

In earlier chapters, we learned how to create and query different Microsoft Data Mining algorithms. In this chapter, we will learn how to generate scripts to create Data Mining Structures, Mining Models and create the objects.
XMLA and DMX
We can create Microsoft Data Mining objects using XMLA or DMX. DMX (Data Mining eXtension) is a language to create Mining Structures and Data Mining queries. It is similar to T-SQL (The Transaction Structured Query Language used in relational databases). DMX will be explained in detail in the Part 12 of these series.
XMLA is an extension of the XML to create objects not only for Data Mining objects, but also for multidimensional databases.
Getting Started
Let's start with a simple sample. We will work the project used in the lesson 3, the Adventureworks Project. This time, instead of using SQL Server Data Tools, we will use SQL Server Management Studio. SQL Server Data Tools is used to create the project, but if you want to work with XMLA scripts you need SQL Server Management Studio.
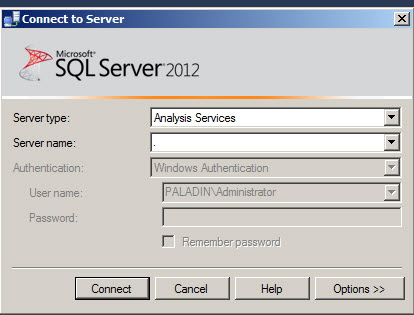
In the Server Type box, select Analysis Services. In the Server Name field, enter the name of the Server with the AdventureWorks database and press the Connect button.
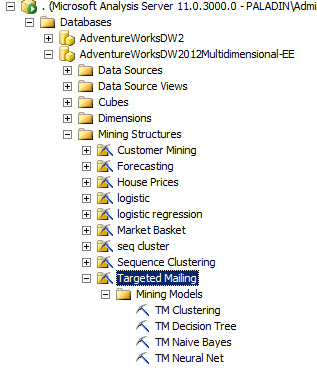
In this sample we will work with the AdventureWorksDW2012Multidimensional-EE Database, and in the Mining Structures with the Targeted Mailing.
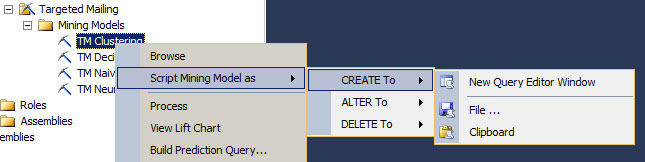
We will generate a XMLA script. To do that, we will right click on the TM Clustering Mining model and select the option Script Mining Model as Create To New Query Editor Window:
The option will create a new Window with the XMLA Code. The first Tag contains the action to Create a new Mining Model Structure: The ParentObject Tag. The databaseID contains the name of the Multidimensional Database. After the parent object, you have the Mining Model. The model contains an ID and a name. Usually, if they are created with a wizard, they have the same values.
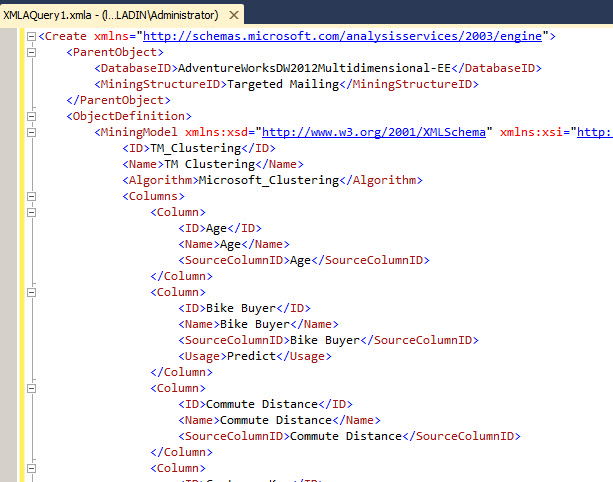
The Algorithm Tag contains the name of the algorithm used. In the columns you will have the Inputs, Predict values and keys. The Column contains the ID, the name, Source ColumnID and the usage. If it is an input, the usage is not specified because it is the default value. The ID and the name are identifiers, they have usually the same values, the sourcecolumnid, is the name of the source column used. In this sample, the Bike Buyer is the Predict value and the Customer Key is the Key.

