
We started our exploration of query constructions that inhibit batch mode execution in Level 10 of this series (which you can read here: http://www.sqlservercentral.com/articles/Stairway+Series/148676) with two examples that affect SQL Server 2012 only: outer joins and UNION ALL.
In this level we will look at many other similar issues and their workaround. Some of them affect SQL Server 2012 only, others affect SQL Server 2014 as well – I will point out the affected versions in each case. Note that for all the rewrites presented in this level, just as with those from the last level, you should only use them if you understand why they are guaranteed to never change the results, after proper testing, and with sufficient comments in the code to ensure that anyone looking at the code in the future will understand what’s going on.
The sample database
All sample code in this level uses Microsoft’s ContosoRetailDW sample database and builds upon the code samples from the previous levels. If you didn’t follow this stairway from the start, or if you did other tests in that database and are now concerned that this might impact the code in this level, you can easily rebuild the sample database. First, download the Contoso BI Demo Database from https://www.microsoft.com/en-us/download/details.aspx?id=18279, choosing the ContosoBIdemoBAK.exe option that contains a backup file. After that, download the scripts attached to this article and execute the one appropriate for your system (either SQL Server 2012 or SQL Server 2014. If you are running SQL Server 2016, I suggest using the 2014 version of this script; keep in mind however that there have been significant changes in this version so many of the demo scripts in this stairway series will not work the same on SQL Server 2016. We will cover the changes in SQL Server 2016 in a later level). Do not forget to change the RESTORE DATABASE statement at the start: set the correct location of the downloaded backup file, and set the location of the database files to locations that are appropriate for your system.
Once the script has finished, you will have a ContosoRetailDW database in exactly the same state as when you had executed all scripts from all previous levels. (Except for small variations in the index creation process that are impossible to avoid).
IN and EXISTS
If a query filter allows multiple values, then those values can be stored in another table. For instance, the values could be available in a table-valued parameter that was passed into the stored procedure, or they could be inserted into a temporary table that was filled by splitting a comma-separated list in a varchar(max) parameter. The actual query then uses either an IN predicate or the equivalent EXISTS predicate to filter on the requested values. When using this method to filter a table with a columnstore index, this introduces two problems: the filter cannot be used for rowgroup elimination so that the entire table is read, and in many cases the query execution will also fall back into row mode. Both these problems apply to SQL Server 2012 only.
For this problem, there is a very easy workaround. Instead of writing this query with an IN predicate or an EXISTS predicate, we could write it using a JOIN. The JOIN query returns the same results as long as you can be sure that there are no duplicates in the table that holds the values to be selected. But with the join, you will always get both rowgroup elimination and batch mode execution.
USE ContosoRetailDW;
GO
-- Temporary table for promotion selection
CREATE TABLE #Selection
(PromotionKey int NOT NULL);
INSERT INTO #Selection (PromotionKey)
VALUES (2), (40), (5), (22), (18), (5);
SET STATISTICS TIME ON;
-- Standard query using IN - row mode and no rowgroup elimination
SELECT dp.ProductName,
dd.CalendarQuarter,
SUM(fos.SalesQuantity) AS QuantitySold
FROM dbo.FactOnlineSales AS fos
INNER JOIN dbo.DimDate AS dd
ON dd.Datekey = fos.DateKey
INNER JOIN dbo.DimProduct AS dp
ON dp.ProductKey = fos.ProductKey
WHERE fos.PromotionKey IN (SELECT PromotionKey
FROM #Selection)
GROUP BY dp.ProductName,
dd.CalendarQuarter
ORDER BY dp.ProductName,
dd.CalendarQuarter;
-- Using a join instead returns the same results faster
WITH DistinctSelection
AS (SELECT DISTINCT PromotionKey
FROM #Selection)
SELECT dp.ProductName,
dd.CalendarQuarter,
SUM(fos.SalesQuantity) AS QuantitySold
FROM dbo.FactOnlineSales AS fos
INNER JOIN dbo.DimDate AS dd
ON dd.Datekey = fos.DateKey
INNER JOIN dbo.DimProduct AS dp
ON dp.ProductKey = fos.ProductKey
INNER JOIN DistinctSelection AS s
ON s.PromotionKey = fos.PromotionKey
GROUP BY dp.ProductName,
dd.CalendarQuarter
ORDER BY dp.ProductName,
dd.CalendarQuarter;
SET STATISTICS TIME OFF;
DROP TABLE #Selection;
Listing 11-1: Replacing IN (or EXISTS) with a join
The code in listing 11-1 allows you to see the problem with IN and how one might work around it by using a JOIN. Because there are duplicates in the #Selection table, I had to put in a CTE (common table expression) to prevent duplicates in the results. If you can be sure that there are no duplicates (for instance because there is a PRIMARY KEY or UNIQUE constraint on the selection table), then you can join directly to the selection table without the need for any CTE at all.
