
This is the fifth article in a series entitled Stairway to Integration Services. Previous articles in the series include:
- What is SSIS? Level 1 of the Stairway to Integration Services
- The SSIS Data Pump - Level 2 of the Stairway to Integration Services
- Adding Rows in Incremental Loads – Level 3 of the Stairway to Integration Services
- Updating Rows in Incremental Loads – Level 4 of the Stairway to Integration Services
Introduction
In our previous installment (Updating Rows in Incremental Loads – Step 4 of the Stairway to Integration Services) you learned how to transmit updates from the source to the destination. You also learned how to optimize this functionality using set-based updates.
Reviewing Incremental Loads
Remember, incremental loads in SSIS have three use cases:
- New rows – add rows to the destination that have been added to the source since the previous load.
- Updated rows – update rows in the destination that have been updated in the source since the previous load.
- Deleted rows – remove rows from the destination that have been deleted from the source.
In this article, we’ll continue to build Incremental Load functionality in SSIS by focusing on deleting rows that have been removed from the source since they were loaded into the destination.
Delete Missing Rows
To accomplish deleting rows in an Incremental Load, we basically reverse the Update operation in a subsequent Data Flow Task.
Let’s begin by setting up the test condition. Thinking about it a bit, I realize one way to test this is to have a row in the destination table that does not exist in the source. This will be as if a row inserted into the destination earlier has been removed from the source. I can set this up by opening SSMS and executing the following T-SQL statement:
Use AdventureWorks
go
Insert Into dbo.Contact
(FirstName, MiddleName, LastName, Email)
Values
('Andy', 'Ray', 'Leonard', 'andy.leonard@gmail.com')Now, when the Incremental Load Delete logic executes it should detect this record is missing from the source and delete this row from the destination. But is that our only use case? No. In fact, we have a golden opportunity right now to test the impact of an additional record in the destination table on the existing Incremental Load logic. So let’s test that. Press the F5 key to execute the SSIS package. Examine the Control Flow and Data Flow Task for errors. I see none in the Control Flow and my Data Flow appears as shown:
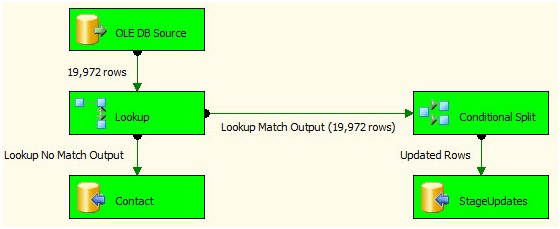
Figure 1
This is as I hoped: The Incremental Load succeeds and doesn’t detect additional New or Updated rows. One last place to check – let’s make sure the Lookup Transformation saw the additional row. To check this, click the Progress tab and search for the number of rows the Lookup Transformation cached:

Figure 2
There are 19,972 rows in the source table (Person.Contact). Adding the record to dbo.Contact brings the count to 19,973, so this is excellent. The Lookup found and cached the additional row, but it didn’t impact the execution of the existing Insert and Update Data Flow logic.
Before we begin adding components to our SSIS package, let’s rename the Data Flow Task to “Insert and Update Rows.” Next, drag another Data Flow task onto the Control Flow and add a Precedence Constraint from the Apply Staged Updates Execute SQL Task to the new Data Flow Task. Rename the new Data Flow “Delete Rows”:
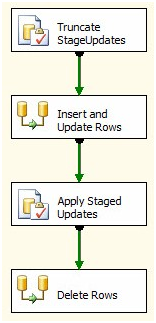
Figure 3
Open the Delete Rows Data Flow Task. Add an OLE DB Source, open its editor, and configure the following properties:
- OLE DB Connection Manager: (local).AdventureWorks
- Data Access Mode: Table or view
- Name of the table or view: dbo.Contact
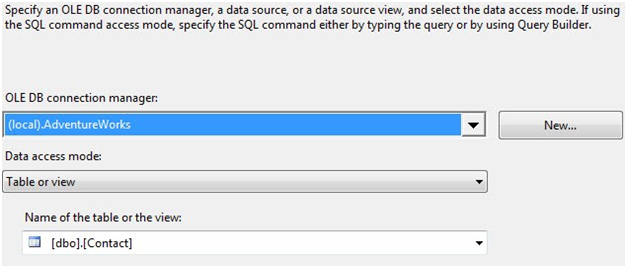
Figure 4
We are using the destination table – dbo.Contact – as the source in this Data Flow Task. Our next step is to use a Lookup Transformation to detect rows in the source that are missing from the destination. This is the exact same process we used when detecting New Rows in the first Data Flow Task. Drag a Lookup Transformation onto the Delete Rows Data Flow Task and connect a Data Flow Path from the OLE DB Source adapter to the Lookup:
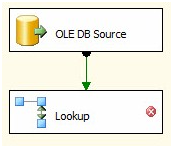
Figure 5
Open the Lookup Transformation Editor and, on the General page, change the “Specify how to handle rows with no matching entries” dropdown to “Redirect rows to no match output”:

Figure 6
On the Connection page, ensure the “OLE DB Connection Manager” dropdown is set to “(local).AdventureWorks”. Select the “Use results of an SQL query” option and enter the following T-SQL statement in the textbox:
Select EmailAddress As Email From Person.Contact
We only need the identifying field – Email – in order to detect rows that are missing from the source table and present in the destination table. Click the Columns page and drag the Email column from the Available Input Columns grid to the Available Lookup Columns grid:
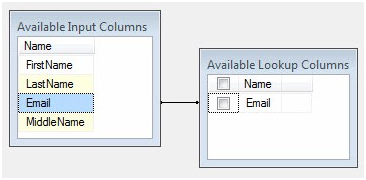
Figure 7
Because we configured the Lookup to redirect unmatched rows to the No Match Output (on the General page), we’re done at this point. If there’s no match between the source (dbo.Contact) and Lookup (Person.Contact) tables, that row will be sent to the No Match Output. Click the OK button to close the Lookup Transformation Editor.
