
In our last installment (Level 1 – BIDS) you learned your way around Business Intelligence Development Studio and you are now itching to build an SSIS package that moves real data!
Introduction
SQL Server Integration Services was built to move data. The Data Flow Task provides this functionality. For this reason, when introducing people to SSIS, I like to start with the Data Flow Task.
The Basics of a Data Flow Task
I believe it helps to start with the basics of an SSIS Data Flow Task:
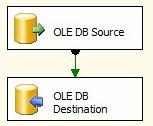
Figure 1
In Figure 1 we see a very simple Data Flow Task: Data is read into the Data Flow task from a database via an OLE DB Source Adapter and written out to a database via an OLE DB Destination Adapter. The Source and Destination Adapters interact with databases and other data stores through Connection Managers. For now let’s focus on the internal operations of the Data Flow Task.
There are three objects in Figure 1:
- OLE DB Source Adapter
- OLE DB Destination Adapter
- A Data Flow Path (the green arrow) connecting the OLE DB Source and OLE DB Destination Adapters
Connection Managers and the OLE DB Source Adapter
The OLE DB Source Adapter connects to a Connection Manager. Connection Managers live in a small tab located at the bottom of the Data Flow editor:
Figure 2
The important thing to know about Connection Managers is this: Connection Managers are a bridge between the SSIS package and external data sources. The Connection Manager handles things like server name and database instance (if applicable), database name, and credentials. The OLE DB Source Adapter handles things like tables and columns.
The OLE DB Source Adapter executes a query against the server / database configured in the Connection Manager, in the context of the credentials supplied in the Connection Manager. A couple important notes:
First, SSIS will never store or save decrypted password fields. If your connection requires a password, and you check the Save My Password (or Save Password, depending on the version of SSIS you’re running) checkbox, and your SSIS package is encrypted.
SSIS will store your password internally and encrypted if you use Windows Authentication, the Connection Manager will connect to the database in the context of the user who executes the package.
The OLE DB Destination Adapter
The OLE DB Destination Adapter also serves as an interface (or bridge) between the Data Flow Task and a Connection Manager. Rows flow into the OLE DB Destination Adapter and are written to the destination table specified in the OLE DB Destination Editor.
The OLE DB Source Adapter brings data into the Data Flow Task; the OLE DB Destination Adapter writes data out of the Data Flow Task.
A Data “Pipeline”
Data Flow Paths connect the Source Adapters, Transformations, and Destination Adapters inside a Data Flow Task. There are no transformations in the simple Data Flow Task in Figure 1 – so the Data Flow Path pipes all the data from the OLE DB Source Adapter into the OLE DB Destination Adapter. We’ll look at transformations in the Data Flow in a later installment.
All components in a Data Flow Task operate on rows of data. A row is the basic unit. Rows are grouped into buffers, and buffers are used to move rows through a data “pipeline”. It’s called a pipeline because rows flow in, then through, and then out of the Data Flow Task.
Data is read into the OLE DB Source Adapter in chunks. A single chunk of data fills one buffer. A buffer of data is processed before the data moves “downstream”.
Play Along At Home!
Open (or create) the SSIS project named My_First_SSIS_Project from What is SSIS? Level 1 of the Stairway to Integration Services.
From the Control Flow toolbox, drag a Data Flow Task onto the Control Flow canvas.
![]()
Figure 3
The Data Flow Task is a Control Flow task, which is also important. Why? Because when you open the Data Flow tab, you see a lot of similarities between the Control Flow and Data Flow Task. For example, there’s a toolbox. And green and red arrow connectors. It’s easy to get confused, especially when you’re first starting to use SQL Server Integration Services.