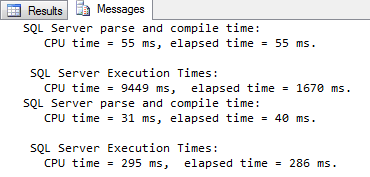
Figure 11-1: Using a join is much faster than using IN
The second version of the query is only slightly more complex than the first, but it performs much better. As you can see above, the first runs in 1.7 seconds while burning 9.4 seconds of CPU time on my system; the second version finishes in 0.3 seconds and uses just 0.3 seconds CPU.
NOT IN and NOT EXISTS
This problem is similar to the one before. The only difference is that this time the values in the selection table should be excluded instead of included. This problem is typically handled similarly to the one before, this time using NOT IN or NOT EXISTS. And again, that query construction will prevent both predicate pushdown and batch mode execution on SQL Server 2012.
One way to work around this is to first get a list of all distinct values that exist in the column you are selecting on, remove the values in the selection list, then use the remaining values in the WHERE clause of the query. This changes the query construction from NOT IN to IN, for which we have already seen the workaround. However, this requires an extra scan of the fact table to find all possible values, and if you are excluding only a few special customers, then the produced list of customers to include can become very long. Finally, if the fact table allows NULL values in the selection column, then this rewrite causes incorrect results.
There is however an alternative method. This method uses the same basic idea as the workarounds you saw in the previous level: find a way to do as much work as possible in batch mode, then aggregate down as far as possible and accept that the rest of the work on a much smaller data set will be done in row mode. The code in listing 11-2 demonstrates both the performance issue with NOT EXISTS and this rewrite method.
USE ContosoRetailDW;
GO
-- Temporary table for promotion selection
CREATE TABLE #Selection
(PromotionKey int NOT NULL);
INSERT INTO #Selection (PromotionKey)
VALUES (1), (40), (5), (22), (18), (5), (8), (17);
SET STATISTICS TIME ON;
-- Standard query using NOT EXISTS
SELECT dp.ProductName,
dd.CalendarQuarter,
SUM(fos.SalesQuantity) AS QuantitySold
FROM dbo.FactOnlineSales AS fos
INNER JOIN dbo.DimDate AS dd
ON dd.Datekey = fos.DateKey
INNER JOIN dbo.DimProduct AS dp
ON dp.ProductKey = fos.ProductKey
WHERE NOT EXISTS
(SELECT *
FROM #Selection AS s
WHERE s.PromotionKey = fos.PromotionKey)
GROUP BY dp.ProductName,
dd.CalendarQuarter
ORDER BY dp.ProductName,
dd.CalendarQuarter;
-- Using NOT EXISTS after aggregation is much faster
WITH AllAggregated
AS (SELECT dp.ProductName,
dd.CalendarQuarter,
fos.PromotionKey,
SUM(fos.SalesQuantity) AS QuantitySold
FROM dbo.FactOnlineSales AS fos
INNER JOIN dbo.DimDate AS dd
ON dd.Datekey = fos.DateKey
INNER JOIN dbo.DimProduct AS dp
ON dp.ProductKey = fos.ProductKey
GROUP BY dp.ProductName,
dd.CalendarQuarter,
fos.PromotionKey)
SELECT ProductName,
CalendarQuarter,
SUM(QuantitySold) AS QuantitySold
FROM AllAggregated AS aa
WHERE NOT EXISTS
(SELECT *
FROM #Selection AS s
WHERE s.PromotionKey = aa.PromotionKey)
GROUP BY ProductName,
CalendarQuarter
ORDER BY ProductName,
CalendarQuarter;
SET STATISTICS TIME OFF;
DROP TABLE #Selection;
Listing 11-2: Speeding up NOT IN (or NOT EXISTS)
The trick used here is that, instead of filtering individual rows from the fact table, we now filter entire groups after aggregation. The original query groups by ProductName and CalendarQuarter; at that level it is impossible to filter on PromotionKey. That’s why the first phase has to add the PromotionKey to the GROUP BY; after this first stage of aggregation the result is then filtered using NOT IN, and the remaining data is then further aggregated to produce the final result. Note that for this is the same local-global aggregation pattern used in Level 10, so the same guidelines for handling various aggregates apply.
