
In Level 7, we looked at optimizing rowgroup elimination for a nonclustered columnstore index. For a clustered columnstore index, the same technique can be used but the steps and syntax change a bit. This will be covered later – but first, let’s take a look at another significant difference between nonclustered and clustered columnstore indexes, which is that the former are read-only (in SQL Server 2012 and 2014), whereas the latter allow updates. This makes the index far more flexible and usable, but it has a down side as well: no matter how much effort you put into optimizing the index structure when building the index, it will not remain that way. When you start to use clustered columnstore indexes, you will also have to plan for index maintenance.
Reorganizing the index
For rowstore index maintenance, there are two options: reorganize and rebuild, with reorganize being the more lightweight option. For columnstore indexes, those same two options are available, though they do not have the exact same effect.
Reorganizing a clustered columnstore index can be useful after doing a large data load that did not use bulk load, or after doing a large update – in short, after any operation that causes a lot of trickle inserts. Trickle inserts go into an open deltastore, which will be closed when it reaches 1,048,576 rows. At that point, without further action, it will wait for the background tuple mover process to pick it up and compress it into columnstore format. But that process is designed to use minimal resources, so it can be slow – so if a lot of closed rowgroups are created in a short time, it can fall behind. Until it catches up, you can experience suboptimal performance from your columnstore index.
When you reorganize the index, you tell SQL Server to not wait for the tuple mover, but immediately compress all closed deltastore rowgroups for the specified index. This will have the same effect as waiting for the tuple mover to kick in, but much faster – and at the expense of using more resources. Reorganizing a columnstore index is an online operation, which means that the index can be used normally during the process.
ALTER INDEX IndexName ON schema.TableName REORGANIZE [ PARTITION = [ PartitionNumber | ALL ] ];
Figure 8-1: Syntax for reorganizing a clustered columnstore index
The most typical use case for reorganizing a columnstore index is when you perform a data load process that you know will generate lots of closed deltastore rowgroups. If you find that the tuple mover sometimes does not catch up before the end of the maintenance window, then you can use the syntax as shown in figure 8-1 to force SQL Server to immediately compress all of them. Beware of the impact that the additional resource usage can have on other tasks running at the same time, though – test to ensure that you are not causing issues for other jobs that need to finish before the end of the maintenance window.
If your columnstore index is partitioned, you can choose to reorganize only specific partitions by specifying the partition number in the ALTER INDEX statement, or you can either specify PARTITION = ALL or just leave out the partition specification (both of which will result in all partitions being processed).
To see this process in action, run the code in listing 8-1, which is almost identical to the code we used in level 5 (listing 5-3) to demonstrate the tuple mover. The only difference is that I replaced the WAITFOR command (used to wait for the tuple mover to kick in) with an ALTER INDEX REORGANIZE statement. The code first adds 1.1 million rows in 11 batches of 100,000 each, to ensure that at least one closed deltastore rowgroup will be created. It then shows the rowgroup metadata, reorganizes the index, and then queries the metadata again to show the effect of reorganizing the index.
