

With data lakes becoming very popular, a common question I have been hearing often from customers is, “Should I load structured/relational data into my data lake?”. I talked about this a while back in my blog post What is a data lake? and will expand on it in this blog. Melissa Coates also talked about this recently, and I used her graphic below to illustrate:
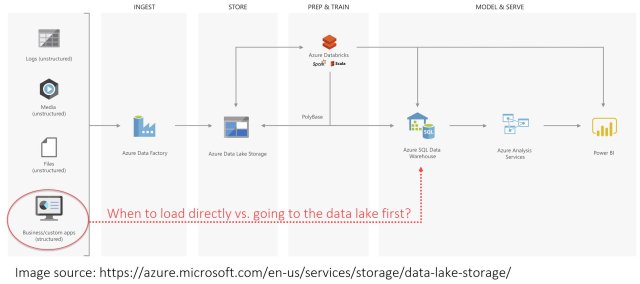
I would not say it’s common place to load structured data into the data lake, but I do see it frequently.
In most cases it is not necessary to first copy relational source data into the data lake and then into the data warehouse, especially when keeping in mind the effort to migrate existing ETL jobs that are already copying source data into the data warehouse, but there are some good uses cases to do just that:
- Wanting to offload the data refinement to the data lake (usually Hadoop), so the processing and space on the enterprise data warehouse (EDW) is reduced, and you avoid clashing with people running queries/reports on the EDW
- Wanting to use some Hadoop technologies/tools to refine/filter data that do the refinement quicker/better than your EDW
- It can ingest large files quickly and provide data redundancy
- ELT jobs on EDW are taking too long because of increasing data volumes and increasing rate of ingesting (velocity), so offload some of them to the Hadoop data lake
- The data lake is a good place for data that you “might” use down the road. You can land it in the data lake and have users use SQL via Polybase to look at the data and determine if it has value. Note PolyBase allows end-users to query data in a data lake using regular SQL, so they are not required to learn any Hadoop-related technologies. PolyBase even allows the end-user to use SQL, or any reporting tool that uses SQL, to join data in a relational database with data in a Hadoop cluster
- Have a backup of the raw data in case you need to load it again due to an ETL error (and not have to go back to the source). You can keep a long history of raw data
- A power user/data scientist wants to make use of the structured data in the data lake (usually combining it with non-relational data)
- As a quicker way to load data into Azure SQL Data Warehouse via PolyBase from the data lake (which is usually much faster than using SSIS to copy from the source to Azure SQL Data Warehouse)
You will have to balance these benefits with the extra work required to export data from a relational source into a format such as CSV, then copied to the data lake (where it can be cleaned with a tool such as Databricks and then copied into the relational EDW such as Azure SQL Data Warehouse). Keep in mind for the relational data that is moved to the data lake you will lose valuable metadata for that data such as data types, constraints, foreign keys, etc.
I have seen some customers with relational data who bypassed the data lake and had the source systems copy data directly to the EDW (i.e. Azure SQL Data Warehouse) using SSIS/ADF, but still wanted all data in the data lake so they used Databricks to copy the data warehouse structures into the data lake using the SQL Data Warehouse Spark Connector. In these cases, the customers used the data lake for static data (i.e. web logs, IOT data streams and older ERP data that will not change) and managed non-static data directly in the EDW, as moving data updates through the data lake to the EDW adds a layer of complexity they wanted to avoid.
I have also seen cases when the customer moved EDW data to Hadoop, refined it, and moved it back to the EDW which gave the benefit of offloading the processing and/or when they needed to use Hadoop tools.
A common practice when I see customers migrate an on-prem EDW solution to the cloud is they don’t use the data lake for their current sources (which are usually all structured data), but will use it for all new sources (which are usually mostly unstructured data). However, they like the benefits listed above and will slowly modify most of their ETL packages (usually SSIS) to use the data lake, in some cases replacing SSIS with Azure Data Factory.
More info:
When Should We Load Relational Data to a Data Lake?

![]()