Obviously, because we force SQL Server to first aggregate all data before applying the filter, there is no way that rowgroup elimination can ever be used in this workaround. Also because we had to add an extra level to the first GROUP BY, the number of rows left when falling back to row mode is higher than in previous examples – just under 100,000 in this case. Because of this, you should not use this rewrite on SQL Server 2014 or newer, where the original query runs (slightly) faster than the rewrite. However, on SQL Server 2012 this rewrite does result in a significant speed increase because it allows the joins for the 12.6 million rows and the local aggregation to all operate in batch mode; only the filtering and the global aggregation of the remaining less than 100,000 rows requires row mode execution.
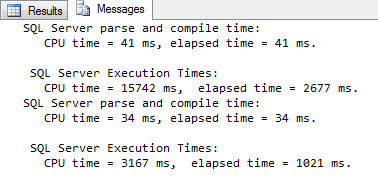
Figure 11-2: Using local-global aggregation makes NOT EXISTS faster
As shown in figure 11-2, the original query took 2.7 seconds and used 15.7 seconds CPU time on my system; after the rewrite the query finished in 1.0 seconds and used 3.2 seconds of CPU.
OR in the WHERE clause
For any type of table and any type of index, a WHERE clause that uses OR can cause problems. Columnstore indexes are no exception. In this case, the problem is not related to execution mode (you will see batch mode if the OR condition is the only problematic element in your query), but you do lose rowgroup elimination. When each of the individual filters is very selective, then this can still affect query performance, and this is a problem that affects performance on every version of SQL Server.
An alternative approach would be to once more use local-global aggregation. For example, if you have a query that reports on products that are red or expensive, then you can instead use two queries, one for all red products and another for all expensive products, then combine the results. But that would count some products twice: items that are both red and expensive are included in both results. To prevent that, you have to remove those from one of the two. This is shown in listing 11-3, where you first see a query with OR, and then the same query rewritten to use local-global aggregation on two sets: red products and expensive non-red products. Note the handling of NULL values in the second part of this query; if a column does not allow NULL values then this can be removed (making the query even faster).