Right-click the Data Flow Task and click Edit:
Figure 4
This opens the Data Flow tab in BIDS which is the Data Flow Task Editor:
Figure 5
Drag an OLE DB Source adapter from the Data Flow Task toolbox onto the canvas:
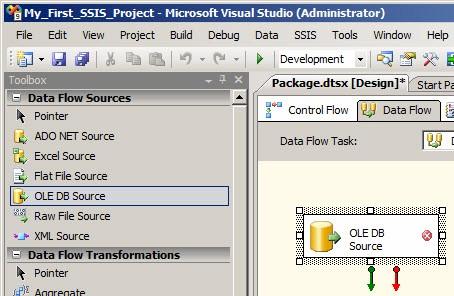
Figure 6
When you first add an OLE DB Source to a Data Flow Task, the component displays with an error icon (the red circle with a white X). You can get more information about the error by viewing the Error List. To open the Error List, click the View dropdown menu in BIDS (Visual Studio), and then click Error List:
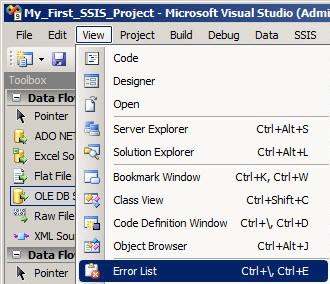
Figure 7
Note you can also hold the Ctrl key and – while holding the Ctrl down – press the \ and E keys to display the Error List. I use these keyboard shortcuts often, but that’s merely a style choice – interact with BIDS in the way that makes you most comfortable.
SSIS validates the things you and I do automatically and as we do them. The Error List contains detailed information about SSIS errors and warnings. As you can see from the screenshot below, SSIS finds two problems with the current package:
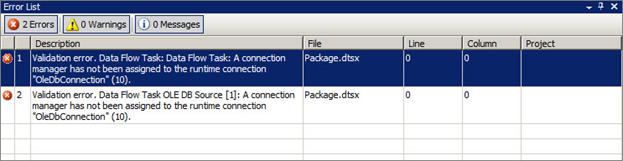
Figure 8
Closer examination reveals a single problem here: There’s no Connection Manager assigned to the OLE DB Source adapter. Why two errors? Error #2 is the actual problem. There is no Connection Manager assigned to the OLE DB Source. Error #1 is caused by Error #2. The clue is in the text immediately following “Validation error.” Error #2 indicates an error with “Data Flow Task OLE DB Source” while error #1 indicates an error with “Data Flow Task: Data Flow Task.” The issue with the OLE DB Source (the fact there’s no Connection Manager currently assigned) is causing a validation error in the Data Flow Task.
Let’s fix it. You can open the OLE DB Source Editor by right-clicking and selecting “Edit…” or by double-clicking the OLE DB Source adapter. I’ve learned I sometimes double-click too slow and enter a text-edit mode for renaming the component. When I do, the component looks like this:
Figure 9
This is great if I want to quickly rename the component, but often what I really want is to open the editor. My trick for working around this is I double-click the icon and not the text portion of the component. This opens the editor:
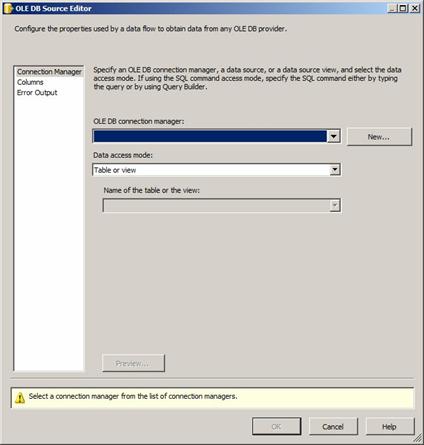
Figure 10
If I have previously defined an OLE DB Connection Manager in the project, I select it from the OLE DB Connection Manager dropdown. In this case, we have no Connection Managers defined. You can stop here, return to the Connection Manager window located beneath the Data Flow Task canvas, and configure a new OLE DB Connection Manager. But don’t do that. Instead, click the New button to the right of the OLE DB Connection Manager dropdown.