USE ContosoRetailDW;
GO
-- Add 1,100,000 rows, in 11 batches of 100,000 each
INSERT dbo.FactOnlineSales2
(DateKey, StoreKey, ProductKey, PromotionKey,
CurrencyKey, CustomerKey, SalesOrderNumber,
SalesOrderLineNumber, SalesQuantity, SalesAmount,
ReturnQuantity, ReturnAmount, DiscountQuantity,
DiscountAmount, TotalCost, UnitCost, UnitPrice,
ETLLoadID, LoadDate, UpdateDate)
SELECT TOP(100000)
DateKey, StoreKey, ProductKey, PromotionKey,
CurrencyKey, CustomerKey, SalesOrderNumber,
SalesOrderLineNumber, SalesQuantity, SalesAmount,
ReturnQuantity, ReturnAmount, DiscountQuantity,
DiscountAmount, TotalCost, UnitCost, UnitPrice,
ETLLoadID, LoadDate, UpdateDate
FROM dbo.FactOnlineSales;
GO 11
-- Check the rowgroups metadata
SELECT OBJECT_NAME(rg.object_id) AS TableName,
i.name AS IndexName,
i.type_desc AS IndexType,
rg.partition_number,
rg.row_group_id,
rg.total_rows,
rg.size_in_bytes,
rg.deleted_rows,
rg.[state],
rg.state_description
FROM sys.column_store_row_groups AS rg
INNER JOIN sys.indexes AS i
ON i.object_id = rg.object_id
AND i.index_id = rg.index_id
WHERE i.name = N'CCI_FactOnlineSales2'
ORDER BY TableName, IndexName,
rg.partition_number, rg.row_group_id;
GO
-- Reorganize the index
ALTER INDEX CCI_FactOnlineSales2 ON dbo.FactOnlineSales2 REORGANIZE;
GO
-- Check the rowgroups metadata again
SELECT OBJECT_NAME(rg.object_id) AS TableName,
i.name AS IndexName,
i.type_desc AS IndexType,
rg.partition_number,
rg.row_group_id,
rg.total_rows,
rg.size_in_bytes,
rg.deleted_rows,
rg.[state],
rg.state_description
FROM sys.column_store_row_groups AS rg
INNER JOIN sys.indexes AS i
ON i.object_id = rg.object_id
AND i.index_id = rg.index_id
WHERE i.name = N'CCI_FactOnlineSales2'
ORDER BY TableName, IndexName,
rg.partition_number, rg.row_group_id;
GO
Listing 8-1: Reorganizing a clustered columnstore index
As you can see from the partial results on my system (figure 8-2), there is a new compressed rowgroup to replace the closed rowgroup generated by the inserts, but all other rowgroups are completely unaffected. (If you run this on your system, then the rowgroup numbers and some other details may be different – as in previous levels, this is because there is no way to force the index build process to produce the exact same result when conditions are different).
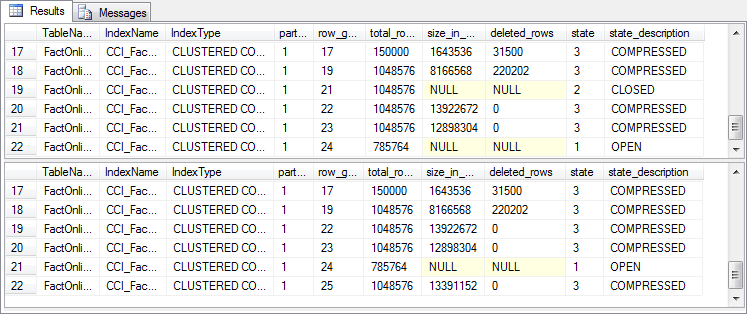
Figure 8-2: Effect of reorganizing a clustered columnstore index
It is important to realize that this code to reorganize the index is does not need to be run. If I had just waited a few minutes, the tuple mover would have kicked in and done the same work in the background. You only have to reorganize a clustered columnstore index if there is a reason why you need the closed rowgroups to be compressed immediately.
Rebuilding the index
As we saw in the level 5 and level 6, modifying data causes a columnstore index to deteriorate in many ways. Bulk loading results in rowgroups that can be much smaller than the maximum size, deleted rows (which includes old versions of updated rows) are marked as deleted but never actually deleted from the rowgroups, and trickle inserts usually leave at least one rowgroup open. Reorganizing the index does not help here, and in fact can result in even more rowgroups at sub-optimal size. The only way to remove all of this and clean up the entire index is to rebuild it. Which, unfortunately, is an offline operation – meaning that SQL Server will take an exclusive lock on the index, making the index and hence the table inaccessible for the duration of the process.
To see the rebuild of a clustered columnstore index in action, run the code in listing 8-2 to rebuild the clustered columnstore index using only the default options. Before and after the rebuild, it queries the rowgroup metadata; we have not seen this particular query before but it is the same basic logic as the metadata query used in listing 8-1 as well as several previous levels. The difference is that it now presents aggregated numbers instead of showing the individual rowgroups.