USE ContosoRetailDW;
GO
SET STATISTICS TIME ON;
-- A simple query using OR
SELECT dp.ProductName,
dd.CalendarQuarter,
SUM(fos.SalesQuantity) AS QuantitySold
FROM dbo.FactOnlineSales AS fos
INNER JOIN dbo.DimDate AS dd
ON dd.Datekey = fos.DateKey
INNER JOIN dbo.DimProduct AS dp
ON dp.ProductKey = fos.ProductKey
WHERE dp.ColorName = 'Red'
OR fos.UnitCost > 500
GROUP BY dp.ProductName,
dd.CalendarQuarter
ORDER BY dp.ProductName,
dd.CalendarQuarter;
-- A much longer but in this case also faster version
WITH RedProducts
AS (SELECT dp.ProductName,
dd.CalendarQuarter,
SUM(fos.SalesQuantity) AS QuantitySold
FROM dbo.FactOnlineSales AS fos
INNER JOIN dbo.DimDate AS dd
ON dd.Datekey = fos.DateKey
INNER JOIN dbo.DimProduct AS dp
ON dp.ProductKey = fos.ProductKey
WHERE dp.ColorName = 'Red'
GROUP BY dp.ProductName,
dd.CalendarQuarter)
, ExpensiveProducts
AS (SELECT dp.ProductName,
dd.CalendarQuarter,
SUM(fos.SalesQuantity) AS QuantitySold
FROM dbo.FactOnlineSales AS fos
INNER JOIN dbo.DimDate AS dd
ON dd.Datekey = fos.DateKey
INNER JOIN dbo.DimProduct AS dp
ON dp.ProductKey = fos.ProductKey
WHERE fos.UnitCost > 500
AND ( dp.ColorName <> 'Red'
OR dp.ColorName IS NULL)
GROUP BY dp.ProductName,
dd.CalendarQuarter)
, ResultsCombined
AS (SELECT ProductName, CalendarQuarter, QuantitySold
FROM RedProducts
UNION ALL
SELECT ProductName, CalendarQuarter, QuantitySold
FROM ExpensiveProducts)
SELECT ProductName,
CalendarQuarter,
SUM(QuantitySold) AS QuantitySold
FROM ResultsCombined
GROUP BY ProductName,
CalendarQuarter
ORDER BY ProductName,
CalendarQuarter;
SET STATISTICS TIME OFF;
Listing 11-3: Avoiding OR in a query
The execution plans shown in figure 11-3 were generated on SQL Server 2014. The percentages shown (which are always based on the estimated cost, even in an actual execution plan) seem to indicate that the rewrite will be almost twice as slow as the simple original version of the query. (The optimizer also suggests adding a nonclustered rowstore index to improve performance. This is a bad suggestion. If you add the suggested index it is not even used, and when you add a hint to force the use of this index it reduces performance.)
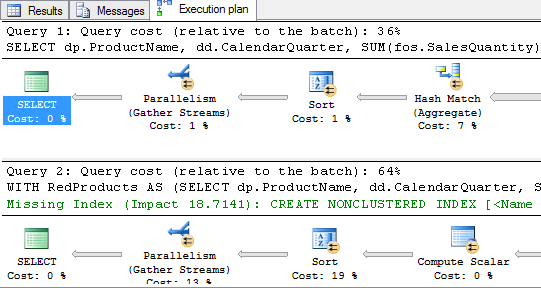
Figure 11-3: Execution plans for the simple OR and the long rewrite
The estimated query has always been a dangerous and misleading tuning tool; this is even worse when columnstore indexes are involved. The estimated cost is based on assumptions and these assumptions don’t sufficiently take into account the savings of reading from columnstore indexes and of executing in batch mode. That is why, instead of looking at the percentages shown above, I prefer to go by the output generated by SET STATISTICS IO. As shown in figure 11-4, estimated costs are indeed completely wrong in this case: the elapsed time is reduced from 0.75 to just 0.25 seconds, and the CPU time used is down from over 0.8 seconds to less than 0.2.
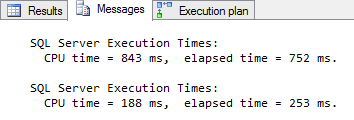
Figure 11-4: Actual elapsed and CPU time of the two queries
Rewriting the query improves performance of this particular query, but that will not always be the case; it depends on selectivity of the filters and on the data distribution. For other conditions, the original version of the query using a simple OR would be faster than the rewrite. You should always test both variations on realistic test data and only use the rewrite if it improves performance in your specific case. Also, because data can change over time, it is important to periodically revisit these queries to verify if the implemented version is still the best option.
Aggregation without GROUP BY
Probably the most surprising limitation of batch mode execution in SQL Server 2012 is that it cannot handle aggregates without a GROUP BY in the query. So when a data analyst runs a few quick queries to get for instance minimum and maximum value in a column or number of rows, just to get a first impression of the data, those queries will run slower than the much more complicated queries used for actual reports. The reason for that speed difference is that the reports have GROUP BY in their queries so that aggregation (and most of the rest of the execution plan) can be performed in batch mode; the simple query used to get a first feel for the data has no GROUP BY and hence falls back to row mode.