This actually creates a new OLE DB Connection Manager and opens the Configure OLE DB Connection Manager editor in one step:
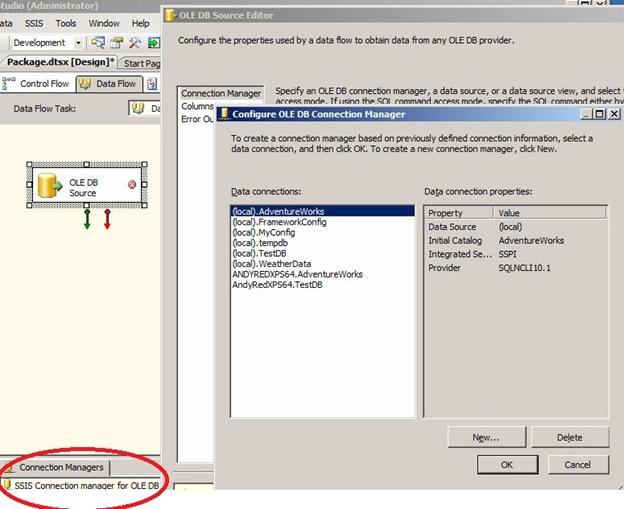
Figure 11
You can see the new Connection Manager in the screenshot above, along with the Configure OLE DB Connection Manager editor. This is a time-saving feature when developing SSIS packages, and I use it regularly.
As you develop SSIS packages on a server, you create connections. The connections you create are stored in your profile and will appear in the Data Connections list in the Configure OLE DB Connection Manager list. If this is the first SSIS package you’ve built, your Data Connections list will be empty:
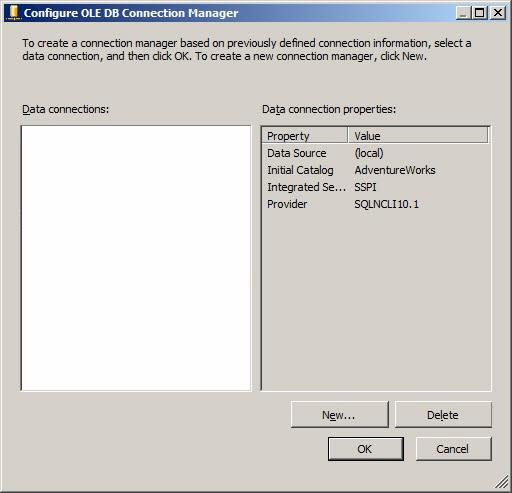
Figure 12
Click the New button here to define a new data connection using the Connection Manager Editor. Earlier I wrote the connection managers handle things like database engine instance and database name. This is where we configure those items:
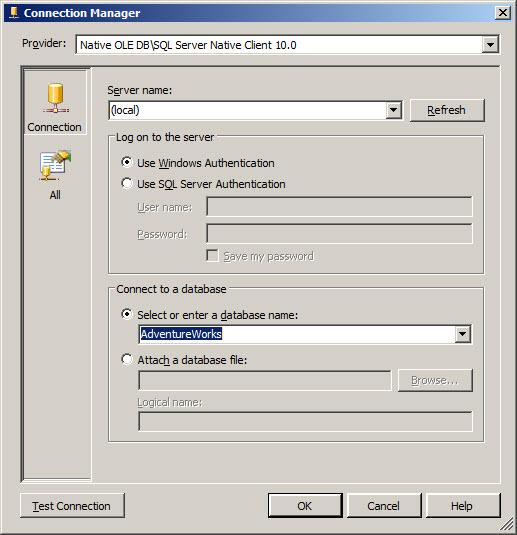
Figure 13
The server name can be typed into or selected from the Server Name dropdown. Once the server name is configured, SSIS actually connects to the server and retrieves a list of databases. You can enter or select the database in the “Select or enter a database name” dropdown. In this case, I connected to the (local) instance of SQL Server and selected the AdventureWorks database.
