

The traditional data warehouse has served us well for many years, but new trends are causing it to break in four different ways: data growth, fast query expectations from users, non-relational/unstructured data, and cloud-born data. How can you prevent this from happening? Enter the modern data warehouse, which is designed to support these new trends . It handles relational data as well as data in Hadoop, provides a way to easily interface with all these types of data through one query model, and can handle “big data” while providing very fast queries (via MPP).
So if you are currently running a SMP solution and are running into these new trends or think you will in the near future, you should learn all you can about the modern data warehouse. So read on as I try to explain it in more detail:
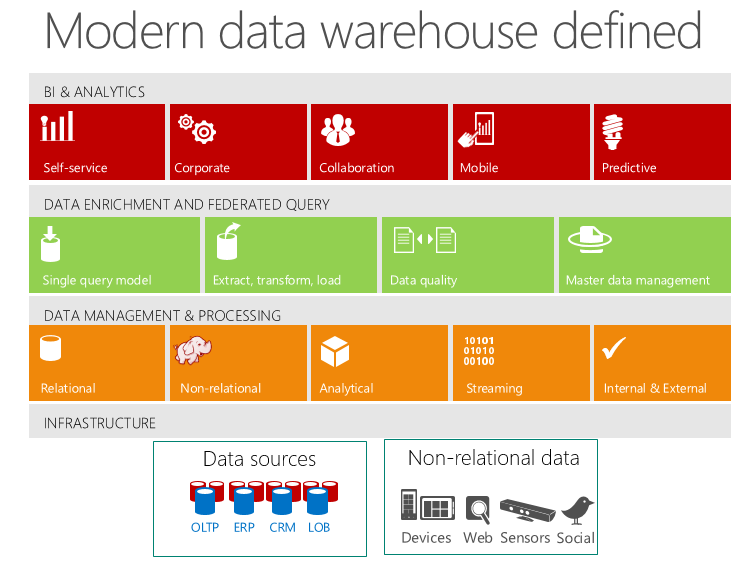
I like to think of “big data” as “all data”. It’s not so much the size of the data, but the fact you want to bring in data from all sources, whether that be traditional relational data from sources such as CRM or ERP, or non-relational data from things like web logs or Twitter data. Having diverse big data can result in diverse processing, which may require multiple platforms. To simplify things, IT should manage big data on as few data platforms as possible in order to minimize data movement and avoid data synchronization issues as well as avoid having lone silo’s of data. All of this will work against the “single version of the truth”, so a goal should be to consolidate all data onto one platform.
There will be exceptions to the one platform approach. As you expand into multiple types of analytics that have multiple big data structures, you will eventually create many types of data workloads. Because there is no single platform that runs all workloads equally well, most data warehouse and analytic systems are trending toward a multi-platform environment so that diverse data can find the best home based on storage, processing, and budget.
A result of the workload-centric approach is a move away from the single platform monolith of the enterprise data warehouse (EDW) toward a physically distributed data warehouse environment (DWE), also called the modern data warehouse (another term for this is Polyglot Persistence). A modern data warehouse consists of multiple data platform types, ranging from the traditional relational and multidimensional warehouse (and its satellite systems for data marts and ODSs) to new platforms such as data warehouse appliances, columnar RDBMSs, NoSQL databases, MapReduce tools, and HDFS. So a users’ portfolios of tools for BI/DW and related disciplines is fast-growing. While a multi-platform approach adds more complexity to the data warehouse environment, BI/DW professionals have always managed complex technology stacks successfully, and end-users love the high performance and solid information outcomes they get from workload-tuned platforms.
A unified data warehouse architecture helps IT cope with the growing complexity of their multi-platform environments. Some organizations are simplifying the data warehouse environment by acquiring vendor-built data platforms that have a unifying architecture that is easily deployed and has expandable appliance configurations, such as the Microsoft modern data warehouse appliance (see Parallel Data Warehouse (PDW) benefits made simple).
An integrated RDBMS/HDFS combo is an emerging architecture for the modern data warehouse. The trick is integrating RDBMS and HDFS so they work together optimally. For example, an emerging best practice among data warehouse professionals with Hadoop experience is to manage non-relational data in HDFS (i.e. creating a “data lake“) but process it and move the results (via queries, ETL, or PolyBase) to RDBMSs (elsewhere in the data warehouse architecture) that are more conducive to SQL-based analytics, providing ease-of-access and speed (since Hadoop is batch oriented and not real-time – see Hadoop and Data Warehouses). So HDFS serves as a massive data staging area for the data warehouse (see Hadoop and Data Warehouses). This exposes the big benefit of Hadoop in that it allows you to store and explore raw data where the actionable insights are not yet discovered, and it is not practical to do up-front data modeling.