It is possible to work around this limitation by using local-global aggregation: first grouping by any available column for the local aggregation, and then doing global aggregation without GROUP BY on those results. But in this specific case there is a far easier way to work around it: just add a “fake” GROUP BY clause, using an expression that is redundant because it always returns the same value, but that the optimizer doesn’t recognize as redundant. Surprisingly enough, simply subtracting a numeric column from itself is sufficient for this purpose. (Do make sure to use a column that doesn’t allow NULL values, otherwise you’ll end up with two rows in the result set).
USE ContosoRetailDW;
GO
SET STATISTICS TIME ON;
-- Aggregation without GROUP BY runs in row mode
SELECT MIN(TotalCost),
MAX(TotalCost),
COUNT(*)
FROM dbo.FactOnlineSales;
-- The dummy GROUP BY enables batch mode, making the query faster
SELECT MIN(TotalCost),
MAX(TotalCost),
COUNT(*)
FROM dbo.FactOnlineSales
GROUP BY SalesQuantity - SalesQuantity;
SET STATISTICS TIME OFF;
Listing 11-4: Adding a fake GROUP BY enables batch mode
The code in listing 11-4 demonstrates the performance benefit you can get from adding a fake GROUP BY clause. In order to prevent your successor from declaring you crazy you might want to add a short comment before checking this code in, pointing out that this seemingly bizarre GROUP BY actually improves performance of this query from 0.9 seconds to 0.05 seconds, as shown in figure 11-5.
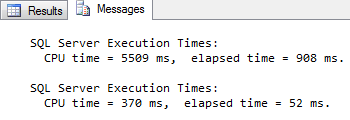
Figure 11-5: Performance gained by adding a fake GROUP BY
A side effect of this rewrite is a significant increase in the memory that is required to run the query. The original query needs just 136 KB, but the faster rewrite requires a memory grant of over 45,000 KB as shown in figure 11-6 below.
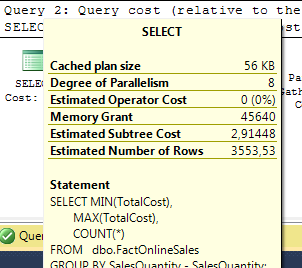
Figure 11-6: The faster query has a higher memory grant
Any database server that seriously uses columnstore indexes should have lots of memory so this increased memory grant should only be a real issue if you have huge number of queries of this type running at the same time.
Aggregates with DISTINCT
Probably the worst offender for performance with columnstore indexes, not just on SQL Server 2012 but on SQL Server 2014 as well, is combining two or more different aggregates with DISTINCT in a single query. This is caused by an incorrect assumption that the optimizer makes about the cost of repeating work.
SQL Server does not have any problems when a query combines multiple aggregates as long as they all operate on the same set. Using DISTINCT in the aggregate changes the set: instead of processing all rows, the set is now reduced to just the distinct values of a specific column. So when, as in the example in listing 11-5, you aggregate both DISTINCT StoreKey as well as DISTINCT CurrencyKey, then SQL Server cannot compute the results in a single pass. It has to first find the input to the aggregates (by performing the joins), then remove duplicate values of StoreKey in order to count the distinct values. And then it has to repeat the process for the second aggregate, but for this is needs to once more start with the original set of data (before removing duplicate StoreKey values).
USE ContosoRetailDW;
GO
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
SELECT dp.ProductName,
dd.CalendarQuarter,
COUNT(DISTINCT fos.StoreKey) AS NumStores,
COUNT(DISTINCT fos.CurrencyKey) AS NumCurrencies
FROM dbo.FactOnlineSales AS fos
INNER JOIN dbo.DimDate AS dd
ON dd.Datekey = fos.DateKey
INNER JOIN dbo.DimProduct AS dp
ON dp.ProductKey = fos.ProductKey
GROUP BY dp.ProductName,
dd.CalendarQuarter
ORDER BY dp.ProductName,
dd.CalendarQuarter;
SET STATISTICS IO OFF;
SET STATISTICS TIME OFF;
Listing 11-5: Using multiple DISTINCT aggregates
Because the optimizer knows that it will need to remove duplicates but then also reuse the original results of the join later, it adds two Table Spool operators in the execution plan. The first of these operators stores a copy of each row it processes in a worktable in tempdb; the second then retrieve those same rows for use in another branch of the plan. The effect of these Table Spool operators is that the results of the join can be reused instead of having to repeat the join process, as shown in figure 11-7.