USE ContosoRetailDW;
GO
-- Check the rowgroups metadata (aggregated version)
SELECT OBJECT_NAME(rg.object_id) AS TableName,
i.name AS IndexName,
i.type_desc AS IndexType,
rg.partition_number,
rg.state_description,
COUNT(*) AS NumberOfRowgroups,
SUM(rg.total_rows) AS TotalRows,
SUM(rg.size_in_bytes) AS TotalSizeInBytes,
SUM(rg.deleted_rows) AS TotalDeletedRows
FROM sys.column_store_row_groups AS rg
INNER JOIN sys.indexes AS i
ON i.object_id = rg.object_id
AND i.index_id = rg.index_id
WHERE i.name = N'CCI_FactOnlineSales2'
GROUP BY rg.object_id, i.name, i.type_desc,
rg.partition_number, rg.state_description
ORDER BY TableName, IndexName, rg.partition_number;
GO
-- Rebuild the index
ALTER INDEX CCI_FactOnlineSales2 ON dbo.FactOnlineSales2 REBUILD;
GO
-- Check the rowgroups metadata again
SELECT OBJECT_NAME(rg.object_id) AS TableName,
i.name AS IndexName,
i.type_desc AS IndexType,
rg.partition_number,
rg.state_description,
COUNT(*) AS NumberOfRowgroups,
SUM(rg.total_rows) AS TotalRows,
SUM(rg.size_in_bytes) AS TotalSizeInBytes,
SUM(rg.deleted_rows) AS TotalDeletedRows
FROM sys.column_store_row_groups AS rg
INNER JOIN sys.indexes AS i
ON i.object_id = rg.object_id
AND i.index_id = rg.index_id
WHERE i.name = N'CCI_FactOnlineSales2'
GROUP BY rg.object_id, i.name, i.type_desc,
rg.partition_number, rg.state_description
ORDER BY TableName, IndexName, rg.partition_number;
GO
Listing 8-2: Rebuilding a clustered columnstore index
Rebuilding a columnstore is conceptually exactly the same as rebuilding a rowstore index. SQL Server reads all data from the existing columnstore index, builds a new columnstore index on that data, then drops the old index. After that process, the index will be as good as new, having all rowgroups (except the last) completely full, all deleted rows really deleted, and all open and closed rowgroups replaced by compressed rowgroups.
As you can see in figure 8-3, running this on my system reduced the number of rowgroups from 22 to 18, and saved almost 21 MB of storage (actually more, because the metadata query doesn’t show the storage used for the open rowgroup). While it may appear as if the number of rows has gone down, this is not actually the case – just remember that the reported number of rows in compressed rowgroups includes the rows that are marked as deleted.
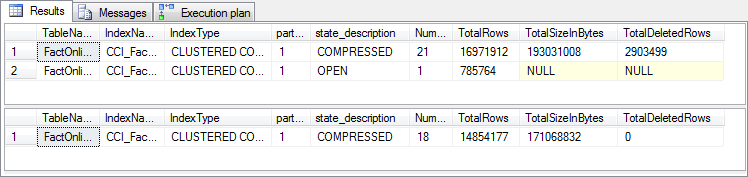
Figure 8-3: Effect of rebuilding a clustered columnstore index
Now that we have seen an index rebuild with default options, let’s take a look at the syntax as shown in figures 8-4 and 8-5, to see what other options we have.
ALTER INDEX IndexName ON schema.TableName
REBUILD [ PARTITION = ALL ]
[ WITH ([ DATA_COMPRESSION = { COLUMNSTORE | COLUMNSTORE_ARCHIVE }
[ ON PARTITIONS ( { number | first TO last } [ , ... ] ) ]
[ , ... ]
[ , MAXDOP = number ]
) ];
Figure 8-4: Syntax for rebuilding a complete clustered columnstore index
ALTER INDEX IndexName ON schema.TableName
REBUILD PARTITION = number
[ WITH ([ DATA_COMPRESSION = { COLUMNSTORE | COLUMNSTORE_ARCHIVE } ]
[ , MAXDOP = number ]
) ];
Figure 8-5: Syntax for rebuilding one partition in a clustered columnstore index
As you can see, there are quite a few different options, which is why I split the syntax description over two diagrams. The options in figure 8-4 are used to rebuild the entire index. You can make this explicit by including the PARTITION = ALL specification, or you can omit this part. The optional WITH clause allows you to choose between either the normal columnstore compression, or the archive columnstore compression that saves even more space by using a more aggressive compression algorithm. For a partitioned table, you can use the ON PARTITIONS clause to force different compression types for individual partitions, by specifying the partition number or a range of partition numbers. If you rebuild without specifying a WITH clause, each partition will retain its current compression type.