We are going to modify the MiningModel ID and name to create a new model. We will use the name My_first_XMLA and then we will press the F5 key to execute the script. In the results, you will see an xml file when it is executed successfully.
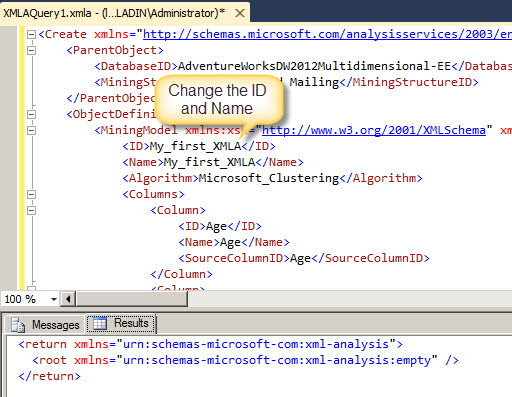
If you refresh the Object Browser, you will notice that the script generated a new Mining Model name My_first_XMLA. This is the name used in the previous step. Right click on the new model and select the Process option to update the new model.
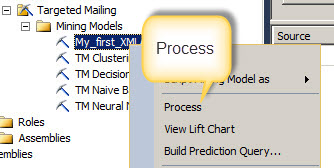
Here you have the Process Window. The process will update the model with the data.
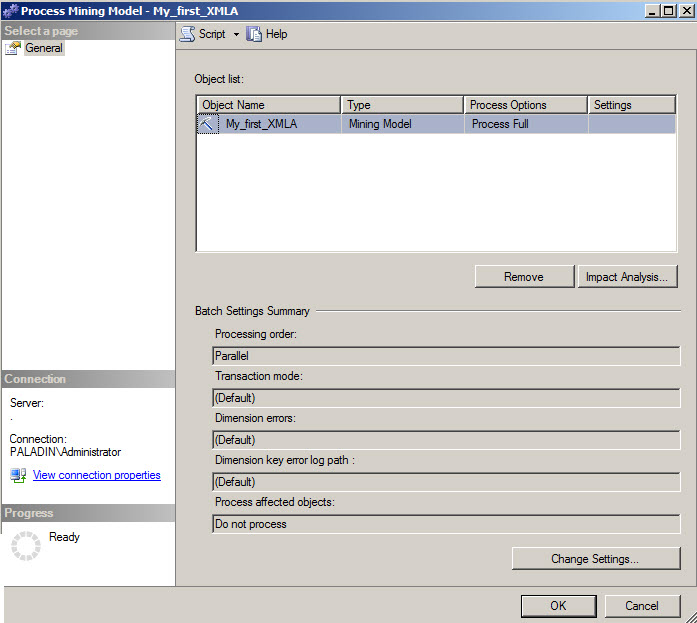
Because, it is a XMLA lesson we do not want to process using the UI. We will create the Process XMLA script with the Script Action to New Query Window Menu.
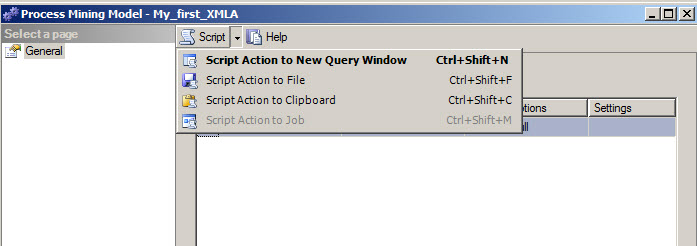
This option will create a XMLA script to process the model. As you can see, the XMLA contain a Batch which is useful to process different models in parallel. A Parallel tag that is used to specify if the we will process in parallel the model. In the Object tag, you have the Database ID, The MiningStructure ID and finally, the ID of the model. In this case the model is My_first_XMLA. You have the Type of Process, which can be Full, ProcessDefault and ProcessClear to clear the information.