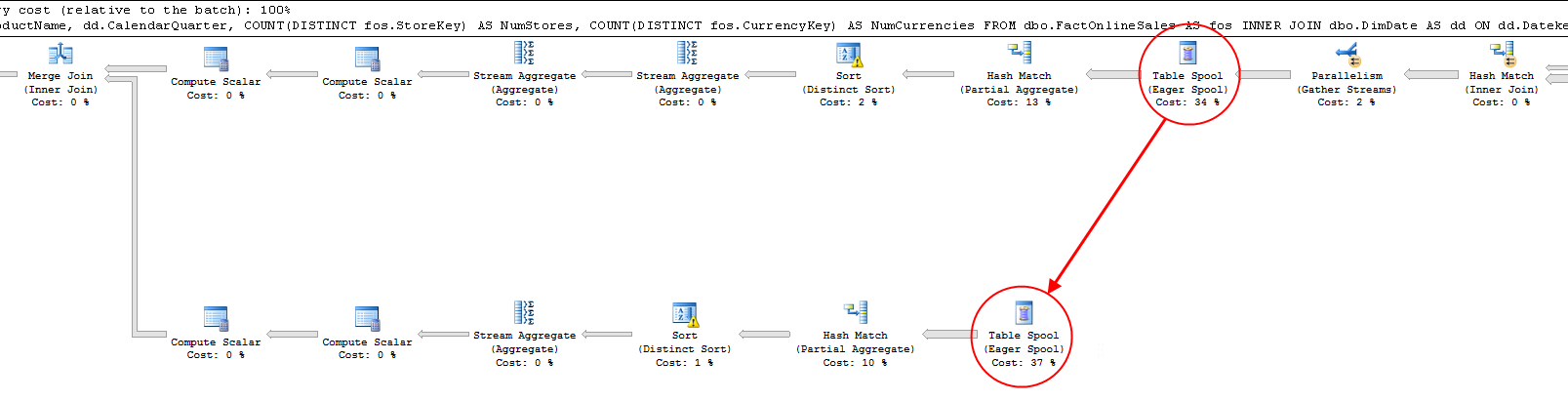 Figure 11-7: SQL Server 2014 execution plan for multiple DISTINCT aggregates
Figure 11-7: SQL Server 2014 execution plan for multiple DISTINCT aggregates
Now while this optimization trick might be valid in some cases when only rowstore indexes are involved, the addition of columnstore indexes and batch mode execution change the situation. Because the join itself can run in batch mode, repeating that join is relatively cheap. On the other hand, the Table Spool is quite expensive. Not only because it runs in row mode, but also because it has to store each row individually in a work table. When executing the query in listing 11-5, SQL Server needs at least 1.4 GB in tempdb – the space required to store the over 12.6 million rows produced by the join. You can see that in figure 11-8, which shows the execution statistics when I executed this query.

Figure 11-8: Execution stats on SQL Server 2014 for multiple DISTINCT aggregates
This query took almost four minutes to run on my laptop. The main reason for this execution time is the “Worktable”, the storage area used by the table spool, with over 44 million logical reads. (Most of those reads are actually generated while building the spool; reading from the spool takes “only” about 600,000 logical reads). So in this specific case, the optimization pattern used by the optimizer actually causes a terrible performance degradation.
Listing 11-6 shows how to work around this particular problem. Instead of computing the two aggregates in a single query, I use two separate queries for each of the two aggregations, and then simply join the results together. The shape of the execution plan looks similar to that of the original plan, but because the optimizer doesn’t recognize the joins as equal it will not try to “improve” performance by using a Table Spool; instead it simply executes the same query twice. It also doesn’t try to store huge amounts of data in tempdb, and if you are running SQL Server 2014 this will also enable the specific performance improvement that have been made for queries with a single DISTINCT aggregate.