Once configured, you can test the connection with the Test Connection button:

Figure 14
Click the OK button to close the Test dialog. Click the OK button to close the Connection Manager Editor. Click the OK button to close the Configure OLE DB Connection Manager window. This returns you to the OLE DB Source Editor, which now appears as shown here:
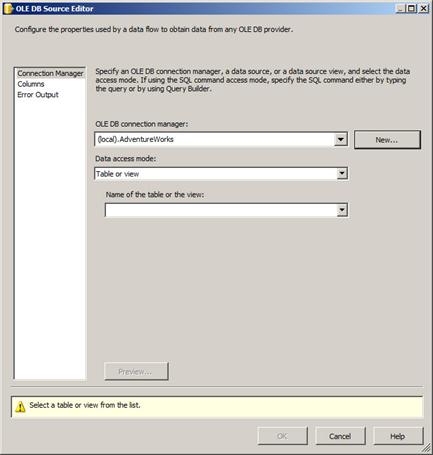
Figure 15
Note the warning message in the lower pane of the OLE DB Source Editor when the Table or View Data Access Mode is selected and no table or view name is specified: “Select a table of view from the list.”
The next decision is: How do we bring in the data? The Data Access Mode property configures this for the OLE DB Source adapter. The options are shown here:
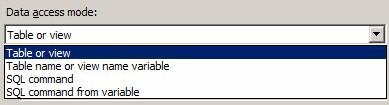
Figure 16
Table or view allows you to select a table or view as the data source from the database configured in the Connection Manager. This is the default option and if you elect to acquire data from the source database using this option, you simply select the table or view name from the “Name of the table or view” dropdown below the Data Access Mode dropdown:
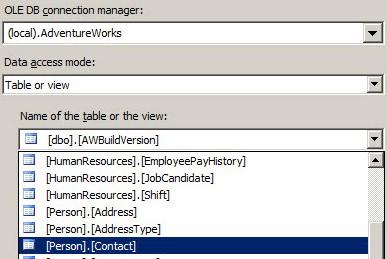
Figure 17
You can also store the name of the table or view in an SSIS variable. This provides some flexibility by allowing dynamic source tables. One thing to keep in mind, however, is OLE DB Source adapters are “coupled” to the Data Flow Task at design time. This means you can change the name of the table, but not the names of the columns or their data types. There are use cases for utilizing this option, but believing you can write a single data flow to load tables with different schemas is a common misunderstanding.
The next set of Data Access Modes allows you to enter SQL statements to query the source:
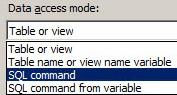
Figure 18
SQL Command and SQL Command From Variable provide a means to query the database configured in the Connection Manager dropdown, returning only the columns you desire from a single table / view or columns from multiple joined tables / views. When you select this option (and please do), the “Name of the table or view” dropdown is replaced by a SQL Command Text textbox:
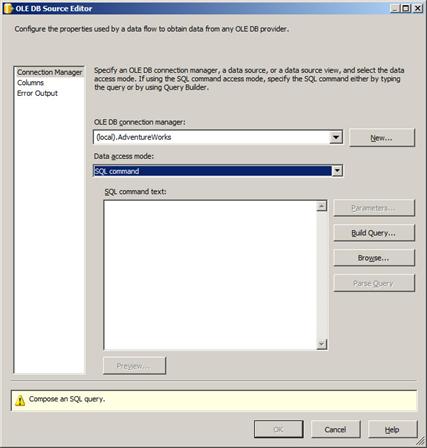
Figure 19
The warning displayed in the lower pane of the OLE DB Source Editor until you begin typing is “Compose an SQL query.” Let’s do that. Enter the following SQL statement:
Select FirstName, MiddleName, LastName, EmailAddress
From Person.Contact
The OLE DB Source Editor will now appear as shown:
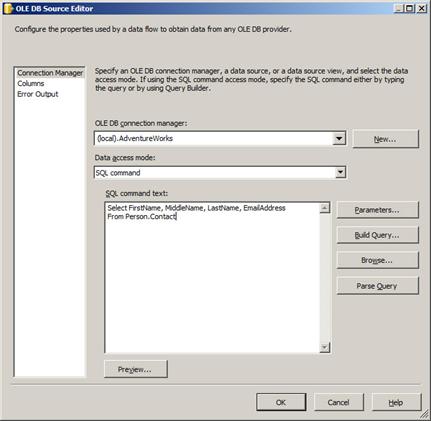
Figure 20
The warning disappeared with the first character you typed into the SQL Command Text textbox.