The second set of options, in figure 8-5, rebuilds only a single partition of a clustered columnstore index and optionally changes the compression type.
Both versions allow you to specify the degree of parallelism. When not specified, the rebuild process, just like the initial build, will use all the nodes it can get.
Archival compression
The COLUMNSTORE_ARCHIVE keyword seen in the syntax for rebuilding a clustered columnstore index is used to invoke archival expression. As already mentioned briefly in level 2, this is a more aggressive compression algorithm that reduces the on-disk size of the data even more than regular columnstore expression, but at the expense of using more CPU, both when rebuilding the columnstore index and when retrieving data from it. You would normally use this compression type only on partitioned tables, and only on the partitions that contain historical data – data that is so old that it is queried very infrequently. For that type of data, the overhead of performing the extra decompression when retrieving the data will be outweighed by the disk space saving. But for data that is still queried on a regular basis, standard columnstore compression is the recommended level.
The code in listing 8-3 once more rebuilds the entire clustered columnstore index, this time choosing archival compression, and then looks at the space taken. Since the sample sales table used for this series is not partitioned, I can only choose a single compression type for the whole table.
USE ContosoRetailDW;
GO
-- Rebuild the index, applying archival compression
ALTER INDEX CCI_FactOnlineSales2 ON dbo.FactOnlineSales2
REBUILD WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE);
GO
-- Check the rowgroups metadata again
SELECT OBJECT_NAME(rg.object_id) AS TableName,
i.name AS IndexName,
i.type_desc AS IndexType,
rg.partition_number,
rg.state_description,
COUNT(*) AS NumberOfRowgroups,
SUM(rg.total_rows) AS TotalRows,
SUM(rg.size_in_bytes) AS TotalSizeInBytes,
SUM(rg.deleted_rows) AS TotalDeletedRows
FROM sys.column_store_row_groups AS rg
INNER JOIN sys.indexes AS i
ON i.object_id = rg.object_id
AND i.index_id = rg.index_id
WHERE i.name = N'CCI_FactOnlineSales2'
GROUP BY rg.object_id, i.name, i.type_desc,
rg.partition_number, rg.state_description
ORDER BY TableName, IndexName, rg.partition_number;
GO
Listing 8-3: Using archival compression
As can be seen in figure 8-6, the total on-disk space has been reduced from over 163 MB (see figure 8-3) to just over 82 MB – a 50% reduction over the already impressive regular columnstore compression.

Figure 8-6: Effect of archival compression
I want to stress that the above is for the sake of demonstration only, and not a recommended practice. If you want to use archival compression, choose a partitioning scheme that separates the rarely used data from the frequently used data, and use archival compression only for the partitions with little usage. There are only very few scenarios where archival compression for an entire table is the correct choice.
Preordering the data
So far, we have not looked at the effectiveness of rowgroup elimination for the clustered columnstore index. But chances are that this is pretty abysmal. Looking back over the previous levels, we have created the FactOnlineSales2 table as a heap, which is always completely unordered. We then built a clustered columnstore index directly on top of that, so even that first version of the index was unlikely to have any correlation between the data values and the rowgroups. And then we have added rows, deleted rows, updated rows, and rebuilt the index twice without ever considering order at all. With all that, I would be very surprised if there is even a single column that will ever qualify for rowgroup elimination.