USE ContosoRetailDW;
GO
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
WITH NumStores
AS (SELECT dp.ProductName,
dd.CalendarQuarter,
COUNT(DISTINCT fos.StoreKey) AS NumStores
FROM dbo.FactOnlineSales AS fos
INNER JOIN dbo.DimDate AS dd
ON dd.Datekey = fos.DateKey
INNER JOIN dbo.DimProduct AS dp
ON dp.ProductKey = fos.ProductKey
GROUP BY dp.ProductName,
dd.CalendarQuarter)
, NumCurrencies
AS (SELECT dp.ProductName,
dd.CalendarQuarter,
COUNT(DISTINCT fos.CurrencyKey) AS NumCurrencies
FROM dbo.FactOnlineSales AS fos
INNER JOIN dbo.DimDate AS dd
ON dd.Datekey = fos.DateKey
INNER JOIN dbo.DimProduct AS dp
ON dp.ProductKey = fos.ProductKey
GROUP BY dp.ProductName,
dd.CalendarQuarter)
SELECT ns.ProductName,
ns.CalendarQuarter,
ns.NumStores,
nc.NumCurrencies
FROM NumStores AS ns
INNER JOIN NumCurrencies AS nc
ON nc.ProductName = ns.ProductName
AND nc.CalendarQuarter = ns.CalendarQuarter
ORDER BY ns.ProductName,
ns.CalendarQuarter;
SET STATISTICS IO OFF;
SET STATISTICS TIME OFF;
Listing 11-6: A workaround for multiple DISTINCT aggregates
As shown in figure 11-9 below, execution time on my test system dropped to just 1.3 seconds, over 170 times faster than the original query. The rewrite may be ugly, but in my experience the performance gain makes this more than worthwhile.
 Figure 11-9: Over 170 times faster after rewriting the query
Figure 11-9: Over 170 times faster after rewriting the query
Note that the example used here focuses on the effect of combining two different DISTINCT aggregates. In queries that combine a single DISTINCT aggregate with a “normal” (not distinct) aggregate, similar problems occur (though depending on the rest of the query and the version of SQL Server it will not always be in the form of a Table Spool). In such cases, the same rewrite pattern as for multiple DISTINCT aggregates should be used.
Using the OVER clause
Another construct that can cause really bad performance when used in combination with columnstore indexes is the OVER clause. This clause was introduced in SQL Server 2005 and greatly expanded in SQL Server 2012, and it enabled much cleaner and simpler ways to solve many common query problems. However, the operators used in the query execution plan didnt support batch mode in SQL Server 2012 or 2014, and depending on how exactly the OVER clause is used you might also see a Table Spool operator in the execution plan.
Although it is always possible to avoid the OVER clause (by returning to the kludgy SQL code used before the OVER clause was added), that is not guaranteed to help performance as the workaround can introduce its own issues. And if you are used to the OVER clause, you will sometimes have to think out of the box. There are many ways in which the OVER clause can be used and not just a single way to replace it, but I do want to present one common example.
USE ContosoRetailDW;
GO
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
WITH SalesWithCount
AS (SELECT ProductKey,
SalesQuantity,
COUNT(*) OVER (PARTITION BY CustomerKey) AS SalesPerCustomer
FROM dbo.FactOnlineSales)
SELECT ProductKey,
SUM(SalesQuantity) AS QuantitySold
FROM SalesWithCount
WHERE SalesPerCustomer > 500
GROUP BY ProductKey
ORDER BY ProductKey;
WITH BigCustomers
AS (SELECT CustomerKey
FROM dbo.FactOnlineSales
GROUP BY CustomerKey
HAVING COUNT(*) > 500)
SELECT fos.ProductKey,
SUM(fos.SalesQuantity) AS QuantitySold
FROM dbo.FactOnlineSales AS fos
INNER JOIN BigCustomers AS bc
ON bc.CustomerKey = fos.CustomerKey
GROUP BY fos.ProductKey
ORDER BY fos.ProductKey;
SET STATISTICS IO OFF; SET STATISTICS TIME OFF;Listing 11-7: An example of avoiding the OVER clause
The query in listing 11-7 presents sales data aggregated by product, but only for our best customers – those who have at least 500 sales lines. The first query is how most people would write it, using the OVER clause to implement the filter for best customers without having to do a second pass over the base table. The second query is how we used to do this before 2005, with no other option than to do two passes over the table. And when a columnstore option is involved, then this second version is also how we should do it now, as it performs much faster.