You can also build an SQL query visually if you prefer. Click the Build Query button to display the Query Builder utility:
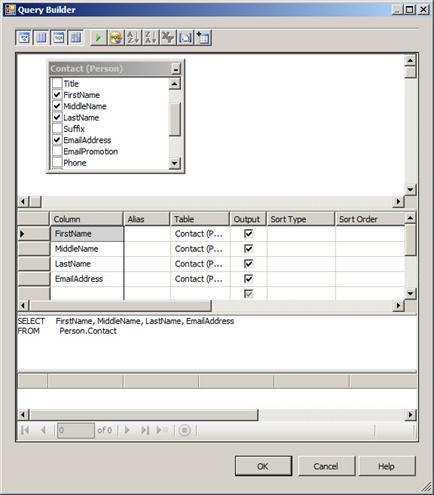
Figure 21
The Query Builder provides a powerful and flexible “Access-like” visual interface. You can add tables by right-clicking the top pane and clicking Add Table, then graphically define relationships between the tables, and then select the fields you wish to include in your SQL statement. You can graphically define criteria and specify sorting as well:
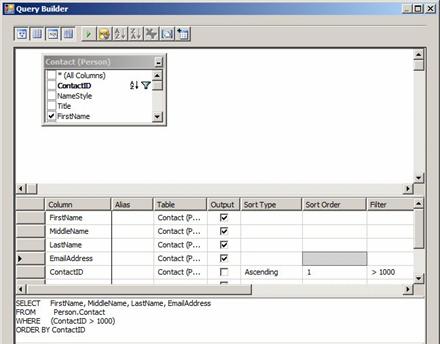
Figure 22
The SQL statement is generated and displayed in the SQL pane. If you enter SQL into this pane the graphics are updated to reflect the statement. As I said previously; this is very powerful and flexible.
If you have the Query Builder open now in our SSIS project, click the Cancel button to close it – we’re sticking with the SQL we entered earlier. In the OLE DB Source Editor, click the Columns page. As shown below, the Columns page displays the columns provided by the Data Access Mode and data selected on the Connection Manager page:
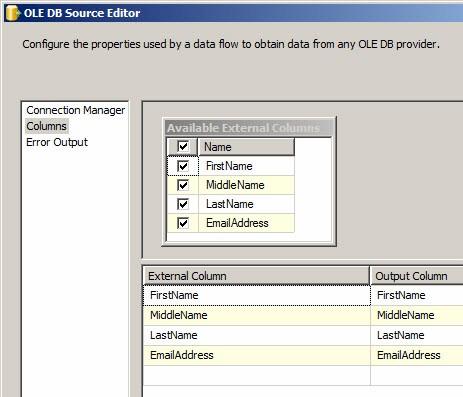
Figure 23
The Available External Columns table lists the columns from the data source. The External Column column in the grid beneath reflects the selected columns. If I deselect MiddleName, the editor appears thus:
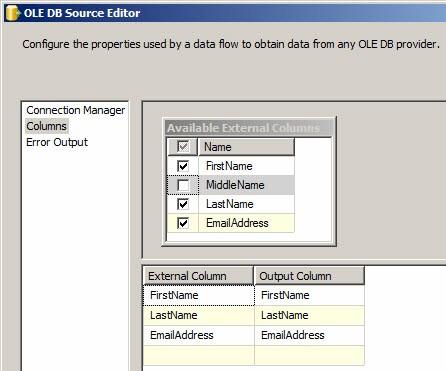
Figure 24
What I’ve done is this: I’ve told the OLE DB Source adapter that I want it to read the MiddleName column into the Data Flow Task when it executes, but I do not want to expose the MiddleName field to any subsequent Data Flow Task transformations or destinations. The MiddleName column is still available if I wish to select it for output from the OLE DB Source adapter, but I cannot use it downstream. This is wasteful and SSIS will provide Warnings during and after execution to this effect. Why is it wasteful? I’m loading data that I will never use. It’s therefore a best practice to only load SSIS data into a Data Flow Task that you plan to use in the following transformations and/or destinations. If I truly do not want to include MiddleName in this Data Flow Task, I can simply remove it from the SQL statement on the Connection Manager page.
