ETL is truly a continuing journey of exploration.
It is often the case that source databases are, for whatever reason, inaccessible as SQL databases so surrogates have to be used. These can be files of various sorts, scheduled and exported. Today's tale relates to that most verbose of formats - XML.
As with so many ETL projects, the scope and complexity of the ETL phase has been understated, and so quick-and-dirty - that is to say - Spackle - is the order of the day.
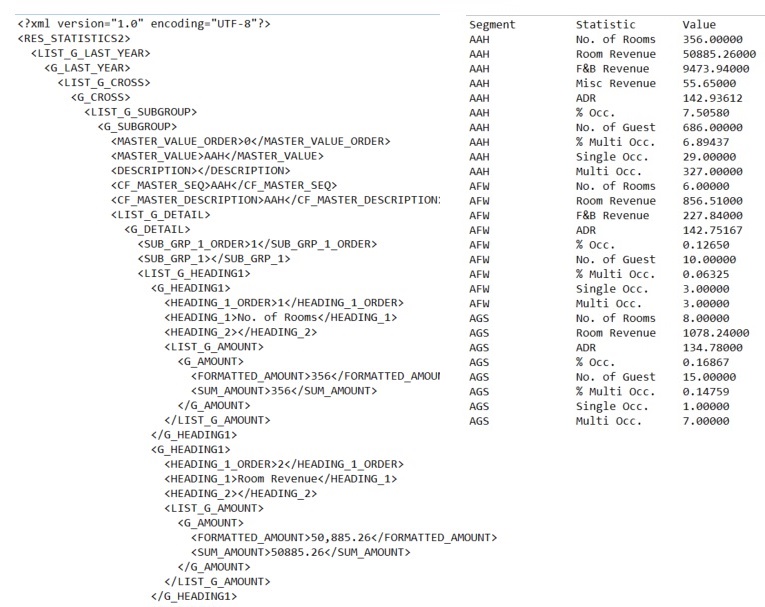
The XML in question is not a pure database extract: it is an XML representation of a cross-tab Statistical report from a hotel reservation system. What is required is a simple list of the various statistics, their values, and the grouping to which each belongs. These rows can then be furher shaped and finally inserted to a standard star-schema warehouse.
Attempt 1 used SSIS for the XML file read, via an XML Data Source. This resulted in a formidable XSD file to describe the source file contents and assign datatypes. But as should be obvious from the xml, most of the document object model is quite irrelevant for our purposes. Prime example - Column Numbers, which don't pass the 'So What?' test for the warehouse destination.
In another of those real-world sidebars, the entire reservation system is under review. This extract may have a life only of months, so making this whole exercise as simple as possible is an important consideration. It may have to be rejigged for quite another data source - very possibly non-XML - once a replacement system is decided upon.
Recalling that this is an xml rendition of a report, one has to ask - what if a user in the source application tweaks the report definition? The XSD is likely to be rendered instantly obselete, but as it is embedded deep within an SSIS Control Flow, this would cause the task to fail. Failed tasks mean SSIS changes and re-deployment - not a very maintainable proposition. So XML Data Source plus XSD definitions won't do.
Attempt 2, results from a decision to use pure SQL and the old standby: OPENROWSET - which has been well covered in these very forums (or, for the purist, fora), for two reasons.
1 - as pure SQL, the script can be wrapped up as a stored procedure on the BI server, and thus quickly amended to suit any application report definition changes. As many such reports need to be ETL'ed, the procedure can be invoked by a simple SSIS Filewatcher task (Konesans or similar) and the relevant filename passed to it.
2 - as SSIS is so monstrously picky about datatypes, a 'With Result Sets' invocation of the procedure will allow explicit datatyping at the point of extraction - always the best in my experience.
Attempt 2 looks 'down' the XML tree, so the initial Nodes definition in the Cross Apply is'//RES_STATISTICS2/LIST_G_LAST_YEAR/G_LAST_YEAR/LIST_G_CROSS/G_CROSS/LIST_G_SUBGROUP/G_SUBGROUP/LIST_G_DETAIL/G_DETAIL/LIST_G_HEADING1/G_HEADING1/LIST_G_AMOUNT/G_AMOUNT'
This slavishly follows the tree top-down but will, clearly, suffer if that report definition is changed (number of layers, names of elements), plus is a rather formidable string. The procedure does have the advantage of running, but a little optimising seems possible.
Attempt 3 simplifies the Cross Apply nodes to the rather simpler './/G_AMOUNT' and mirabile dictu, the script still works. Job done. On to the next challenge.
I explain this as follows. It is actually wonderfully simple, and I hope it is for readers too:
- Find the lowest/innermost element in the document tree, at which required data resides. In this case, it is the SUM_AMOUNT, which has a parent G_AMOUNT.
- Point the Cross Apply nodes at G_AMOUNT parent - this determines the number of rows in the output. './/G_AMOUNT' means 'ignore all of the parents, just get all G_AMOUNT's'
- The Select from the PackageSource CTE can then acquire the other values, by stepping up or down a known number of parents/children from G_AMOUNT - 1 click down for SUM_AMOUNT, 2 clicks up for HEADING_1, 6 clicks up for MASTER_VALUE
- This bottom-up 'layer counting' approach completely ignores intermediate element names: it avoids the need to quote them at all.
- If the source application report definition changes, the procedure can be easily maintained, either as to element names needed for the output columns, or as to the number of parents back up (or children down) the document tree to climb for each required value. This can be achieved by just looking at the XML.
- The procedure is executed 'with result sets' to be absolutely sure of datatypes. The procedure is itself a dynamic SQL execution, because, for reasons best known to the authors, a BULK command won't take a parameter as its file name.
- SSIS is thus likely not to be able to 'sniff out' datatypes for its dataflows otherwise. And we have all had experience of letting SSIS decide these for itself.....best not to.
Caveat:
The source files, being renditions of summary reports, are inherently small. This method may not scale well as file sizes increase. YMMV, as always
Images below: the xml (top of doc only) and the result set - exactly as required.