Figure 11-10: Performance gained by avoiding the OVER clause
When testing on SQL Server 2014, the rewrite introduces a second scan of the columnstore index (as shown by the higher scan count and lob logical reads counts in figure 11-10), but the huge number of I/O’s to the worktable is gone, and execution time for the query was reduced from 30.4 seconds to 0.3 seconds.
Sorting data
The last limitation for batch mode execution that I want to point out is the Sort operator, used in execution plans to sort data. This operator does not support batch mode in either SQL Server 2012 or SQL Server 2014.
When an ORDER BY is used in combination with a GROUP BY, as in most of the examples in this and the previous level, then this is not an issue: the Sort operator only processes the small number of rows left after aggregation so the fallback to row mode does not have a significant effect on performance.
But there are exceptions. The query in listing 11-8 is similar to the second query in listing 11-7, however we are now not reporting on products sold to our best customers, but on products sold in the biggest orders. And the threshold for orders being “big” is not fixed, we simply want to select the 5000 orders with the highest total cost.
USE ContosoRetailDW;
GO
WITH BigOrders
AS (SELECT TOP(5000)
SalesOrderNumber
FROM dbo.FactOnlineSales
GROUP BY SalesOrderNumber
ORDER BY SUM(TotalCost) DESC)
SELECT fos.ProductKey,
SUM(fos.SalesQuantity) AS QuantitySold
FROM dbo.FactOnlineSales AS fos
INNER JOIN BigOrders AS bo
ON bo.SalesOrderNumber = fos.SalesOrderNumber
GROUP BY fos.ProductKey
ORDER BY fos.ProductKey;
Listing 11-8: Bad performance caused by sorting
Technically you could say that even in this example we are still sorting after aggregation, on SalesOrderNumber in this case. However, there are lots of distinct SalesOrderNumber values (almost 1.7 million) so this query would probably have benefited if the Sort operator had a batch mode implementation.
Unfortunately, there is no way to work around this specific limitation. If you really need the 5000 orders with the highest total cost, then there is no other way then to compute total cost for all orders and sort the results. In this case, the performance you get from the query as written (over 30 seconds on both my SQL Server 2012 and my SQL Server 2014 test systems) is the best you will get.
Conclusion
There are lots of limitations to batch mode in SQL Server 2012. Some of those limitations no longer apply in SQL Server 2014, others still do. And while reading from a columnstore index in itself already improves performance over reading from rowstore indexes, you are not getting the best possible performance if you allow queries to run in row mode.
In both this level and the previous one I have shown several examples of these limitations. These examples are not an exhaustive list of all cases where a plan can fall back to row mode; I recommend always looking at the execution plans of your queries and checking the execution mode of all operators that run in the sections where large numbers of rows are being processed.
I have also shown how you can often work around these limitations to get the better performance of batch mode. Some of these workarounds can probably be directly applied to your own work. Others may need adaptation to your specific needs. When you are faced with a query that does not use batch mode, remember the two most important basic tricks used in all these workarounds:
- Rewrite the query so that most of the work is done in batch mode. If this changes the logic of the query, then add extra code to compensate for these changes. As long as this extra code works on amuch smaller result set after aggregation, the final result will run faster.
- Split the query into multiple queries that each do some of the work, then combine the aggregated results. Even when the new version of the query makes extra passes over the data, it will still be faster if all of them can run in batch mode.
There are also cases where you may have to apply some out of the box thinking to find a completely different way to express the same query. And there are, unfortunately, some cases that simply cannot be rewritten to use batch mode.
As stated before, it is very important that you choose a rewrite that not only produces the same results on your test data but that you can also prove to be logically equivalent for all possible data. You should also make sure to add in comments that document the rewrite so that others (as well as the future you) are not left wondering why the code is more complex than expected.