I do want to use MiddleName, so let’s check the checkbox beside it before moving forward.
The External Column column in the grid beneath the Available External Columns table is a dropdown that only allows us to select columns from the Available External Columns list:
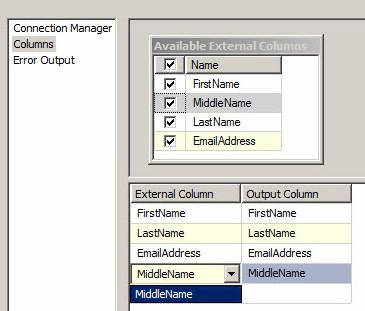
Figure 25
The Output Column grid column allows me to enter an alias for that data column in the remainder of the Data Flow Task. In the example shown below, I’m aliasing the EmailAddress column as Email:
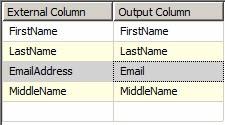
Figure 26
I could also do this in the SQL statement by changing the statement to read:
Select FirstName, MiddleName, LastName, EmailAddress As Email
From Person.Contact
For our first OLE DB Source adapter configuration in our first Data Flow Task, we’re going to stop here. Click the OK button to close the OLE DB Source Editor.
Drag an OLE DB Destination adapter onto the Data Flow Task canvas:
Figure 27
As with the OLE DB Source, the OLE DB Destination arrives with a “Connection Manager not configured” error. We know how to fix this though – double-click the OLE DB Destination to open the editor. Except instead, we get this:
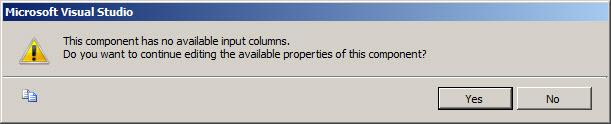
Figure 28
If we think about it, this error makes sense. We are configuring a Destination component and we’ve given it no inputs to write to a destination. I can hear you thinking “How do we provide inputs to write to a destination, Andy?” I’m so glad you asked! First, click the No button to dismiss the Warning dialog.
Click the OLE DB Source adapter. See that green arrow hanging off the bottom? Click that and drag it onto the OLE DB Destination adapter, then let go. It’ll look like this:
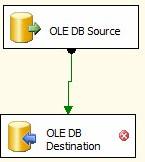
Figure 29
Before we move forward let’s clean this up a bit. You won’t find a screenshot like the above in a book, and you likely won’t find an image like this on a blog post. So how do you make the components in this Data Flow Task look better? First, select the OLE DB Source adapter. Then hold the Ctrl key on select the OLE DB Destination adapter. Next, click the Format dropdown menu, hover over Align, then click Centers:
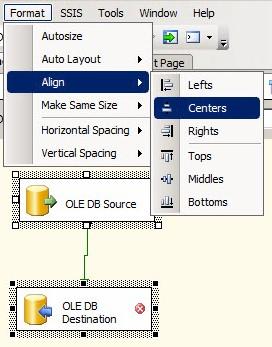
Figure 30
After you click the AlignàCenters, the components are now aligned:
Figure 31
That’s better. You can copy that onto a slide for a presentation!