How do we accomplish the actual Delete operation? Well, I could go through the exercise of adding and configuring an OLE DB Command Transformation as we did for the original Update logic, but I bet you already know how that’s going to end (don’t you?). So let’s skip over the middle part and add an OLE DB Destination to the Delete Rows Data Flow Task, and then connect the No Match Output from the Lookup Transformation to it:
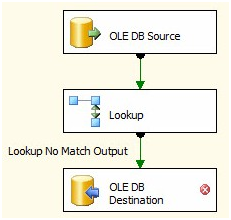
Figure 8
Rename the OLE DB Destination “StageDeletes” and double-click it to open the editor. As before, click the New button beside the “Name of the table or view” dropdown. It should contain the DDL we seek:
CREATE TABLE [StageDeletes] (
[FirstName] nvarchar(50),
[LastName] nvarchar(50),
[Email] nvarchar(50),
[MiddleName] nvarchar(50)
)Click the OK button to close the Create Table window – thus creating the StageDeletes table – and then click the Mappings page to complete the (auto-mapped) configuration of the OLE DB Destination:
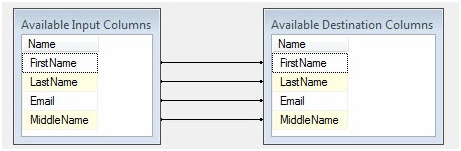
Figure 9
Click OK to close the OLE DB Destination Editor. As before, we need to apply the set-based deletes to the source table; and as before we’ll use a similar set-based and correlated statement to accomplish this. On the Control Flow, add an Execute SQL Task and connect a green Precedence Constraint from the Delete Rows Data Flow Task to the new Execute SQL Task:
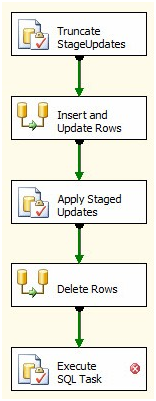
Figure 10
Open the Execute SQL Task Editor and change the following properties:
- Name: Apply Staged Deletes
- Connection: (local).AdventureWorks
- SQLStatement:
Delete src
From Person.Contact src
Join StageDeletes stage
On stage.Email = src.EmailAddressClick the OK button to close the Execute SQL Task Editor. Let’s unit-test this configuration before proceeding. How do we unit-test an SSIS task? Right-click the Apply Staged Deletes Execute SQL Task and click Execute Task:
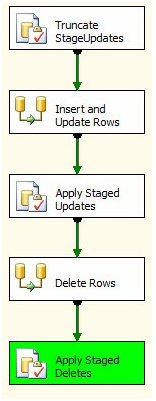
Figure 11
Cool – it succeeds if we’ve configured the task correctly. Stop the BIDS debugger. As with the set-based Updates logic, we need to manage the StageDeletes table. And as before, we’ll truncate it prior to each load, load it inside the Data Flow Task, and leave the records in the table between loads in case we need to view them. There’s no need to create a separate Execute SQL Task for this; we already have a Truncate Execute SQL Task – the Truncate StageUpdates Execute SQL Task. Double-click it to open the editor and add the following T-SQL statement below the existing T-SQL statement:
Truncate Table StageDeletes
The Enter SQL Query window should appear as shown in Figure 12:
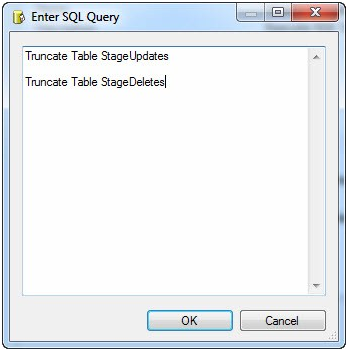
Figure 12
Click the OK button to close the Enter SQL Query window. Before closing the Execute SQL Task’s Editor, change the Name property to “Truncate StageUpdates and StageDeletes”. Click OK to close the editor and press the F5 key to execute the SSIS package. Examine the Control Flow:
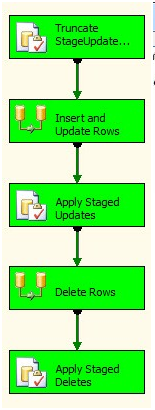
Figure 13
Looks good. Next let’s check the Delete Rows Data Flow Task:
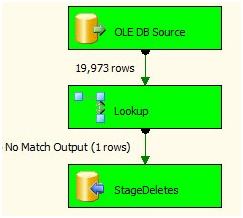
Figure 14
Once again, all is well. Our single row has been deleted from the destination table (dbo.Contact). We can verify this with a test T-SQL query executed in SSMS:
Use AdventureWorks go Select Count(*) As RecCount From Person.Contact Where FirstName = 'Andy' And LastName = 'Leonard'
0 is the result I get; I’ve been deleted. Well, from the database anyway.
Conclusion
We’ve done a lot in this article! We built our first SSIS Design Pattern – the Incremental Load. We learned some introductory examples of ETL testing. We learned about the Lookup Transformation and the Execute SQL Task. All good and important stuff. We designed and built a re-executable SSIS package that, combined with the fact it’s an Incremental Load, can be executed once per month to load records that have changed in the past month. Or it could just as easily be executed every five minutes to pick up changes in the data during that period. How flexible!
:{>

