo.DimProduct AS dp
ON dp.ProductKey = fos.ProductKey
GROUP BY dp.ProductName,
dd.CalendarYear)
, ResultsCombined
AS (SELECT ProductName, CalendarYear, QuantitySold, SumSalesAmt, CntSalesAmt
FROM ResultsForColumnsStore
UNION ALL
SELECT ProductName, CalendarYear, QuantitySold, SumSalesAmt, CntSalesAmt
FROM ResultsForRowStore)
SELECT ProductName, CalendarYear,
SUM(QuantitySold) AS QuantitySold,
SUM(SumSalesAmt)
/ SUM(CntSalesAmt) AS AvgSalesAmt
FROM ResultsCombined
GROUP BY ProductName,
CalendarYear
ORDER BY ProductName,
CalendarYear;
Listing 10-5: A faster alternative for UNION ALL
The query is quite lengthy, but the method used is actually not that complex. There are two CTEs (Common Table Expressions) that are each very similar to the original query. These compute the aggregated results for either only the table with the columnstore index, or for only the smaller table with rowstore indexes. The UNION ALL at the end now operates on the results after aggregation. The CTE for the large table now mostly runs in batch mode; the rest of the plan is all row mode but these operators process either the smaller "recent data" table or the aggregated results so they process far fewer rows. On my laptop, execution time went down from 4.1 to just 0.6 seconds, so based on the logical consideration that the queries should be equivalent and test results confirming that they are, I can now replace the original query with this faster equivalent – again with sufficient comments that anyone who later looks at the code will understand what's going on and why.
Local-global aggregation
The rewrite used in listing 10-5 uses a pattern known as "local-global aggregation", a pattern that you will see return several times in the next level. In this pattern, data to be aggregated is first divided into smaller groups. Each smaller group is then individually aggregated, and these "local" intermediate aggregates are then combined to get the final "global" aggregate.The tricky part of this pattern is knowing how to handle each aggregate. For some queries, such as MIN, MAX, and SUM, both the local and the global aggregation use the same function. For a COUNT, you need to use COUNT in the local aggregation, but the global aggregation has to SUM the results. The AVG aggregate is even more complex: you need to compute both the SUM and the COUNT (using local-global aggregation for each), and then divide them to present the average.For queries that use statistical aggregate functions (STDEV, STDEVP, VAR, and VARP), the local-global aggregation pattern is even more complex. This is beyond the scope of this article but you can find more details about this on my blog at http://sqlblog.com/blogs/hugo_kornelis/archive/2016/08/31/the-diy-guide-for-local-global-aggregation.aspx.
Conclusion
Especially on SQL Server 2012, many query constructions cause suboptimal performance for tables with columnstore indexes because row mode is used for the entire execution plan or for a large a part of it. In this level I showed two of the most common query patterns that can cause a fallback to row mode: outer joins, and UNION ALL (which is often hidden in a view).
I also showed that there are ways to work around this limitation. By rewriting the query, we can ensure that the part of the processing that needs to be done on a large number of rows will still run in batch mode, and that row mode is only used by operators that process much less data. This can result in enormous performance gains, but the price you pay is that your queries will usually be longer, harder to write, and harder to maintain.
The next level will continue our coverage of query constructions that can result in slower performance, and how to rewrite those queries to get better performance.