Let’s take a look at this Data Flow Path we just connected. Right-click the Data Flow Path and click Edit to open the Data Flow Path Editor:
Figure 32
The Data Flow Path Editor has a Metadata page. It displays the contents of the data pipeline connecting the Data Flow components:
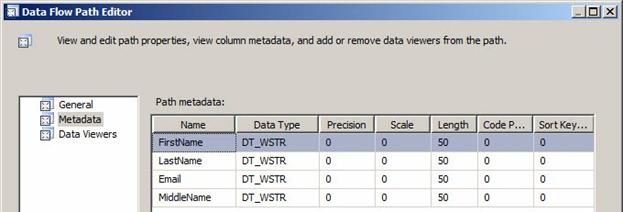
Figure 33
The Data Flow Path metadata displayed here looks similar to a table definition. You can see the name of the column, its data type, and several properties such as the length, precision, scale, and code page. These properties describe the data flowing through the Data Flow Task, and this is a peek under the hood. Data flows along this Data Flow Path from the OLE DB Source to the OLE DB Destination.
Let’s rename the OLE DB Destination. Right-click it and click Rename, then change the name to “Contact”. Double-click the Contact OLE DB Destination adapter to open the editor:
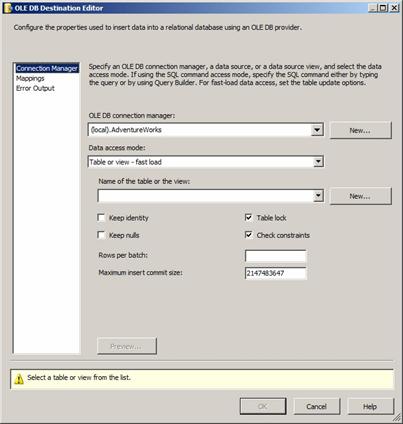
Figure 34
When the OLE DB Destination Editor opens, the OLE DB Connection Manager property defaults to the first available OLE DB Connection Manager. In this case, it’s the (local).AdventureWorks connection manager. As with the OLE DB Source adapter, the New button allows you to create a new OLE DB Connection Manager. We’ll stick with AdventureWorks.
The Data Access Mode property defaults to “Table or view – fast load.” The other options are shown here: 
Figure 35
The two most common selections are “Table or view – fast load” and “Table or view”. The major difference is the fast load option can execute a BULK INSERT statement, while the non-fast load option (“Table or view”) is limited to generating INSERT INTO statements.
If the target table or view exists, you can select it from the “Name of the table or view” dropdown. If the table or view doesn’t exist you can create the table using the New button beside the “Name of the table or view” dropdown. This is super cool and I use it all the time. Click the New button to create a new table or view:
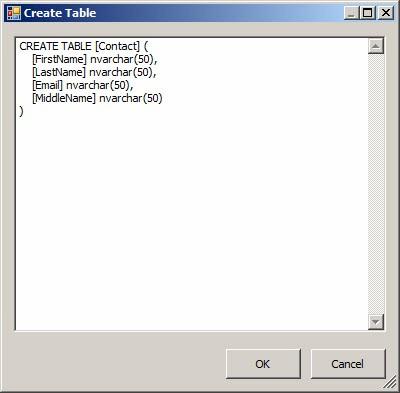
Figure 36
Let’s pick this apart. First, there’s a table name – where did that come from? Oh right, we renamed the OLE DB Destination adapter “Contact” earlier. It’s pretty clever that the name of the component is used in the CREATE TABLE statement, don’t you think? I do. How about the columns? Where did they come from? Oh that’s right – remember the Data Flow Path metadata? But those columns all had the same data type: DT_WSTR. And this statement creates the columns as nvarchar(50). It turns out DT_WSTR is the SSIS equivalent data type of SQL Server’s nvarchar data type. It’s a Unicode string data type. The OLE DB Destination adapter is smart enough to recognize this and build the CREATE TABLE statement accordingly. The column lengths even came from the Data Flow Path metadata. How cool is that?