USE ContosoRetailDW;
GO
SELECT p.partition_number,
s.segment_id,
MAX(s.row_count) AS row_count,
MAX(CASE WHEN c.name = N'OnlineSalesKey'
THEN s.min_data_id END) AS MinOnlineSalesKey,
MAX(CASE WHEN c.name = N'OnlineSalesKey'
THEN s.max_data_id END) AS MaxOnlineSalesKey,
MAX(CASE WHEN c.name = N'StoreKey'
THEN s.min_data_id END) AS MinStoreKey,
MAX(CASE WHEN c.name = N'StoreKey'
THEN s.max_data_id END) AS MaxStoreKey,
MAX(CASE WHEN c.name = N'ProductKey'
THEN s.min_data_id END) AS MinProductKey,
MAX(CASE WHEN c.name = N'ProductKey'
THEN s.max_data_id END) AS MaxProductKey
FROM sys.column_store_segments AS s
INNER JOIN sys.partitions AS p
ON p.hobt_id = s.hobt_id
INNER JOIN sys.indexes AS i
ON i.object_id = p.object_id
AND i.index_id = p.index_id
LEFT JOIN sys.index_columns AS ic
ON ic.object_id = i.object_id
AND ic.index_id = i.index_id
AND ic.index_column_id = s.column_id
LEFT JOIN sys.columns AS c
ON c.object_id = ic.object_id
AND c.column_id = ic.column_id
WHERE i.name = N'CCI_FactOnlineSales2'
AND c.name IN (N'OnlineSalesKey', N'StoreKey', N'ProductKey')
GROUP BY p.partition_number,
s.segment_id;
Listing 8-4: Reviewing some metadata for rowgroup elimination
Running the query in listing 8-4 confirms by suspicion. For the columns this query focuses on, data is distributed about evenly across all rowgroups, so little to no rowgroup elimination can be expected when queries filter on these columns. (Again, results on your system will probably be different, but should show a similar pattern).
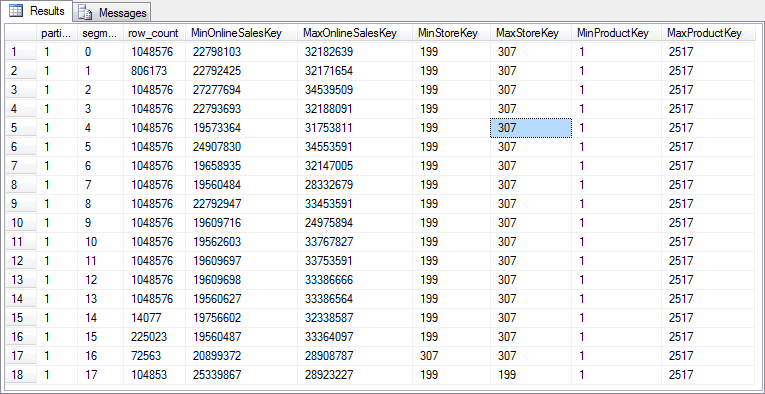
Figure 8-7: Rowgroup elimination data
In the previous level, I showed how to optimize a nonclustered columnstore index for rowgroup elimination by building a (rowstore) clustered index on the columns most frequently used as filter before building the columnstore index. For a clustered columnstore index, that same basic technique can be used. But there is a catch. SQL Server does not allow a table to have more than a single clustered index. So if there is a clustered rowstore index, we cannot add a clustered columnstore index, we have to replace the existing clustered rowstore index with the clustered columnstore index. The best way to do that is to create the index using the DROP_EXISTING keyword, which tells SQL Server to build a new index that replaces the existing index.
The code in listing 8-5 shows how this can be used as part of index maintenance. There already is a clustered columnstore index on the table, so we first create a rowstore clustered index to enforce the desired order, by using DROP_EXISTING to replace the columnstore; and then recreate the clustered columnstore index, again using DROP_EXISTING = ON. In this case I decided to also enforce a serial execution by specifying the MAXDOP option. As already discussed in the previous level, this increases the duration of the index creation process, but ensures the best possible correlation between the rowgroups and the order imposed by the rowstore clustered index.