This requires new interfaces and interoperability between HDFS and RDBMSs, and it requires integration at the semantic layer, in which all data—even multi-structured, file-based data in Hadoop—looks relational. The secret sauce that unifies the RDBMS/HDFS architecture is a single query model which enables distributed queries based on standard SQL to simultaneously access data in the warehouse, HDFS, and elsewhere without preprocessing data to remodel or relocate it. Ideally it should also push down processing of the queries to the remote HDFS clusters. This is exactly the problem that newer technologies such as PolyBase solve.
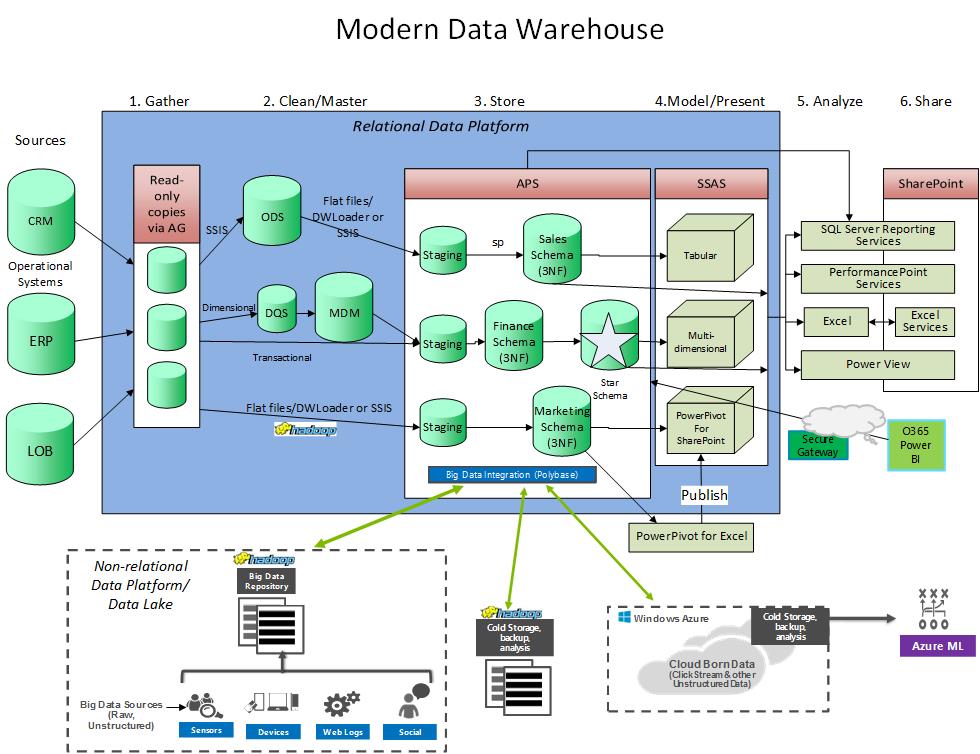
A data warehouse appliance will give you the pre-integration and optimization of the components that make up the multi-platform data warehouse. An appliance includes hardware, software, storage, and networking components, pre-integrated and optimized for warehousing and analytics. Appliances have always been designed and optimized for complex queries against very large data sets, now they must also be optimized for the access and query of diverse types of big data. As mentioned before, Microsoft has such an appliance (see Parallel Data Warehouse (PDW) benefits made simple) that has the added benefit of being a MPP scale-out technology. The performance of an MPP appliance allows you to use one appliance for queries, as opposed to creating “work-arounds” to have acceptable performance: multiple copies of data on multiple servers, OLAP servers, aggregate tables, data marts, temp tables, etc.
Clouds are emerging as platforms and architectural components for modern data warehouses. One way of simplifying the modern data warehouse environment is to outsource some or all of it, typically to a cloud-based DBMS, data warehouse, or analytics platform. User organizations are adopting a mix of cloud types (both public and private) and freely mixing them with traditional on-premises platforms. For many, the cloud is an important data management strategy due to its fluid allocation and reapportionment of virtualized system resources, which can immediately enhance the performance and scalability of a data warehouse (see Should you move your data to the cloud?). However, a cloud can also be an enhancement strategy that uses a hybrid architecture to future-proof data warehouse capabilities. To pursue this strategy, look for cloud-ready, on-premises data warehouse platforms that can integrate with cloud-based data and analytic functionality to extend data warehouse capabilities incrementally over time.
More info:
THE MODERN DATA WAREHOUSE: What Enterprises Must Have Today and What They’ll Need in the Future
Evolving Data Warehouse Architectures: From EDW to DWE
A Modern Data Warehouse Architecture: Part 1 – Add a Data Lake
Hadoop and a Modern Data Architecture
Video Hadoop: Beyond the Hype
Top Five Differences between Data Lakes and Data Warehouses
Data Access for Highly-Scalable Solutions: Using SQL, NoSQL, and Polyglot Persistence

![]()