Click the OK button. When you clicked the OK button, the CREATE TABLE statement was executed and the table created. It now shows up in the OLE DB Destination Editor:
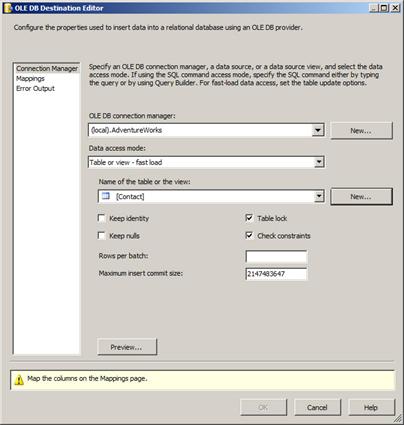
Figure 37
Note the warning in the lower pane: Map the columns on the Mappings page. Click on the Mappings page and observe what happens:
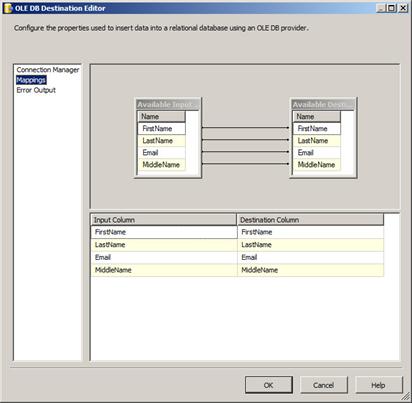
Figure 38
Again, some pretty cool stuff happens here. The tables in the upper right portion contain Available Input Columns and Available Destination Columns. Here’s a better screenshot of that portion of the editor:
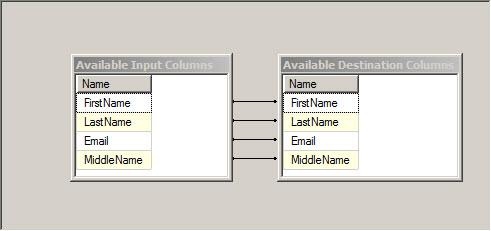
Figure 39
The Available Input Columns are the columns flowing into the OLE DB Destination from the Data Flow Path. The Available Destination Columns are the columns available in the new Contact table we just created in the destination database. Since the column names and data types are the same, the OLE DB Destination Editor auto-maps them. And they’re the same because the Available Destination Columns were built from the metadata for the Available Input Columns. Cool.
Click the OK button to close the OLE DB Destination Editor.
Time to Test!
To test the SSIS package we’ve just constructed, click the Start Debugging button:
Figure 40
Alternately, you can click the DebugàStart Debugging dropdown menu item or press the F5 key:
Figure 41
Note the asterisk (*) next to the name of Package.dtsx above. This indicates the package has changed since it was last saved. I can hear you thinking “Gosh Andy, shouldn’t we have saved this first before executing the debugger?” I’m glad you asked! BIDS saves the package each time you start debugging – how cool is that? If something tragic happens (your laptop battery dies, BIDS locks up, etc.) your work is still saved. Neat.
If you’ve followed this tutorial closely, you will see green boxes:
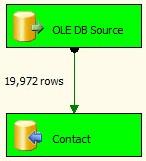
Figure 42
Happiness is green boxes!
Conclusion
Wow. This is a long article. But along the way we’ve discussed a lot of features of the SQL Server Integration Services Data Flow Task. In my opinion, the Data Flow Task is the most important task to master when learning SSIS.
In this article, we:
- Discussed the relationship between Connection Managers and adapters (OLE DB Source and OLE DB Destination)
- Examined the role and some features of Data Flow Paths that connect Data Flow Task components to each and represent the "data flow pipeline"
- Learned about design-time validation and how to view Errors and Warnings.
- Studied some cool time-saving features of the Adapter Editors - you have to love those New buttons!
- Looked at formatting components on the Data Flow canvas so they're aligned.
- Took a peek under the hood of the Data Flow Task, viewing the Data Flow Path metadata.
- Learned how this metadata can be used by the OLE DB Destination to build a CREATE TABLE statement.
That was a lot! Thanks for hanging in here with me. We’re not done with the SSIS Data Flow Task. In the next installment, we’ll dig into transformations and their uses.
:{>
