

Azure Databricks (documentation and user guide) was announced at Microsoft Connect, and with this post I’ll try to explain its use case. At a high level, think of it as a tool for curating and processing massive amounts of data and developing, training and deploying models on that data, and managing the whole workflow process throughout the project. It is for those who are comfortable with Apache Spark as it is 100% based on Spark and is extensible with support for Scala, Java, R, and Python alongside Spark SQL, GraphX, Streaming and Machine Learning Library (Mllib). It has built-in integration with Azure Blog Storage, Azure Data Lake Storage (ADLS), Azure SQL Data Warehouse (SQL DW), Cosmos DB, Azure Event Hub, Apache Kafka for HDInsight, and Power BI (see Spark Data Sources). Think of it as an alternative to HDInsight (HDI) and Azure Data Lake Analytics (ADLA).
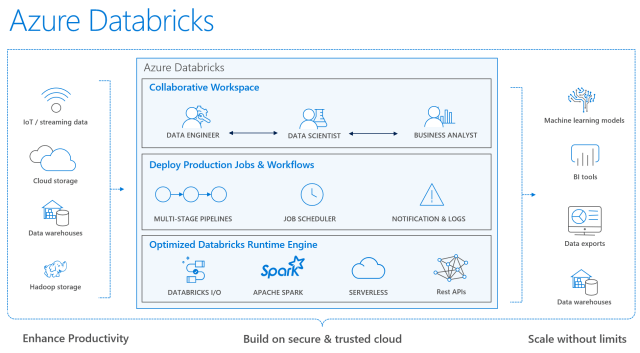
It differs from HDI in that HDI is a PaaS-like experience that allows working with many more OSS tools at a less expensive cost. Databricks advantage is it is a Software-as-a-Service-like experience (or Spark-as-a-service) that is easier to use, has native Azure AD integration (HDI security is via Apache Ranger and is Kerberos based), has auto-scaling and auto-termination (like a pause/resume), has a workflow scheduler, allows for real-time workspace collaboration, and has performance improvements over traditional Apache Spark. Note that all clusters within the same workspace share data among all of those clusters.
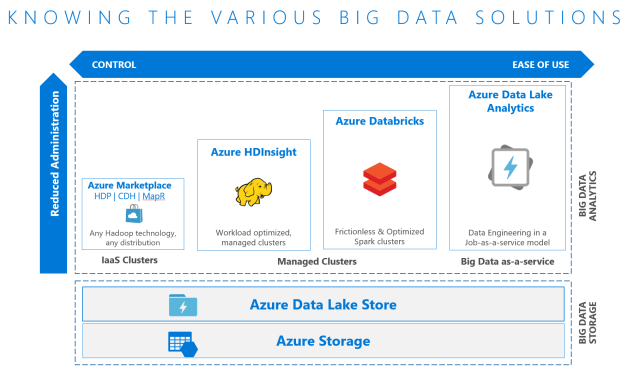
Also note with built-in integration to SQL DW it can write directly to SQL DW, as opposed to HDInsight which cannot and therefore more steps are required: when HDInsight processes data it must write it back to Blob Storage and then requires Azure Data Factory (ADF) to move the data from Blob Storage to SQL DW.
It is in limited public preview now: Sign up for the Azure Databricks limited preview
More info
Microsoft makes Databricks a first-party service on Azure
Microsoft Launches Preview of Azure Databricks
A technical overview of Azure Databricks
Microsoft Azure Debuts a ‘Spark-as-a-Service’

![]()