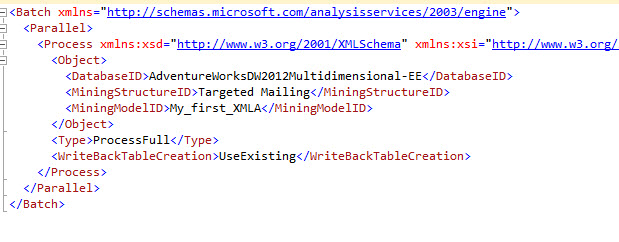
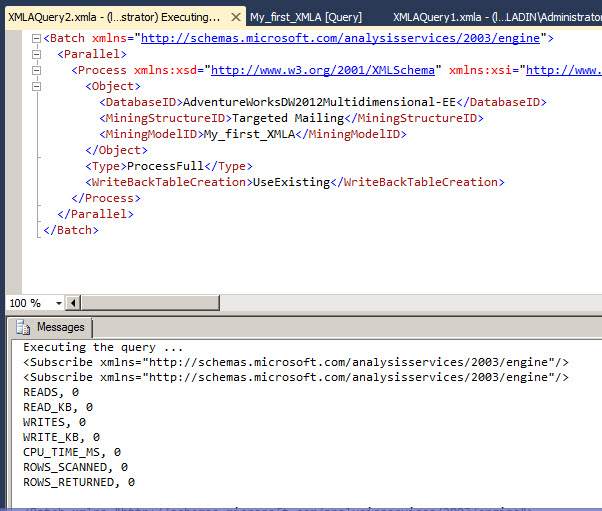
In order to Execute the script press F5
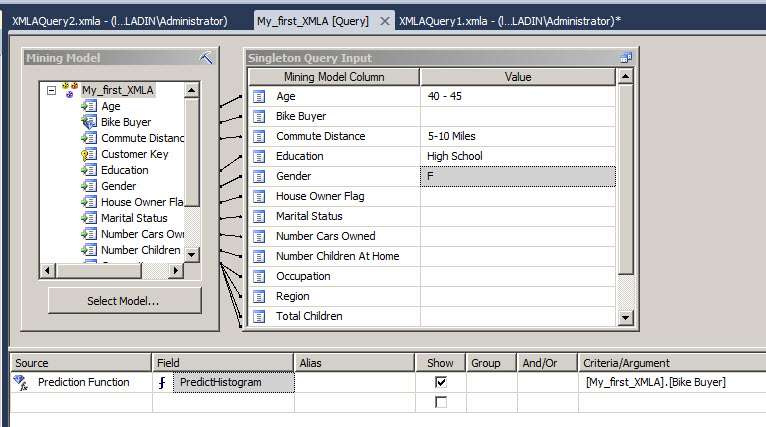
In order to use your mining model you can create your queries using the Build Prediction Query option.
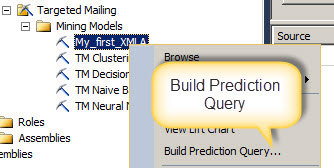
The rest is as we did in the past. If you do not know how to create queries in the data Mining check the introduction to data mining in the predict the future section.
To delete the Data Mining Model with XMLA right click on the Data Mining Model and Select the Script Mining Model as >Delete to>New query editor Window.
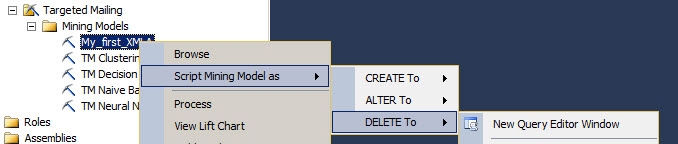
As you can see, the XMLA is very simple. You have a delete action, an object tag and in the object tag, the Database ID, the Mining Structure ID and finally the Mining Model ID.
Conclusion
You may ask yourself why do I need to know XMLA if I have a nice and friendly user interface. The answer is to automate process. In the next chapters, we will use tools like Powershell, the SQL Agent jobs and SQL Server Integration Services to automate the Data Mining Processes.
In this lesson, we learned how to generate XMLA scripts using the SQL Server Management Studio, how to modify and create a new mining model based in an existing one. How to execute an XMLA to process a Mining Model and finally, how to delete that model.