USE ContosoRetailDW; GO -- Create a clustered index on the desired column CREATE CLUSTERED INDEX CCI_FactOnlineSales2 ON dbo.FactOnlineSales2(ProductKey) WITH (DROP_EXISTING = ON); -- Finally, recreate the clustered columnstore index CREATE CLUSTERED COLUMNSTORE INDEX CCI_FactOnlineSales2 ON dbo.FactOnlineSales2 WITH (DROP_EXISTING = ON, MAXDOP = 1); GO
Listing 8-5: Rebuild the clustered columnstore index over a clustered rowstore index
Since we are asking SQL Server to rebuild the clustered index on a quite large table twice, it will take a few minutes to complete. After that, you can rerun the query in listing 8-4 to see the effect of this alternative way to rebuild the clustered columnstore. Figure 8-8 shows the results on my system. As you can see, rowgroup elimination will now be far more effective when most of my queries use a filter on the ProductKey column.
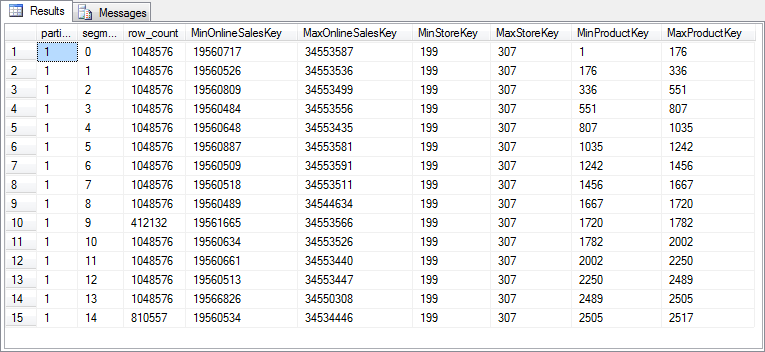
Figure 8-8: Rowgroup elimination data
In the code above I have shown how to optimize an existing clustered columnstore index for rowgroup elimination, by first replacing it with a clustered rowstore index and then replacing that again with the clustered columnstore index. The same technique can, and in most cases should, be used when first creating a clustered columnstore index on an existing table. In that case the procedure is the same except you start by creating a clustered rowstore index if the table was a heap, or replacing the clustered rowstore index if it was defined on a column that is not frequently used in filters. However, beware that using the DROP_EXISTING = ON option requires that the index name doesn’t change – so if you want your clustered columnstore index to use a specific naming scheme, make sure to use that name when creating the clustered rowstore index, even though it does not fit in your naming scheme for rowstore indexes.
If you create a clustered columnstore index on a new, empty table, then there is no need for any of these extra actions, since there is no data to preorder anyway. The rowgroups will form as data is added to the table, and you will have to use the double index replacement technique as shown in listing 8-5 once there is sufficient data in the table in order to enable better rowgroup elimination.
Conclusion
Because a clustered columnstore index allows data to change, the index quality will slowly degrade over time. Index maintenance is required in order to periodically restore the index to optimum usefulness.
In SQL Server 2014, reorganizing a clustered columnstore index has a fairly limited use, because it only does what the tuple mover would do – just quicker. You sometimes might want to reorganize a clustered columnstore at the end of a job that is known to create a lot of closed rowgroups, especially if you want to be sure that all queries will perform at optimal speed after the job finished.
Rebuilding a clustered columnstore index takes more time and resources than reorganizing, but it also achieves much more. Space occupied by deleted rows, or by original versions of updated rows, will be reclaimed; and all rows will be compressed into as few rowgroups as possible. If you have a workload that includes updating or deleting data in the clustered columnstore, then you should include a periodic rebuild of the index in your maintenance jobs. If your load process produces a significant number of rowgroups that are compressed when they are still only partially filled, you also should include an index rebuild in your maintenance jobs.
Rebuilding a clustered columnstore index will not fully preserve the order that you might have previously imposed, and it will definitely not enforce any order on data that has been added since the index was last rebuilt. So even when you schedule periodic index rebuilds, you will still find that rowgroup elimination will become less effective over time. The only way to fix that is to replace the clustered columnstore index with a clustered rowstore index on the right combination of columns, then replace that index with a new clustered columnstore index.
