


There comes a time when you look at how something is being done and say, "Does it have to be that way?". SSIS has a few stock Data Flow Sources and they meet 90% of our needs. There is a situation where I have a single source of data, but I would like to have parallel paths of processing. This would be akin to the producer/consumer model. I would like to have a single producer and multiple consumers. The wrinkle is this data source has no way of managing itself, like a directory listing.
One of the most common problems I need to solve with SSIS, is importing files from one or more directories. There are potentially thousands of files across dozens of directories and sometimes having a single threaded process to pull them in takes longer than you'd like or might have. A very common technique, one that I use quite often, is to run through the directories and push the full path into a holding table. I can then use multiple SSIS packages or a single package with multiple Data Flow components to get the file information and import the file.
By placing the file location information into a SQL Server table I have pushed the responsibility of managing access of the source information onto SQL Server. I use this technique in my Invoice Archive process. This is all well and good when you have excess capacity on your SQL Server, but what if you don't?
I often see in SSIS blogs that to help with improving parallelism in your code or sorting data, push the data into temporary SQL Server tables and let SQL Server do some of the heavy lifting. Again, if you have excess capacity, this is a simple and often powerful technique. What if you don't? You can fall back onto a producer/consumer model and to do that, you use named pipes.
Fundamentals:
Without the use of SQL Server to manage the listing of files, I need to way to know what file is being processed, what files need to be processed, and to make sure there is no duplication of effort. To do this I will have a single Script Task that will manage what files are going to be worked on. This is called a producer. This will be the source of all work. There will be only one in this example. You can have multiple producers and I will show you how later in the series.
Now I need a process that will do the work itself. In our example, the work consists of importing the file into a sql server table and populating some ancillary tables based upon information about the file itself. This process is called a consumer. You can and should have, multiple consumers running as it takes far more time to process a unit of work than to dish it out. If you were to look at a sample SSIS package you would see a single producer and two consumers.
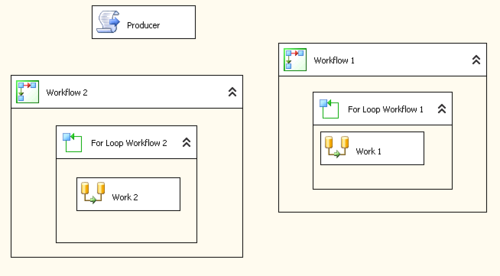
Now that I have my producer and consumers I need a way to shuttle information between them. Named pipes are a way to pass information between two processes. Think of like an electronic form of the mail tubes used at bank teller windows. You put a 'packet' of information into the tube and it gets sent from source to destination. In our situation the source is always the 'producer' and it gets sent in a one way direction to the 'consumer'. The producer can service multiple consumers, but can only SERVICE one consumer at a time.
That's it for today. Tomorrow I will go into the details of how to set up the producers,consumers, and the named pipes for communication.
